
สรุปข่าว AI: 4 บทบาทสุดท้ายในวงการเทค, Claude Code ควบคุม UI ได้, Qwen3.5-Omni, Hermes Agent OS, OpenAI มีปัญหา
4 บทบาทสุดท้ายในวงการเทค — โมเดลใหม่ของทีมยุค AI
แนวคิดเรื่อง "AI Engineer" ที่เกิดขึ้นในปี 2566 ตามด้วยกระแส "Tiny Teams" ในปี 2568 กำลังวิวัฒนาการไปอีกขั้น บทความจากนักวิเคราะห์อุตสาหกรรมเสนอโมเดลใหม่สำหรับบทบาทคนทำงานเทคในยุคหลัง AI โดยอ้างอิงมุมมองของ Karri Saarinen ซีอีโอของ Linear ที่เปรียบเทียบโครงสร้างทีมกับเกม World of Warcraft: Tank (รับแรงกดดัน ตัดสินใจหลัก), Healer (ดูแลคุณภาพ ความยั่งยืน), DPS (ผลิตผลงานเร็ว), Support (ช่วยให้ทุกคนทำงานได้ดีขึ้น)
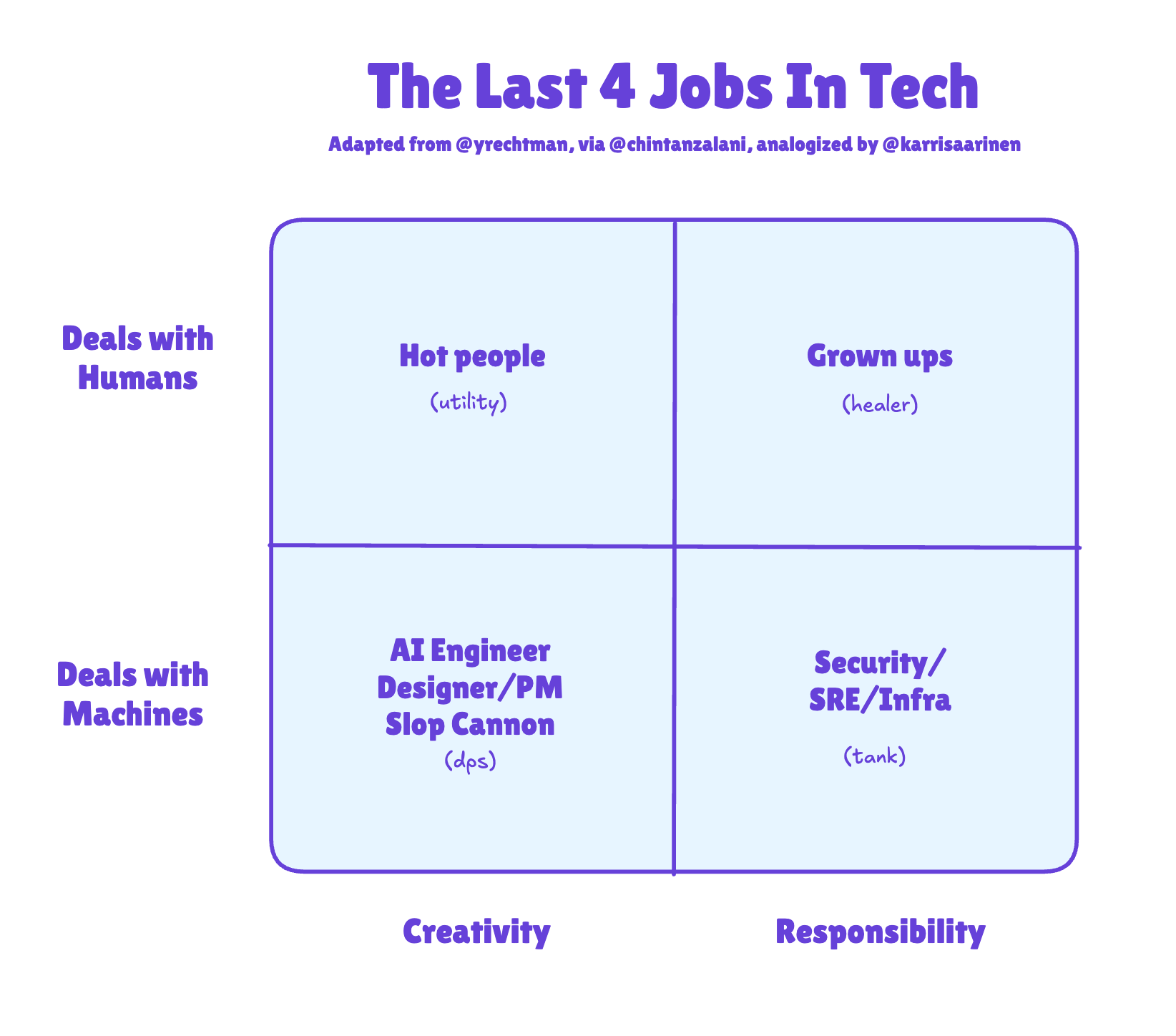
สิ่งที่น่าจับตาคือทีมเทคจะเล็กลงมากแต่แต่ละคนจะมีบทบาทชัดเจนกว่าเดิม AI จะเข้ามาแทนที่งานที่เคยต้องใช้คนจำนวนมาก แต่ยังต้องการคนที่เข้าใจบริบท ตัดสินใจเชิงกลยุทธ์ และประสานงานระหว่างระบบ AI หลายตัว
Claude Code เพิ่ม Computer Use — ปิดวงจร "เขียนโค้ด-ทดสอบ-แก้ไข" อัตโนมัติ
Anthropic เปิดตัวฟีเจอร์ Computer Use ภายใน Claude Code (research preview, Pro/Max) ทำให้ agent สามารถเปิดแอป คลิก UI ตรวจสอบผลลัพธ์ และแก้ไขปัญหาได้จาก CLI เป็น closed-loop verification: เขียนโค้ด → รัน → ตรวจ UI → แก้ → ทดสอบใหม่ นักพัฒนาเรียกว่าเป็น "ชิ้นส่วนที่ขาดหายไป" สำหรับการพัฒนาแอปแบบ iterative ที่เชื่อถือได้
Codex Plugin สำหรับ Claude Code — Agent ข้ามค่ายทำงานร่วมกัน
OpenAI ปล่อย Codex plugin ที่ทำงานใน Claude Code ได้ สั่ง review, adversarial review หรือ "rescue flow" จากในระบบ Anthropic ใช้ ChatGPT subscription ปกติ สัญญาณชัดว่า coding stack กำลังเป็น composable harness ข้อมูลน่าสนใจ: task ที่ส่ง Codex ตอน 5 ทุ่มมีโอกาส 60% จะรันนานกว่า 3 ชั่วโมง
คุณภาพ Harness สำคัญกว่าคุณภาพโมเดล
Theo ค้นพบว่า Claude Opus ให้คะแนนสูงกว่า ~20% ใน Cursor เทียบกับ Claude Code ทั้งที่เป็นโมเดลเดียวกัน Closed-source harness ทำให้วินิจฉัย regression ได้ยาก ความแตกต่างของโมเดลแคบลงเรื่อย ๆ แต่ tooling และ orchestration ยังสร้างความแตกต่างมาก
Hermes Agent อัปเดตใหญ่ — ก้าวสู่ Agent OS แบบเปิด
