
สรุปข่าว AI: Google เปิดตัว Gemma 4 โมเดลเปิดอันดับ 1 สหรัฐฯ, Anthropic ค้นพบ 'อารมณ์' ใน Claude
Google DeepMind เปิดตัว Gemma 4 — โมเดลโอเพนซอร์สที่ทรงพลังที่สุดของ Google
Google DeepMind ปล่อยโมเดล Gemma 4 อย่างเป็นทางการ ถือเป็นการอัปเกรดครั้งใหญ่ที่สุดของตระกูล Gemma โมเดลหลักคือรุ่น 31B Dense ควบคู่กับ 26B MoE (A4B) ที่ active เพียง ~4B พารามิเตอร์ พร้อม Edge models E4B และ E2B สำหรับมือถือ/IoT ทั้งหมดภายใต้ Apache 2.0 รองรับ context 256K token
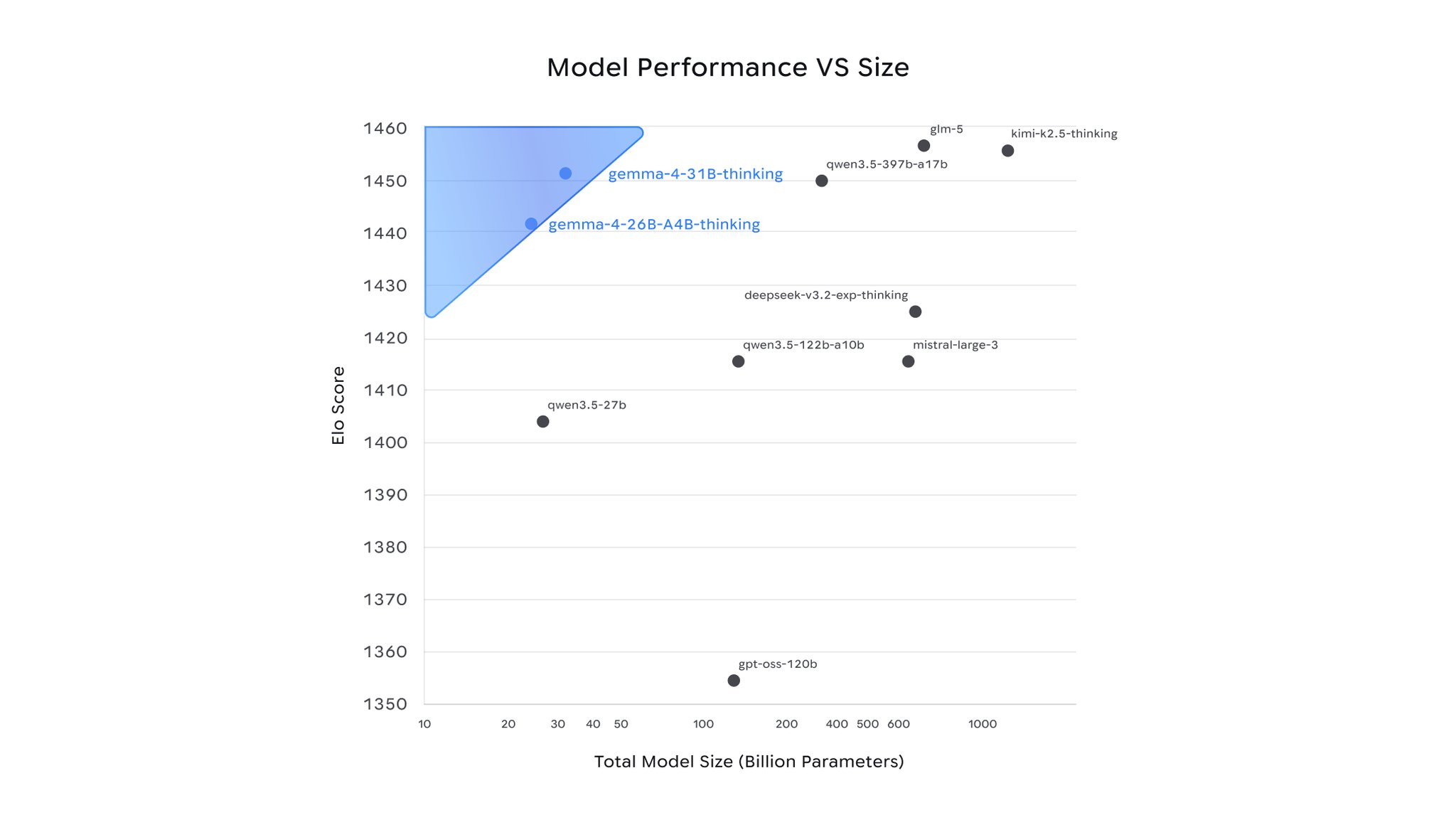
เป็น Multimodal แบบ Native — รองรับข้อความ ภาพ เสียง, Function Calling, Structured JSON, OCR, วิเคราะห์กราฟ, วิดีโอ และ speech recognition ผล Arena: อันดับ 3 โมเดลโอเพนซอร์ส, อันดับ 27 รวมทั้งหมด GPQA Diamond: 85.7% วางตำแหน่งเป็น โมเดลโอเพนซอร์สจากสหรัฐฯ อันดับ 1 Gemma 3 เคยมียอดดาวน์โหลด 400 ล้านครั้ง และ 100,000 เวอร์ชัน
สถาปัตยกรรม Gemma 4 — นวัตกรรมที่น่าจับตา
ใช้ Hybrid Attention อัตราส่วน Local:Global 5:1, Group Query Attention (GQA), Per-Layer Embeddings (PLE) และ KV-Cache Sharing มี Softcapping, Partial-dimension RoPE, Sliding Window 512/1024 token, QK/V Normalization และ Native Aspect-Ratio สำหรับ Vision
สิ่งที่น่าสนใจเป็นพิเศษคือ MoE ของ Gemma 4 แตกต่างจาก DeepSeek/Qwen — MoE Blocks เป็นชั้นแยกควบคู่ MLP ปกติ ไม่ได้แทนที่ MLP ทั้งหมด
Ecosystem พร้อมตั้งแต่วันแรก — 300 tok/s บน M2 Ultra
Day-0 support: llama.cpp (Native + WebUI + MCP), Ollama v0.20+, vLLM, LM Studio, Transformers/transformers.js ผลทดสอบ llama.cpp บน M2 Ultra: Gemma 4 26B A4B Q8_0 ที่ 300 tok/s รันในเบราว์เซอร์ผ่าน WebGPU ได้
เร่ง Training — Axolotl 15x เร็วขึ้น, GRPO Async 58% เร็วขึ้น
Axolotl v0.16.x รองรับ Gemma 4: MoE+LoRA เร็วขึ้น 15 เท่า, ลด memory 40 เท่า GRPO Async เร็วขึ้น 58%
CUDA Kernel ใหม่สำหรับ Linear Attention
