
ซอร์สโค้ด Claude Code หลุด 5 แสนบรรทัด — OpenAI ระดมทุน ARR 2.4 หมื่นล้านดอลลาร์
ซอร์สโค้ด Claude Code หลุดรั่วกว่า 5 แสนบรรทัด — Anthropic ตอบโต้ด้วย DMCA
เหตุการณ์สำคัญที่สุดในวงการ AI สัปดาห์นี้คือการที่ Claude Code เครื่องมือเขียนโค้ดบน CLI ของ Anthropic ถูกเปิดเผยซอร์สโค้ดจำนวนมหาศาลผ่าน source maps และ package contents ที่ถูกจัดส่งไปพร้อมกับตัวผลิตภัณฑ์ ปริมาณโค้ดที่หลุดออกมาอยู่ที่ราว 5 แสนบรรทัด ซึ่งเปิดเผยสถาปัตยกรรมภายในของ agent harness ทั้งระบบ — ไม่ใช่ model weights แต่เป็นชั้นซอฟต์แวร์ที่ห่อหุ้มและควบคุมการทำงานของโมเดล
หนึ่งใน fork สาธารณะบน GitHub พุ่งขึ้นไปถึง 32,600 stars และ 44,300 forks ก่อนที่ Anthropic จะเข้าดำเนินการทางกฎหมายผ่านกระบวนการ DMCA takedown การรั่วไหลครั้งนี้ไม่ได้เปิดเผย "สมอง" ของ AI แต่เปิดเผย "ร่างกาย" ของมัน — ระบบจัดการเครื่องมือ ระบบ memory ระบบ retry และโครงสร้างที่ทำให้ AI agent ทำงานได้อย่างมีประสิทธิภาพในสภาพแวดล้อมจริง สิ่งที่ชุมชนนักพัฒนาตื่นเต้นที่สุดไม่ใช่ตัวโมเดล แต่คือการได้เห็นว่าทีมวิศวกรระดับโลกออกแบบระบบรายล้อมโมเดลไว้อย่างไร ทั้งการจัดการ context การวางกลยุทธ์ retry และการแบ่งงานระหว่าง subagent การรั่วไหลครั้งนี้จึงถือเป็น "หลักสูตรวิศวกรรม AI" ที่ไม่มีใครตั้งใจเปิดสอน
สิ่งที่หลุดไม่ใช่โมเดล แต่คือ "Harness" — แล้วมันสำคัญอย่างไร
สิ่งที่หลุดมาร้ายแรงมากในทางธุรกิจ เพราะ harness คือตัวกำหนดว่า AI agent จะทำงานได้ดีแค่ไหน โมเดลที่ฉลาดที่สุดก็ทำอะไรไม่ได้มากถ้าขาด harness ที่ดี นักวิเคราะห์หลายรายแสดงความเห็นตรงกันว่า "harness คือตัวผลิตภัณฑ์" ไม่ใช่โมเดล ช่องว่างที่แท้จริงระหว่างเครื่องมือเขียนโค้ด AI ที่ดีกับที่ธรรมดาอยู่ที่คุณภาพของระบบที่ล้อมรอบโมเดล
ในมุมมองของวิศวกรซอฟต์แวร์ harness เปรียบได้กับระบบปฏิบัติการที่คอยจัดการทรัพยากรและประสานงานระหว่างส่วนต่างๆ ให้โมเดลทำงานได้อย่างราบรื่น ไม่ว่าจะเป็นการตัดสินใจว่าจะโหลดข้อมูลใดเข้า context การจัดลำดับความสำคัญของ tool calls หรือการจัดการกรณีที่ผลลัพธ์ไม่เป็นไปตามคาด ทั้งหมดนี้คือหน้าที่ของ harness ล้วนๆ บริษัทที่ลงทุนสร้าง harness ที่แข็งแกร่งจึงได้เปรียบในตลาด AI agent อย่างมีนัยสำคัญ แม้ว่าจะใช้โมเดลพื้นฐานเดียวกันกับคู่แข่ง ในอีกแง่หนึ่ง การที่โค้ด harness ถูกเปิดเผยออกมายังเปิดโอกาสให้ชุมชนนักพัฒนาทั่วโลกได้เรียนรู้จาก best practices ที่ทีม Anthropic สั่งสมมา และนำไปต่อยอดในโปรเจกต์ open-source ต่างๆ ซึ่งในระยะยาวอาจยิ่งเร่งการพัฒนาของ ecosystem AI agent ทั้งหมดให้เร็วขึ้นกว่าที่บริษัทใดบริษัทหนึ่งจะทำได้เพียงลำพัง
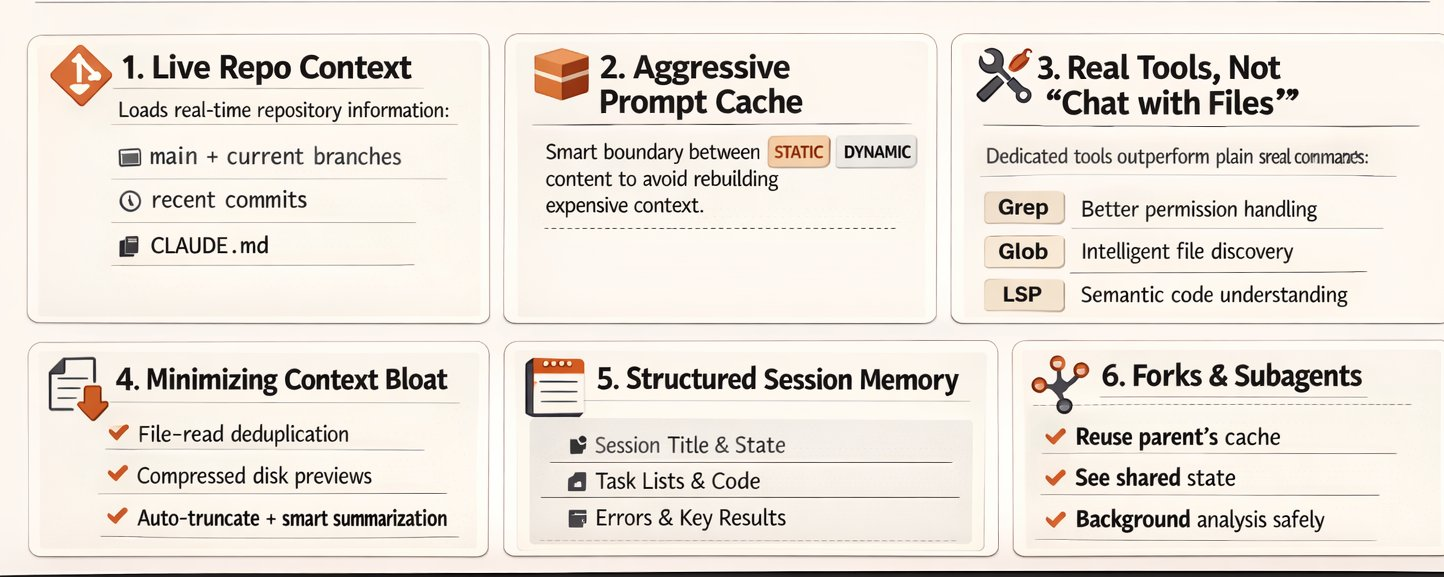
สถาปัตยกรรม 6 ชั้นที่ถูกเปิดเผย — จาก Sebastian Raschka
Sebastian Raschka สรุปสถาปัตยกรรม 6 ประการที่พบในซอร์สโค้ด:
- Repository State Integration — ดึง recent commits, git branch info เข้า context อัตโนมัติ
- Aggressive Cache Reuse — ลดการประมวลผลซ้ำ เพิ่มความเร็ว
- Custom Grep/Glob/LSP — เครื่องมือค้นหาไฟล์แบบ custom
- File Read Deduplication — กรองการอ่านไฟล์ซ้ำและ sampling ผลลัพธ์
