
สรุปข่าว AI: ราคาเช่า H100 กลับมาพุ่ง, Anthropic หลุดข้อมูล Capybara, GLM-5.1 ไล่จี้ Claude, RotorQuant เร็วกว่า TurboQuant 19 เท่า
ราคาเช่า H100 กลับมาพุ่ง — ชิปอายุ 4 ปีกลับมีค่ามากกว่าตอนเปิดตัว
ตลาดเช่า GPU กำลังเปลี่ยนทิศอย่างชัดเจน นับตั้งแต่เดือนธันวาคม 2568 ราคาเช่า NVIDIA H100 ที่เคยร่วงลงอย่างหนักหลังจาก DeepSeek R1 สร้างแรงกระเพื่อมในตลาด กลับพลิกกลับมาขาขึ้นอย่างต่อเนื่อง จนถึงปลายเดือนมีนาคม 2569 ราคาเช่าไม่เพียงฟื้นตัว แต่ยังสูงกว่าช่วงก่อนเกิด DeepSeek shock เสียอีก
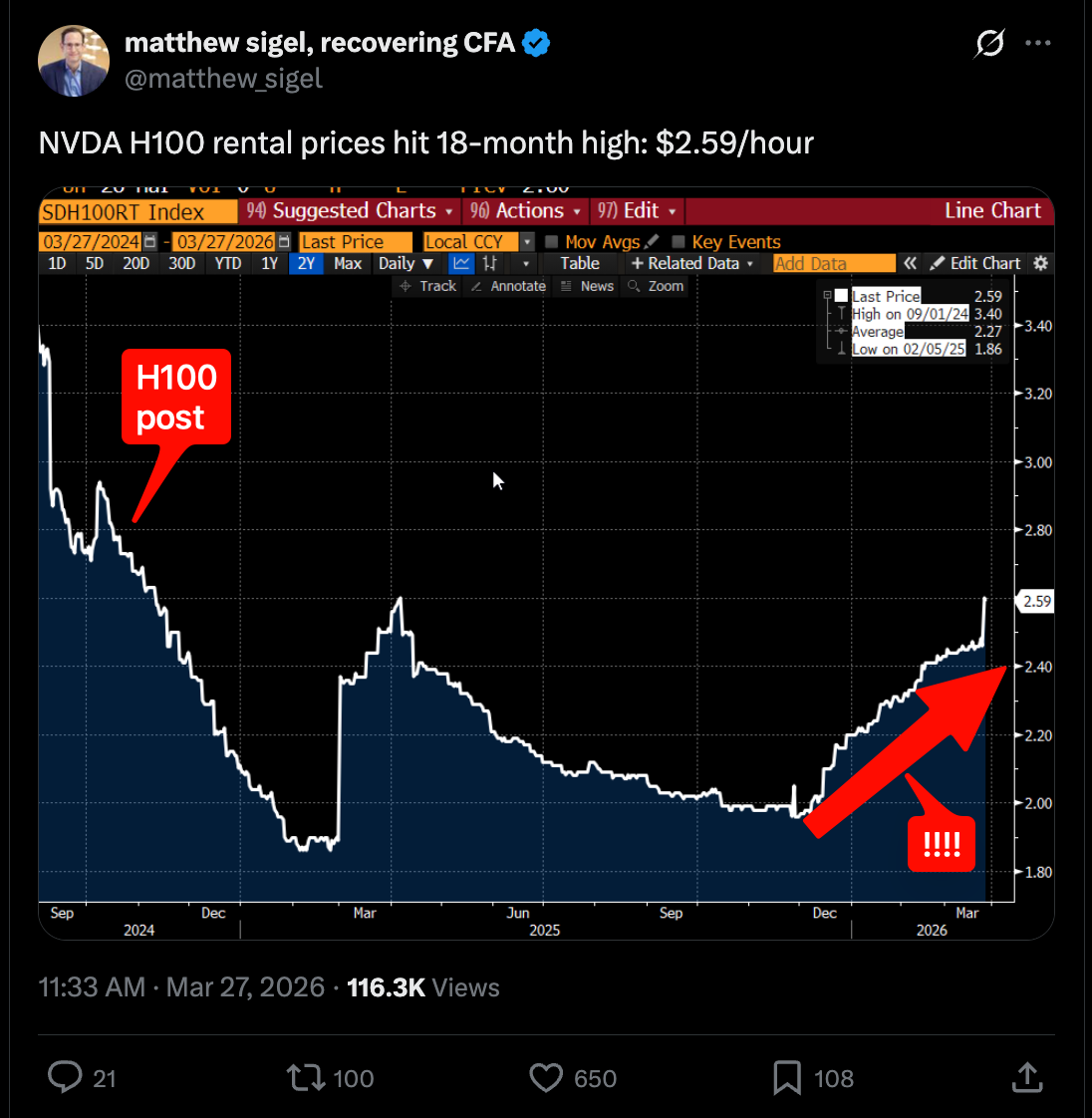
Dylan Patel นักวิเคราะห์ชิปชื่อดังให้สัมภาษณ์ว่า H100 ในปัจจุบัน "มีมูลค่ามากกว่าเมื่อ 3 ปีที่แล้ว" สาเหตุหลักมาจาก reasoning model ที่ต้องการ compute สูงในขั้นตอน inference และ AI agent ที่ต้องรันต่อเนื่องเป็นเวลานาน ซอฟต์แวร์ inference รุ่นใหม่ทำให้ H100 ทำงานได้มีประสิทธิภาพมากขึ้น ตารางค่าเสื่อมราคา 4-7 ปี ที่บริษัท data center เคยตั้งไว้กลายเป็นอนุรักษนิยมเกินไป
ปรากฏการณ์นี้ขัดกับสมมติฐานที่เคยมีมาว่าชิปรุ่นเก่าจะถูกแทนที่อย่างรวดเร็วด้วย H200 หรือ Blackwell แต่ความเป็นจริงคือ H100 ยังคงเป็นที่ต้องการสูงเพราะ ecosystem ของซอฟต์แวร์และ CUDA kernels ที่ optimize สำหรับสถาปัตยกรรม Hopper สะสมมานาน ทำให้ผู้ประกอบการ data center ที่ลงทุนใน H100 ไปแล้วได้ประโยชน์เต็มเม็ดเต็มหน่วย นอกจากนี้ความต้องการที่พุ่งสูงจาก workload ประเภท long-context inference และ multi-step agent tasks ซึ่งใช้ GPU ตลอด 24 ชั่วโมงนั้น ทำให้ utilization rate ของ H100 อยู่ในระดับสูงกว่าที่นักวิเคราะห์ประเมินไว้ เมื่อ demand มากกว่า supply ราคาเช่าก็ต้องพุ่งขึ้นตาม