Nous Research ปล่อยอัปเดตสำคัญ จุดกระแสย้ายจาก OpenClaw มาจำนวนมาก ระบบ multi-agent profiles ให้แต่ละ bot มี memory, skills, histories เป็นของตัวเอง เคลื่อนจาก "ผู้ช่วยส่วนตัว" สู่ reusable agent OS abstraction
ระบบนิเวศ Hermes: Traces, Self-Improvement, Remote Control
opentraces.ai ให้เผยแพร่ agent traces ไปยัง HF มี GLM-5 traces กว่า 4,000 รายการ วงจร: agent บันทึกการตัดสินใจ → export → fine-tune โมเดลเล็กกว่า → สลับไปใช้โมเดลถูกกว่า ARC เพิ่ม remote browser monitoring ด้วย E2E encryption
Open Source ปะทะ Proprietary Agent Infra
Clement Delangue (HF): open-source agent tools ควรใช้ open-source models เป็นค่าเริ่มต้น PokeeClaw: OpenClaw ที่ปลอดภัยกว่ามี sandboxing, RBAC, audit trails Z AI AutoClaw: local runtime ไม่ต้องใช้ API key
Qwen3.5-Omni — Multimodal ระดับหนักจาก Alibaba
รองรับข้อความ ภาพ เสียง วิดีโอแบบ native มี script-level captioning, web search, function calling ในตัว สาธิต "audio-visual vibe coding" สร้างแอปจากเสียงพูด+ภาพ รองรับเสียงยาว 10 ชม., วิดีโอ 720p 400 วินาที, 113 ภาษา speech recognition, 36 spoken languages อ้างว่าเหนือกว่า Gemini 3.1 Pro ในด้านเสียง
GLM-5-Turbo — จูนมาเพื่องาน Agent โดยเฉพาะ
AA Intelligence Index: 47 (ต่ำกว่า GLM-5 ที่ 50) แต่ GDPval-AA: 1,503 (สูงกว่า GLM-5 ที่ 1,408) ยืนยันว่าจูนสำหรับ agent workflow จริง ไม่ใช่ broad benchmark แนวทาง โมเดลเฉพาะทาง ที่ทำงานเฉพาะอย่างได้ดีเยี่ยม มีค่ามากกว่าโมเดลอเนกประสงค์
โมเดลเปิดเฉพาะทาง — รูปแบบ Deploy ที่กำลังมาแรง
บริษัทเลือกเป็นเจ้าของและปรับแต่งโมเดลเปิดบนข้อมูลตัวเอง แทนเช่า API Qwen3.5-27B distill จาก Claude Opus ติดเทรนด์ HF ใส่ 16GB ในโหมด 4-bit ได้ llama.cpp และ MLX ได้รับความนิยมเพิ่มขึ้นต่อเนื่อง
llama.cpp ทะลุ 100,000 ดาว GitHub
ggerganov: ปี 2569 จะเป็นปีที่ local agentic workflow เบ่งบาน automation ที่มีประโยชน์ไม่จำเป็นต้องใช้โมเดล frontier บน cloud จุดแข็งคือรองรับฮาร์ดแวร์หลากหลายและไม่ผูกติด vendor
Flash-MoE: รัน 397B บน MacBook Pro 48GB ที่ 4.4 tok/s