- Structured Session Memory — memory แบบมีโครงสร้างข้าม session
- Subagent Capabilities — สร้าง agent ย่อยทำงานคู่ขนาน
การวิเคราะห์ของ Raschka ชี้ให้เห็นว่าแต่ละองค์ประกอบทั้ง 6 ไม่ได้เป็นแค่ฟีเจอร์เสริม แต่เป็น building block ที่ทำงานร่วมกัน เช่น Repository State Integration ทำให้โมเดลเข้าใจ context ของ codebase ได้โดยไม่ต้องอ่านไฟล์ทุกไฟล์ใหม่ทุกครั้ง ในขณะที่ Aggressive Cache Reuse ช่วยให้การส่ง context เดิมซ้ำๆ ไม่เสียค่าใช้จ่ายเพิ่มเติม ส่วน File Read Deduplication ป้องกันไม่ให้ context window เต็มด้วยข้อมูลซ้ำซ้อน สถาปัตยกรรมทั้ง 6 ชั้นนี้แสดงให้เห็นปรัชญาการออกแบบที่ให้ความสำคัญกับประสิทธิภาพทรัพยากรเป็นอันดับแรก
สถาปัตยกรรม Memory 3 ชั้น — หัวใจของ Agent ที่จำได้
ระบบ memory ออกแบบเป็น 3 ชั้น:
- Layer 1: MEMORY.md เป็นดัชนี — index ชี้ไปยังไฟล์ความรู้อื่น ๆ
- Layer 2: Topic Files แบบ On-Demand — โหลดเฉพาะเมื่อจำเป็น
- Layer 3: Session Transcripts — บันทึกสนทนาค้นหาย้อนกลับได้
โหมด "autoDream" ทำหน้าที่ merge ข้อมูลซ้ำ ลบข้อมูลขัดแย้ง ตัดข้อมูลไม่จำเป็น จัดระเบียบ memory การวิเคราะห์จาก mem0 พบ 8 ขั้นตอน memory processing และ 5 กลยุทธ์ Compaction ความชาญฉลาดของระบบ 3 ชั้นนี้อยู่ที่การแยกข้อมูลตามความถี่การใช้งาน Layer 1 ที่เป็น MEMORY.md ทำหน้าที่เป็น "สารบัญ" ขนาดเล็กที่โหลดเสมอ ในขณะที่ Topic Files ใน Layer 2 จะถูกดึงเข้ามาเฉพาะเมื่อ agent ต้องการข้อมูลในหัวข้อนั้นๆ และ Session Transcripts ใน Layer 3 เปิดให้ agent สามารถ "จดจำ" บทสนทนาที่ผ่านมาได้อย่างมีระเบียบ ผลลัพธ์คือระบบที่ใช้ context window อย่างประหยัดและมีประสิทธิภาพสูงสุด
Subagent กับ Prompt Caching — "Parallelism แทบจะฟรี"
Claude Code ใช้ KV cache สร้างโมเดล fork-join สำหรับ subagent — แยกงาน ทำคู่ขนาน รวมผลลัพธ์ โดยแต่ละ subagent มี context เต็มไม่ต้องทำงานซ้ำ "Parallelism is basically free" เพราะ subagent ใช้ cache ที่มีอยู่แทนส่ง context ใหม่ทั้งหมด
กลไกนี้ถือเป็นหนึ่งในนวัตกรรมที่ทรงพลังที่สุดในซอร์สโค้ดที่หลุดออกมา ในระบบ AI agent ทั่วไป การสร้าง subagent หลายตัวพร้อมกันมีต้นทุนสูงเพราะต้องส่ง context ขนาดใหญ่ซ้ำๆ ไปยังแต่ละ subagent แต่ด้วยการใช้ KV cache ร่วมกัน ต้นทุนส่วนใหญ่เกิดขึ้นเพียงครั้งเดียว subagent ที่เกิดใหม่แต่ละตัวจะ "สืบทอด" ความเข้าใจเดิมได้ทันที โดยไม่ต้องประมวลผล context ซ้ำ โมเดล fork-join ที่ Claude Code ใช้จึงสามารถขยายขนาดการทำงานคู่ขนานได้โดยไม่เพิ่มต้นทุนอย่างมีนัย นี่คือเหตุผลที่ทีมวิศวกรหลายคนมองว่านี่คือส่วนที่ "ลับที่สุด" ของระบบ ในทางปฏิบัติ ความสามารถนี้เปิดให้ Claude Code ทำงานที่ต้องการการค้นหาและวิเคราะห์ไฟล์หลายสิบหรือหลายร้อยไฟล์พร้อมกันได้ในเวลาที่สั้นกว่าการทำงานแบบลำดับขั้นตอนอย่างมีนัยสำคัญ ซึ่งเป็นสิ่งที่นักพัฒนาที่ใช้งานสังเกตได้ในชีวิตประจำวัน
ระบบ Permission 5 ระดับ — ควบคุมสิ่งที่ Agent ทำได้