Linear Attention มีความซับซ้อน O(n) แทน O(n²) ของ Standard Attention จัดการ Sequence ยาวได้มีประสิทธิภาพกว่ามาก CUDA Kernel ใหม่ช่วยให้ทดลองสถาปัตยกรรมใหม่ ๆ ได้เร็วขึ้น
Turbopuffer เพิ่ม Multiple Vector Columns
เก็บเวกเตอร์หลายชุดที่มีมิติ ประเภท และดัชนีต่างกันในเอกสารเดียว เหมาะสำหรับ cross-modal search เก็บทั้ง text + image embedding ด้วยกัน
LiteParse และ LlamaIndex Extract v2
LiteParse: โอเพนซอร์ส spatial text parser พร้อม bounding boxes และ audit trail LlamaIndex Extract v2: simplified tiers, saved configs, pre-extraction parsing
Agent Infrastructure — โมเดลโอเพนซอร์สเป็นฐานราก
Gemma 4 ถูกวางตำแหน่งเป็นโมเดลในอุดมคติสำหรับ Local Agent Stack ทำงานกับ OpenClaw, Hermes, Pi, opencode แนวคิด Model-Harness Training Loop: โมเดลโอเพนซอร์ส + tracing + fine-tuning = proprietary moat แม้เริ่มจากโมเดลเดียวกัน
Hermes Agent — Enzyme Plugin ค้นหาใน 8ms
Memory integrations แบบ pluggable ใหม่ "Enzyme" local semantic index ที่ค้นหาได้ใน 8 มิลลิวินาทีต่อ query Agent สามารถดึงข้อมูลจากความทรงจำได้แทบทันทีทันใด
LangSmith: Azure ดึง Traffic จาก OpenAI — 8% เป็น 29% ใน 10 สัปดาห์
สัดส่วน Traffic ผ่าน Azure เพิ่มจาก 8% เป็น 29% ใน 10 สัปดาห์ จาก Agent Runs 6,700 ล้านครั้งที่ถูกติดตาม Enterprise Governance ขับเคลื่อนการตัดสินใจ routing ไม่ใช่แค่เรื่องเทคนิค
Self-Healing Agents — Agent ที่ซ่อมแซมตัวเองได้
Observability + feedback loops สำหรับ GTM agent optimization เมื่อ Agent ทำงานผิดพลาด ระบบเก็บข้อมูลแล้วปรับ prompt, routing, parameters อัตโนมัติ สำคัญสำหรับ Scale AI ขององค์กร
Anthropic ค้นพบ "อารมณ์" ใน Claude — ส่งผลต่อพฤติกรรมโมเดล
ค้นพบ "Emotion Concept Representations" ภายใน Claude เพิ่มเวกเตอร์ "desperate" → เพิ่มพฤติกรรมการโกง เพิ่ม "calm" → ลดการโกง มีนัยสำคัญต่อ AI Safety — สถานะภายในโมเดลส่งผลต่อพฤติกรรม ไม่ใช่แค่ guardrails ภายนอก เกิดข้อถกเถียงเรื่อง citation ในชุมชน interpretability
ChatGPT Voice บน Apple CarPlay