Qwen3.5-397B บน MacBook Pro 48GB ด้วย pure C + Metal engine สตรีมน้ำหนักจาก SSD โหลดเฉพาะ active expert ใช้ RAM จริงเพียง ~5.5GB แม้ช้าสำหรับ interactive use แต่ใช้งาน batch/agent workflow ได้จริง
Transformers.js v4 และ vLLM-Omni v0.18.0
Transformers.js v4: WebGPU backend ข้าม browser/Node/Bun/Deno รองรับ 200+ architectures vLLM-Omni v0.18.0: 324 commits, production TTS/omni serving, unified quantization
Agent Harness Research — Natural Language และ Meta-Harness
Tsinghua: ให้ LLM execute orchestration logic จาก SOP แทน hard-coded rules Meta Meta-Harness: optimize harness end-to-end ขึ้นอันดับ 1 บน TerminalBench-2
CAID: Multi-Agent SWE ที่ทำงานพร้อมกัน
Centralized asynchronous isolated delegation ใช้ manager agent, dependency graph, isolated git worktrees, self-verification ผลลัพธ์ +26.7 บน PaperBench และ +14.3 บน Commit0 vs single-agent
Coding Agent เป็น Long-Context Processor
ปฏิบัติกับ codebase เป็น directory tree นำทางด้วย shell command 88.5% บน BrowseComp-Plus (750M tokens) vs 80% เดิม ทำงานได้ถึง 3 ล้านล้าน token
Gram Newton-Schulz สำหรับ Muon — เร็วขึ้น 2 เท่า
Drop-in replacement ทำงานกับ symmetric Gram matrix ขนาดเล็กแทน rectangular matrix ใหญ่ ได้รับคำชมจาก Tri Dao
Shopify ลดต้นทุน AI 98% ด้วย DSPy — จาก 190 ล้านเหลือ 2.5 ล้านบาทต่อปี
จาก $5.5M เหลือ $73K/ปี โดยแยก business logic → model intent ด้วย DSPy → สลับไปโมเดลเล็กที่ optimize มาเฉพาะงาน พิสูจน์ว่าโมเดลใหญ่แบบ one-size-fits-all เป็นความสิ้นเปลืองสำหรับ production
Anthropic ยืนยัน "Mythos" — โมเดลเหนือ Opus พร้อมระดับ Capybara
Fortune ยืนยัน Anthropic ทดสอบ "โมเดลทรงพลังที่สุด" ชื่อรหัส Mythos ในระดับ Capybara เหนือ Opus ปรับปรุง reasoning, coding, cybersecurity ข้อมูลหลุดจาก CMS misconfiguration Rollout ระมัดระวังเพราะกังวลเรื่อง cybersecurity misuse
OpenAI กำลังมีปัญหา — "ทำทุกอย่าง...แย่หมด"
The Atlantic: "OpenAI Is Doing Everything... Poorly" Sora ยกเลิก (ต้นทุน $15M/วัน), Stargate ล่าช้า, Adult Mode ระงับ (age verification ระบุผู้เยาว์ผิด 12%) ปรับโฟกัสไป enterprise Open-source จีนทำผลงานดีกว่าในหลายด้าน