ระบบ permission 5 ระดับ ควบคุมว่า agent เข้าถึงเครื่องมือและฟังก์ชันใดได้บ้าง ป้องกันการลบไฟล์ push production หรือเข้าถึงข้อมูล sensitive ระบบนี้บ่งชี้แนวคิด AI safety ในระดับ application layer
การออกแบบ permission เป็น 5 ระดับแทนการใช้แค่ระบบ on/off แบบง่ายๆ ช่วยให้สามารถกำหนดสิทธิ์ได้อย่างละเอียดตาม use case ตัวอย่างเช่น agent ระดับต่ำอาจอ่านไฟล์ได้แต่เขียนไม่ได้ ระดับกลางสามารถแก้ไขไฟล์ในโฟลเดอร์ที่กำหนดได้ และระดับสูงสุดมีสิทธิ์เข้าถึงการ deploy หรือเรียก API ภายนอก การแบ่งระดับเช่นนี้ทำให้สามารถให้ agent ทำงานอัตโนมัติในขอบเขตที่กำหนดได้อย่างปลอดภัย โดยไม่เสี่ยงต่อการทำลายระบบหรือรั่วไหลข้อมูลสำคัญ ระบบ permission เช่นนี้สอดคล้องกับหลักการ least-privilege ที่เป็นมาตรฐานทองในวงการความปลอดภัยซอฟต์แวร์
Plan Mode 2 แบบ และ Resilience/Retry
พบ planning mode 2 รูปแบบ รวมถึง EnterPlanModeTool และ ExitPlanModeV2Tool ที่ผ่านการพัฒนาอย่างน้อย 2 version Claude Code มีระบบ error taxonomy ที่แบ่งข้อผิดพลาดเป็นหมวดหมู่พร้อมกลยุทธ์จัดการที่แตกต่างกัน รวมถึง model-specific prompt branching
การที่โค้ดมีทั้ง EnterPlanModeTool และ ExitPlanModeV2Tool ที่ระบุเลข version ชัดเจน บ่งชี้ว่าทีมพัฒนาได้ผ่านการ iterate ระบบวางแผนมาแล้วอย่างน้อย 2 รอบ Plan Mode แรกน่าจะเป็นแนวทางที่ agent วางแผนทั้งหมดก่อนลงมือทำ ส่วน V2 อาจเป็นการวางแผนแบบ rolling ที่ปรับได้ระหว่างการทำงาน ระบบ error taxonomy ที่แบ่งข้อผิดพลาดเป็นหมวดหมู่ช่วยให้ agent เลือกกลยุทธ์ retry ที่เหมาะสมกับแต่ละประเภทปัญหา แทนที่จะ retry แบบเดิมซ้ำๆ ขณะที่ model-specific prompt branching อนุญาตให้ harness ปรับ prompt style ตามโมเดลที่ใช้งานอยู่ ซึ่งเพิ่มความยืดหยุ่นในการรองรับโมเดลหลายตัว
ระบบเครื่องมือ — ไม่ถึง 20 เครื่องมือเริ่มต้นจาก 60+ ที่มี
Claude Code มีเครื่องมือกว่า 60+ แต่เปิดใช้เริ่มต้น ไม่ถึง 20 ใช้ dynamic tool selection ตามบริบท เครื่องมือที่ถูกระบุชื่อ ได้แก่ AgentTool, BashTool, FileReadTool, FileEditTool, FileWriteTool, NotebookEditTool, WebFetchTool, WebSearchTool, TodoWriteTool, TaskStopTool, TaskOutputTool, AskUserQuestionTool, SkillTool, EnterPlanModeTool, ExitPlanModeV2Tool, SendMessageTool, BriefTool, ListMcpResourcesTool, ReadMcpResourceTool
การที่ระบบมีเครื่องมือถึง 60+ แต่เปิดใช้เพียงไม่ถึง 20 ตัวเป็นค่าเริ่มต้น แสดงถึงการออกแบบที่เน้น context efficiency อย่างสูง เพราะการส่ง tool definition จำนวนมากเข้า context window ทุกครั้งจะเปลืองพื้นที่ที่ควรใช้สำหรับข้อมูลที่เกี่ยวข้องกับงานจริง ระบบ dynamic tool selection ทำหน้าที่วิเคราะห์งานที่ได้รับมอบหมายและเลือกเฉพาะเครื่องมือที่จำเป็นเข้ามาใน context ทำให้โมเดลสามารถโฟกัสกับเครื่องมือที่เกี่ยวข้องได้ทันที แนวทางนี้ยังช่วยลดโอกาสที่โมเดลจะ "หลงทาง" ไปกับเครื่องมือที่ไม่เกี่ยวข้องกับงานปัจจุบัน
ฟีเจอร์ลับที่ยังไม่เปิดตัว — ULTRAPLAN, KAIROS และอื่น ๆ
ซอร์สโค้ดเผย employee-only access gates และฟีเจอร์ที่ยังไม่เปิดตัว:
- ULTRAPLAN — ระบบวางแผนขั้นสูง
- KAIROS — ระบบที่เกี่ยวข้องกับเวลา