OpenAI เปิดให้ใช้ ChatGPT Voice Mode บน CarPlay สำหรับ iOS 26.4+ มีการคาดเดาว่า Apple อาจร่วมมือกับ DeepMind เพื่อยกเครื่อง Siri
Codex เปิดราคา Usage-Based
Codex เปิดราคาแบบ usage-based สำหรับ ChatGPT Business/Enterprise พร้อม promotional credits
Perplexity "Computer for Taxes" — AI Agent ช่วยทำภาษี
Agentic workflow สำหรับร่างและตรวจสอบ Federal Tax Return ตัวอย่างจับต้องได้ของ AI Agent ที่แก้ปัญหาจริง Perplexity ขยายจาก search engine สู่ agent platform
Allen Institute เผชิญกระแสลาออก + GPT-OSS คลุมเครือ
Allen Institute สูญเสียบุคลากรให้บริษัทใหญ่ สถานะ GPT-OSS ของ OpenAI ยังไม่ชัดเจน ทำให้ Gemma 4 ถูกวางตำแหน่งเป็น โมเดลโอเพนซอร์สอเมริกันอันดับ 1 ในช่วงที่การแข่งขัน open-source ระหว่างสหรัฐฯ กับจีนเข้มข้น
MoE กลายเป็นสถาปัตยกรรมมาตรฐาน
Gemma 4 A4B มีพารามิเตอร์ 26B แต่ใช้จริงเพียง ~4B ลดต้นทุนหลายเท่า ได้ความรู้เท่าโมเดลใหญ่ ใช้ทรัพยากรเท่าโมเดลเล็ก แนวทางที่ DeepSeek, Qwen และตอนนี้ Google ต่างเลือกใช้
Edge AI — AI ลงไปอยู่ในมือถือและ IoT
โมเดล E4B และ E2B สำหรับ Edge: สมาร์ทโฟน แท็บเล็ต IoT ทำงานได้โดยไม่ต้องเชื่อมอินเทอร์เน็ต Apache 2.0 ให้ผู้ผลิตอุปกรณ์ฝังในผลิตภัณฑ์ได้อย่างอิสระ
ภาพรวม — AI โอเพนซอร์สเข้าสู่ยุคใหม่
สัปดาห์นี้ถูกกำหนดโดย Gemma 4 ที่ยกระดับมาตรฐานโมเดลโอเพนซอร์ส ด้วย Multimodal ครบวงจร สถาปัตยกรรมที่คิดมาดี และ Ecosystem ที่พร้อมตั้งแต่วันแรก แนวโน้มหลัก 3 ประการ: โมเดลโอเพนซอร์สปิดช่องว่างกับโมเดลปิดอย่างรวดเร็ว (อันดับ 27 Arena), AI ย้ายจาก cloud สู่ edge (300 tok/s บน M2 Ultra, รันในเบราว์เซอร์ได้), Enterprise Governance ชี้ขาดตลาดองค์กร (Azure เพิ่มจาก 8% เป็น 29%)
งาน Interpretability ของ Anthropic เตือนว่า "อารมณ์" ภายในโมเดลส่งผลต่อพฤติกรรม — เวกเตอร์ desperate เพิ่มการโกง, calm ลดการโกง เป็นมิติใหม่ของ AI Safety ที่วงการไม่ควรมองข้าม
ข้อมูล ณ วันที่ 3 เมษายน 2569 — บทความนี้จัดทำขึ้นเพื่อให้ข้อมูลเท่านั้น ไม่ได้เป็นคำแนะนำด้านการลงทุนแต่อย่างใด