วิกฤตโควตา Claude — ผู้ใช้ระอุ
Anthropic ปรับ session limit ช่วง peak hours กระทบ ~7% ของผู้ใช้ "Hello" + ถามสภาพอากาศ = 7% ของโควตา Pro users ถูกจำกัดหลัง 2 ข้อความ Max plan ($100) ถึง limit ใน 3 ชม. มีจดหมายเปิดผนึก + ยกเลิก subscription จำนวนมาก
พบร่องรอย Qwen 3.6 — Context 1 ล้าน Token
Preview Qwen 3.6 Plus รองรับ context 1M token คาดว่าจะแก้ "overthinking problem" ของ 3.5 โมเดล 397B อยู่ใกล้ระดับ SOTA แล้ว
ข้อถกเถียง TurboQuant/RaBitQ ทวีความรุนแรง
ผู้เขียน RaBitQ ออกมาชี้แจง 3 ข้อกังวล: คำอธิบายไม่ครบ, ข้อกล่าวอ้างไม่มีหลักฐาน, เปรียบเทียบที่ทำให้เข้าใจผิด ข้อมูลจริง: Q8_0 ไม่ใช้ rotation ได้ 31.7% ใส่ rotation ได้ 37.1% asymmetric q8_0-K + turbo4-V เกือบไม่มี loss
ค้นหาวิดีโอด้วยภาษาธรรมชาติผ่าน Qwen3-VL
ฝังวิดีโอดิบเข้า vector space โดยตรง ค้นหาด้วยภาษาธรรมชาติไม่ต้องถอดเสียง โมเดล 8B ใช้ RAM ~18GB, 2B ใช้ ~6GB
CODEC: ควบคุมคอมพิวเตอร์ด้วยเสียง Local ทั้งหมด
Framework โอเพนซอร์ส MIT ใช้ Qwen 3.5 35B + Whisper + Kokoro รันบน Mac Studio เครื่องเดียว 36 skills ไม่ส่งข้อมูลไป cloud
ภาพรวมสัปดาห์ — Local-First AI และ Agent Orchestration กำลังเปลี่ยนเกม
ธีมหลัก 2 ประการ ประการแรก Local AI ถึงจุดเปลี่ยน — llama.cpp 100K ดาว, Flash-MoE รัน 397B บน laptop, CODEC ควบคุมเครื่องด้วยเสียงแบบ offline, Shopify ลดต้นทุน 98% ด้วยโมเดลเล็กเฉพาะทาง ประการที่สอง Agent orchestration ร้อนแรง — Claude Code + Computer Use ปิด loop การพัฒนา, Codex plugin ข้ามค่าย, Hermes สร้าง agent OS, CAID พิสูจน์ว่า multi-agent ดีกว่า single-agent อย่างมาก
ในขณะที่ผู้นำตลาดทั้ง OpenAI และ Anthropic กำลังเผชิญปัญหา — OpenAI กระจายทรัพยากรเกินไป ส่วน Anthropic มีปัญหาโควตาที่ทำลายความไว้วางใจ — โมเดลเปิดจากจีนอย่าง Qwen3.5-Omni และ GLM-5.1 กำลังปิดช่องว่างอย่างรวดเร็ว ความสามารถของโมเดลไม่ใช่ปัจจัยชี้ขาดอีกต่อไป — ระบบนิเวศ เครื่องมือ ต้นทุน และประสบการณ์ผู้ใช้ต่างหากที่จะกำหนดผู้ชนะ
ข้อมูล ณ วันที่ 31 มีนาคม 2569 — บทความนี้จัดทำขึ้นเพื่อให้ข้อมูลเท่านั้น ไม่ได้เป็นคำแนะนำด้านการลงทุนแต่อย่างใด