- MAGIC DOCS — ระบบเอกสารภายใน
- Employee TUI — Text UI สำหรับพนักงาน
- Capybara/Mythos v8 — อ้างอิงโมเดลภายใน
- /buddy — ฟีเจอร์ April Fools
- WTF counter — ตัวนับใน codebase
- "Claude Codex" — ชื่อรวม Claude + Codex
การค้นพบชื่อโค้ดภายในเหล่านี้จุดประกายการคาดเดาในวงกว้าง ULTRAPLAN ซึ่งดูเหมือนจะเป็นระบบ planning รุ่นถัดไปที่ซับซ้อนกว่า Plan Mode ปัจจุบัน อาจเป็นสัญญาณว่า Anthropic กำลังพัฒนาความสามารถด้านการวางแผนระยะยาวอยู่ ส่วน KAIROS ที่น่าจะเกี่ยวข้องกับการจัดการเวลาและกำหนดการ อาจเป็นระบบที่ช่วยให้ agent สามารถทำงานแบบ scheduled หรือ time-aware ได้ การพบ Capybara/Mythos v8 ที่อ้างอิงโมเดลภายในยังบ่งชี้ว่ามีโมเดลรุ่นทดลองที่ยังไม่เปิดเผยต่อสาธารณะอยู่ในระบบ ทั้งหมดนี้เปิดม่านให้เห็นว่าทีม Anthropic กำลังพัฒนาอะไรอยู่ใน pipeline อย่างน้อยบางส่วน
ภัยความปลอดภัย — npm Package Squatting
ผู้ไม่ประสงค์ดีสร้าง npm packages ปลอม ชื่อ "color-diff-napi" และ "modifiers-napi" เพื่อโจมตีนักพัฒนาที่พยายาม compile โค้ดที่หลุด เป็น second-order leak effect ที่ exploit surface ขยายเกินตัวโค้ดไปถึงพฤติกรรมของคนที่พยายามใช้โค้ด
กรณี package squatting นี้คือตัวอย่างคลาสสิกของการโจมตีแบบ supply chain attack ที่อาศัยความอยากรู้และความไม่ระวังของนักพัฒนา เมื่อซอร์สโค้ดหลุดออกมา นักพัฒนาจำนวนมากพยายาม clone repository และ build โปรแกรมเอง ทำให้กลายเป็นเป้าหมายที่ชัดเจนสำหรับผู้โจมตีที่จดทะเบียน package ชื่อเดียวกับ dependency ในโค้ดที่หลุดล่วงหน้า หากนักพัฒนาใช้ package ปลอมเหล่านี้ก็อาจถูกขโมย credentials หรือถูกติดตั้ง malware ได้ นักพัฒนาที่สนใจศึกษาโค้ดที่หลุดควรตรวจสอบ package registry ทุกรายการอย่างละเอียดก่อน install เหตุการณ์นี้ยังเน้นย้ำว่าในยุค AI ที่นักพัฒนามักเร่งรีบ โอกาสสำหรับการโจมตีแบบ second-order มีมากขึ้นกว่าที่เคย ผู้ไม่ประสงค์ดีไม่จำเป็นต้อง hack โดยตรง เพียงแค่วางกับดักและรอให้เหยื่อเดินเข้ามาเองก็เพียงพอ
Harness Engineering คือ Competitive Moat ที่แท้จริง
คุณภาพระดับ production มาจาก: dynamic tool selection, memory architecture, evaluation/review loops, error taxonomy/retries, model-specific prompt branching, integration กับ GitHub/Slack และ persistent autonomy modes วิศวกรหลายคนที่เคยมองว่า "wrapper" ไม่มีคุณค่าต้องเปลี่ยนความคิด — wrapper/harness engineering เป็นงานที่ยากและซับซ้อน
ก่อนหน้านี้ นักวิจารณ์หลายคนในวงการ AI มักโต้แย้งว่า "wrapper บริษัท" ที่สร้างผลิตภัณฑ์บนโมเดล foundational ไม่มี moat ที่แท้จริง เพราะใครก็สามารถ call API เดียวกันได้ แต่ซอร์สโค้ดที่หลุดพิสูจน์ให้เห็นว่าความคิดนั้นผิดพลาดอย่างมีนัย ระบบ harness ที่ดีต้องลงทุนเวลาพัฒนาอย่างมหาศาลในการออกแบบ evaluation loops ที่ตรวจจับข้อผิดพลาดได้เร็ว การสร้าง memory ที่ persistent และ reliable ข้าม session และการ integrate กับ ecosystem เครื่องมือต่างๆ ที่นักพัฒนาใช้งานจริง ทั้งหมดนี้คือ competitive moat ที่คัดลอกได้ยากกว่าที่คิด ยิ่งไปกว่านั้น การรักษา moat ในเชิง harness ยังต้องการ feedback loop ที่ต่อเนื่องจากผู้ใช้จริง เพื่อระบุว่า parameter ใดควรปรับ และ edge case ใดที่เกิดบ่อยในการใช้งานจริงซึ่งไม่ปรากฏในการทดสอบ synthetic ข้อมูลชุดนี้สะสมได้จากการมีฐานผู้ใช้จำนวนมากเท่านั้น ไม่สามารถ shortcut ผ่านการอ่านซอร์สโค้ดที่หลุดออกมาได้
ผลกระทบเชิงแข่งขัน — รอบการพัฒนาถูกบีบอัด
คู่แข่งสามารถ copy patterns, benchmark harness decisions, port ข้ามภาษา, ระบุจุดอ่อน และสร้าง open equivalents ได้เร็วขึ้น "ทุก model lab และ AI coding startup จะศึกษาโค้ดนี้และปิดช่องว่าง" Fork หนึ่งแปลงเป็น Python เพื่อหลีกเลี่ยง DMCA แสดงว่าชุมชนเคลื่อนตัวเร็วมาก
ในอดีต บริษัท AI ที่ลงทุนพัฒนา harness มาก่อนมักได้รับประโยชน์จากช่วงเวลาแห่งความได้เปรียบที่ยาวนานพอสมควร เพราะคู่แข่งต้องเริ่มต้นออกแบบจากศูนย์ แต่หลังจากการรั่วไหลครั้งนี้ ช่วงเวลาดังกล่าวหดสั้นลงอย่างมาก startup ที่มีทีมวิศวกรรมที่แข็งแกร่งสามารถศึกษาสถาปัตยกรรมที่ถูกพิสูจน์แล้วว่าทำงานได้ดีและนำไปปรับใช้ได้ในเวลาสัปดาห์แทนที่จะเป็นเดือนหรือปี การแปลงโค้ดเป็น Python ยังทำให้เข้าถึงได้ง่ายขึ้นอีก เพราะ ecosystem ของ Python ในวงการ AI นั้นใหญ่กว่า TypeScript อย่างมาก
Hermes Agent เป็นตัวเปรียบเทียบ — "สูตรลับ" อาจไม่ลับ
ผู้วิเคราะห์สรุปว่า "สูตรลับ" ของ Claude Code สามารถทำซ้ำได้จาก open-source components Hermes Agent ทำหลายอย่างเหมือนกัน ความแตกต่างจริงๆ คือ คุณภาพ implementation การ optimize แต่ละชิ้นส่วน และการรวมทุกอย่างเข้าด้วยกัน
Hermes Agent เป็นหนึ่งในโปรเจกต์ open-source ที่สร้าง agentic coding assistant และมีสถาปัตยกรรมที่คล้ายคลึงกับที่พบใน Claude Code อย่างน่าทึ่ง ทั้งระบบ memory แบบ tiered การใช้ tool calling และการแบ่งงานด้วย subagent อย่างไรก็ตาม การมีสถาปัตยกรรมที่คล้ายกันไม่ได้หมายความว่าประสิทธิภาพจะเท่ากัน ความแตกต่างอยู่ที่รายละเอียดของ implementation เช่น ขนาด cache ที่ optimal วิธีตัดสินใจ compaction strategy ใน memory หรือ threshold ที่ใช้ trigger retry ในแต่ละ error type สิ่งเหล่านี้ได้มาจาก production data และการทดสอบจริงกับผู้ใช้จำนวนมาก ไม่ใช่แค่การอ่านสถาปัตยกรรม
OpenAI ระดมทุนรอบใหญ่ที่สุด — เปิดเผย ARR 24,000 ล้านดอลลาร์
OpenAI ปิดดีล "การระดมทุนที่ใหญ่ที่สุดในประวัติศาสตร์มนุษย์" เปิดเผย ARR 24,000 ล้านดอลลาร์ (ราว 8.4 แสนล้านบาท) เติบโตเร็วกว่า Google/Meta ถึง 4 เท่า มี $3B จากนักลงทุนสถาบัน เป็น "soft IPO" ARK Invest ออก ETF ที่เกี่ยวข้อง
การเปิดเผย ARR 24,000 ล้านดอลลาร์ ถือเป็นก้าวกระโดดที่น่าตื่นตะลึงสำหรับบริษัทที่เพิ่งก่อตั้งได้ไม่กี่ปี เพื่อเปรียบเทียบ Google ใช้เวลาหลายปีกว่าจะถึงรายได้ระดับนี้ในช่วงแรกของธุรกิจโฆษณา การระดมทุนรอบนี้ซึ่งมีมูลค่ารวมกว่า $40 พันล้านดอลลาร์ถูกมองเป็น "soft IPO" เพราะเปิดให้นักลงทุนสถาบันเข้ามาถือหุ้นในสัดส่วนที่สำคัญ โดยไม่ต้องผ่านกระบวนการ IPO ที่ซับซ้อน การที่ ARK Invest รีบออก ETF ที่เชื่อมโยงกับ OpenAI บ่งชี้ว่านักลงทุนรายย่อยก็ต้องการมีส่วนร่วมในความเติบโตของบริษัทนี้เช่นกัน แม้จะยังไม่ได้จดทะเบียนในตลาดหลักทรัพย์ การที่ตัวเลข ARR เติบโตเร็วกว่า Google และ Meta ถึง 4 เท่า ในช่วงเวลาเดียวกันของการเติบโตนั้น เป็นหลักฐานที่ชัดเจนว่าการนำ AI มาใช้ในองค์กรกำลังเร่งตัวขึ้นอย่างก้าวกระโดด ไม่ใช่แค่การเติบโตเชิงเส้นตรงที่คาดการณ์ได้
ด้านมืดของ OpenAI — ChatGPT WAU หยุดเติบโต
แม้ ARR น่าประทับใจ แต่ ChatGPT WAU หยุดเติบโต ยังไม่ข้ามหลัก 1,000 ล้าน WAU Codex ไม่ประกาศ milestone ใหม่สำหรับเดือนมีนาคม ในขณะที่ Claude Code สร้างกระแส (แม้จะไม่ตั้งใจ) ความเงียบของ Codex อาจเป็นสัญญาณเตรียมเปิดตัวอะไรบางอย่าง
ความตึงเครียดระหว่าง ARR ที่พุ่งสูงกับ WAU ที่ชะลอตัวบ่งชี้ถึงปรากฏการณ์ที่น่าสนใจในธุรกิจ AI ตัวเลข ARR อาจสูงได้โดยไม่ต้องมีการเติบโตของผู้ใช้ใหม่ หากผู้ใช้เดิมใช้จ่ายมากขึ้นผ่านบัญชีองค์กรและ API OpenAI กำลังเปลี่ยนผ่านจากธุรกิจ consumer ที่ขับเคลื่อนด้วยจำนวนผู้ใช้ ไปสู่ธุรกิจ B2B ที่ขับเคลื่อนด้วยมูลค่าต่อบัญชี การที่ Codex ยังไม่ประกาศ milestone ใหม่ในขณะที่คู่แข่งกำลังได้รับความสนใจอาจบ่งชี้ว่าทีมกำลังรวมพลังเพื่อเปิดตัวบางอย่างที่ใหญ่กว่า แต่การรอนานเกินไปในตลาดที่เคลื่อนตัวเร็วเช่นนี้ก็มีความเสี่ยงในตัวเอง นักวิเคราะห์หลายรายตั้งข้อสังเกตว่า ChatGPT ในฐานะ "ประตูเข้า" สู่โลก AI ของผู้ใช้ทั่วไปยังไม่มีคู่แข่งที่แท้จริงในแง่ brand recognition แต่ในตลาด developer tools ภาพกลับต่างออกไปอย่างชัดเจน
ชุมชนออนไลน์วิเคราะห์คึกคัก — Open vs Proprietary
ประเด็นถกเถียงหลักคือ ผลกระทบต่อ open-source vs proprietary ฝ่ายหนึ่งมองว่าทุกอย่างทำซ้ำได้จาก open-source อีกฝ่ายโต้แย้งว่า การรู้สถาปัตยกรรมไม่ได้หมายความว่าจะ implement ได้ทันที การรั่วไหลย่นระยะเวลาให้คู่แข่ง แต่ไม่ลบความได้เปรียบทั้งหมด
การถกเถียงนี้ชี้ให้เห็นปรัชญาที่ลึกกว่านั้นในวงการ software engineering ว่า "การรู้สูตร" กับ "การทำอาหารได้" เป็นสองสิ่งที่แตกต่างกันมาก ฝ่ายที่มองว่า open-source สามารถทำซ้ำได้ทั้งหมดมักอ้างว่าสถาปัตยกรรมที่เห็นในซอร์สโค้ดนั้นไม่ได้ซับซ้อนเกินความสามารถของทีมดีๆ ไม่กี่คน ในขณะที่ฝ่ายตรงข้ามชี้ให้เห็นว่า Anthropic มีปีของ production data จากผู้ใช้จริงหลายล้านคนที่ทำให้ทราบว่า parameter ไหนควรตั้งค่าเท่าไร และ edge case ใดที่เจอบ่อยที่สุด ข้อมูลเหล่านี้ไม่ได้อยู่ในซอร์สโค้ดที่หลุดออกมา
Qwen อัพเดทโมเดลใหม่ — การแข่งขันเข้มข้นขึ้น
Alibaba มีการอัพเดท Qwen โมเดลใหม่พร้อม benchmark ที่ดีขึ้น เป็นหนึ่งในโมเดลจากจีนที่ได้รับความนิยมสูงใน open-source community ด้วย license เปิดกว้างและขนาดหลากหลาย ช่องว่าง open-closed ยังคงแคบลงต่อเนื่อง
Qwen ถือเป็นหนึ่งในซีรีส์โมเดลที่น่าจับตามองมากที่สุดในกลุ่ม open-source ยุคใหม่ Alibaba พัฒนาโมเดลในหลายขนาดตั้งแต่รุ่นเล็กที่รันบนเครื่องส่วนตัวได้ ไปจนถึงรุ่นใหญ่ที่แข่งขันกับโมเดล proprietary ชั้นนำ การอัพเดทต่อเนื่องและ benchmark ที่ดีขึ้นในแต่ละรุ่นทำให้ชุมชนนักพัฒนาที่ต้องการโมเดลที่ customize ได้และไม่มีค่าใช้จ่าย API รายครั้งหันมาให้ความสนใจมากขึ้น การที่โมเดลจีนอย่าง Qwen สามารถแข่งขันได้ในระดับนี้ยังสร้างแรงกดดันให้บริษัท AI ตะวันตกต้องเร่งพัฒนาโมเดล open-source ของตนเองด้วย ความได้เปรียบด้านต้นทุนของโมเดล open-source ที่ไม่มีค่า API ทำให้องค์กรขนาดเล็กและนักพัฒนาอิสระสามารถสร้างผลิตภัณฑ์ AI ที่แข่งขันได้โดยไม่ต้องพึ่งพาโครงสร้างพื้นฐานของบริษัทใหญ่ ซึ่งเป็นพลวัตที่เปลี่ยนสมการการแข่งขันในวงการ AI อย่างมีนัยสำคัญ
TurboQuant และ DeepSeek — การถกเถียงและอัพเดท
TurboQuant ยังถูกทดสอบบน hardware หลากหลายพร้อม benchmark ที่แตกต่างกัน ความตึงเครียดระหว่าง efficiency กับ quality ยังเป็นประเด็นสำคัญ ส่วน DeepSeek มีทั้งอัพเดทและปัญหาที่ถูกรายงาน เป็นตัวอย่างที่โมเดลจีนแข่งขันได้ในระดับโลก
TurboQuant เป็นเทคนิค quantization ที่มุ่งลดขนาดโมเดลให้รันได้บน hardware ที่หลากหลายโดยไม่สูญเสีย quality มากเกินไป การทดสอบบน GPU รุ่นต่างๆ ให้ผลลัพธ์ที่แตกต่างกันไปตาม architecture ทำให้การเปรียบเทียบ benchmark ต้องระบุ hardware ที่ใช้ให้ชัดเจน ในส่วนของ DeepSeek บริษัทยังคงพัฒนาอย่างต่อเนื่อง แม้จะมีรายงานปัญหาบางอย่างที่ยังอยู่ระหว่างการแก้ไข DeepSeek ได้พิสูจน์ให้เห็นแล้วว่าทีมวิจัยที่มีประสิทธิภาพสามารถสร้างโมเดลที่แข่งขันได้ในระดับโลกโดยใช้ทรัพยากรน้อยกว่าที่คาด ซึ่งเป็นข้อมูลสำคัญสำหรับการวางแผนการลงทุนใน AI infrastructure ในอนาคต การพัฒนาที่รวดเร็วของทั้ง TurboQuant และ DeepSeek ยืนยันว่าการแข่งขันในวงการโมเดล AI ไม่ได้จำกัดอยู่แค่ภูมิภาคใดภูมิภาคหนึ่งอีกต่อไป
DMCA และข้อถกเถียงทางกฎหมาย
Fork หนึ่งแก้ปัญหา DMCA โดย แปลงโค้ดทั้งหมดเป็น Python เพราะ "แนวคิด" ไม่สามารถจดลิขสิทธิ์ แต่ "expression" สามารถ การเขียนใหม่ในภาษาอื่นอาจถือเป็น expression ใหม่ที่ไม่ละเมิด ประเด็นทางกฎหมายนี้จะส่งผลต่อวิธีจัดการกับการรั่วไหลในอนาคต
กรณีนี้เปิดประเด็นทางกฎหมายที่ยังไม่มีคำตอบชัดเจนในแวดวง software copyright การที่ใครบางคน "rewrites" โค้ดในภาษาใหม่โดยรักษาโครงสร้างและตรรกะเดิมไว้ แต่เปลี่ยน syntax ทั้งหมด ยังคงเป็นที่ถกเถียงในหมู่นักกฎหมายว่าถือเป็น copyright infringement หรือไม่ ในทางทฤษฎี copyright ปกป้อง "expression" ไม่ใช่ "idea" แต่ในทางปฏิบัติ เส้นแบ่งระหว่างสองสิ่งนี้ไม่ชัดเจนเสมอไป การที่ชุมชนนักพัฒนาทดสอบขอบเขตนี้อย่างรวดเร็วผ่านการ port เป็น Python จะสร้าง precedent ที่สำคัญสำหรับกรณีการรั่วไหลของซอร์สโค้ดในอนาคต นอกจากนี้ เหตุการณ์นี้ยังอาจกระตุ้นให้บริษัท AI หลายแห่งทบทวนกระบวนการ packaging และ deployment ของตนเองเพื่อป้องกันไม่ให้ source maps หลุดออกไปพร้อมกับ production build โดยไม่ตั้งใจ เพราะข้อผิดพลาดด้าน build configuration เช่นนี้อาจเกิดขึ้นได้กับองค์กรใดก็ตามหากไม่มีกระบวนการตรวจสอบที่รัดกุม
สิ่งที่การรั่วไหลยืนยัน — 3 ความจริงของ AI Engineering
- Wrapper ไม่เคยเป็นแค่ wrapper — application layer มีความซับซ้อนมหาศาล
- โมเดลเป็นแค่ส่วนหนึ่ง — เครื่องยนต์ไม่มีความหมายถ้าไม่มีช่วงล่าง เกียร์ และระบบนำทาง
- ช่วงเวลาแห่งความได้เปรียบกำลังหดสั้นลง — ผู้ที่ชนะจะเป็นผู้ที่ iterate เร็วที่สุด ไม่ใช่ผู้ที่มีความลับมากที่สุด
ความจริง 3 ข้อนี้ไม่ใช่สิ่งใหม่สำหรับวิศวกรซอฟต์แวร์ที่มีประสบการณ์ แต่การรั่วไหลของซอร์สโค้ดครั้งนี้ทำให้เห็นภาพที่เป็นรูปธรรมมากขึ้น ประการแรก ความซับซ้อนของ application layer ใน Claude Code แสดงให้เห็นว่าการสร้าง AI agent ที่ "ใช้งานได้จริง" ต้องการงานวิศวกรรมที่ลึกกว่าแค่การ wrap API มาก ประการที่สอง อุปมาอุปมัยเรื่องเครื่องยนต์กับช่วงล่างนั้นแม่นยำมาก โมเดลที่ดีที่สุดในตลาดก็ทำงานได้ไม่ดีหากวางอยู่บน harness ที่อ่อนแอ ประการที่สาม ในยุคที่ข้อมูลรั่วไหลได้ง่ายและชุมชนนักพัฒนาเคลื่อนตัวเร็ว ความได้เปรียบจากการรักษา "ความลับ" มีอายุสั้นลงเรื่อยๆ ทีมที่ iterate เร็วและใช้ feedback จากผู้ใช้จริงได้ดีกว่าจะอยู่รอดในระยะยาว นี่คือบทเรียนที่ยิ่งใหญ่ที่สุดจากเหตุการณ์ครั้งนี้ และเป็นสัญญาณเตือนสำหรับทีมพัฒนา AI ทุกทีมว่า การสะสมความรู้และ production data จากผู้ใช้จริงมีค่ามากกว่าการซ่อนรักษาสถาปัตยกรรม
ภาพรวม — การรั่วไหลที่เปลี่ยนมุมมองทั้งวงการ
การรั่วไหลของ Claude Code ไม่ได้เปิดเผย model weights แต่เปิดเผย agent harness stack ที่อยู่เบื้องหลังเครื่องมือ coding ชั้นนำ สิ่งที่พบยืนยันว่า high-performance coding agents ขึ้นอยู่กับระบบที่ซับซ้อนมาก — memory 3 ชั้น, subagent ที่ใช้ prompt caching, permission 5 ระดับ, plan mode, error taxonomy และอีกมาก ในขณะเดียวกัน OpenAI ปิดดีลระดมทุนประวัติศาสตร์ด้วย ARR 2.4 หมื่นล้านดอลลาร์ แต่การเติบโตของผู้ใช้กลับชะลอตัว
การรั่วไหลครั้งนี้จะเร่งการแข่งขันในตลาด AI coding tools อย่างแน่นอน คู่แข่งทุกรายจะศึกษาสถาปัตยกรรมที่ถูกเปิดเผย แต่ Anthropic ยังมีข้อได้เปรียบจาก production data ที่สะสมจากผู้ใช้จริงหลายล้านคน ซึ่งคัดลอกจากซอร์สโค้ดไม่ได้ การระดมทุนมหาศาลของ OpenAI ในขณะที่ยังต้องเผชิญกับการชะลอตัวของ WAU สะท้อนให้เห็นว่าตลาด AI ยังอยู่ในช่วงเปลี่ยนผ่านสำคัญ ที่ใครจะเป็น "ผู้ชนะ" ในระยะยาวยังเป็นคำถามที่ยังไม่มีคำตอบ เหตุการณ์ทั้งหมดในสัปดาห์นี้ยืนยันว่าวงการ AI กำลังเคลื่อนตัวเร็วและไม่แน่นอนกว่าที่เคย สิ่งที่แน่ใจได้คือทั้งผู้พัฒนาเครื่องมือ นักลงทุน และผู้ใช้งานทั่วไปต่างต้องปรับตัวให้ทันกับพลวัตที่เปลี่ยนแปลงอย่างรวดเร็วนี้ และสัปดาห์ที่ผ่านมาเป็นตัวอย่างที่ชัดเจนว่าข่าวสำคัญในวงการ AI ไม่ได้เกิดขึ้นแบบค่อยๆ สะสม แต่มักเกิดขึ้นอย่างกะทันหันและส่งผลกระทบในวงกว้างภายในเวลาไม่กี่วัน
สำหรับนักพัฒนาที่ติดตามวงการ บทเรียนที่ถือว่าสำคัญที่สุดจากสัปดาห์นี้อาจไม่ใช่รายละเอียดของสถาปัตยกรรม harness แต่คือความจริงที่ว่าการลงทุนในด้านวิศวกรรมระบบรอบโมเดลนั้นมีมูลค่าอย่างมหาศาล ไม่ว่าคุณจะกำลังสร้างผลิตภัณฑ์ AI สำหรับองค์กร พัฒนา open-source agent หรือแค่ต้องการทำความเข้าใจว่าทำไมเครื่องมือบางตัวจึงทำงานได้ดีกว่าตัวอื่นแม้ใช้โมเดลเดียวกัน ซอร์สโค้ดที่หลุดออกมาครั้งนี้เป็นทั้งหลักสูตรขั้นสูงและคำเตือนที่ทรงคุณค่าในเวลาเดียวกัน
ข้อมูล ณ วันที่ 1 เมษายน 2569 — บทความนี้จัดทำขึ้นเพื่อให้ข้อมูลเท่านั้น ไม่ได้เป็นคำแนะนำด้านการลงทุนแต่อย่างใด