Anthropic หลุดข้อมูลโมเดลใหม่ "Capybara" — ใหญ่กว่าและฉลาดกว่า Claude Opus 4.6
มีรายงานว่า Anthropic กำลังเตรียมเปิดตัวโมเดลระดับใหม่ชื่อรหัส "Capybara" (บางแหล่งเรียก "Mythos") เป็น tier เหนือ Claude Opus 4.6 มีขนาดใหญ่กว่าและทำคะแนนสูงกว่าใน coding, academic reasoning และ cybersecurity แต่ rollout ถูกจำกัดด้วยต้นทุนสูงและข้อกังวลด้านความปลอดภัย
มีการคาดเดาว่าโมเดลนี้อาจอยู่ในระดับ ~10 ล้านล้านพารามิเตอร์ จากคำพูดของ Dario Amodei แม้ยังไม่ยืนยัน ข้อมูลที่หลุดออกมายังระบุว่า Capybara ถูกออกแบบมาเพื่อรองรับงานที่ต้องการความคิดเชิงวิทยาศาสตร์เชิงลึก ทั้งการวิจัยทางการแพทย์ การวิเคราะห์ code base ขนาดใหญ่ และการประเมินช่องโหว่ด้านความปลอดภัยไซเบอร์ในระดับที่ Claude Opus 4.6 ยังทำได้ไม่ถึง นอกจากนี้ยังมีข่าวว่า [Google] ใกล้บรรลุข้อตกลงสนับสนุน data center ของ Anthropic สะท้อนว่าการแข่งขัน frontier model ถูกจำกัดด้วย พลังงานและเงินทุน ไม่ใช่แค่อัลกอริทึม เพราะการฝึกโมเดลขนาดนั้นต้องการ compute cluster มูลค่าหลายพันล้านดอลลาร์และโครงสร้างพลังงานที่รองรับได้เฉพาะผู้ร่วมทุนรายใหญ่เท่านั้น
Anthropic เผชิญปัญหาเสถียรภาพ — Error 529 ท่ามกลางข่าวหลุด
ข่าว Capybara มาในจังหวะที่ผู้ใช้ Claude จำนวนมากรายงาน Error 529 และความล้มเหลวที่สูงกว่าปกติ สะท้อนความตึงตัวของ infrastructure ที่ Anthropic กำลังเผชิญ — การสร้างสมดุลระหว่างความทะเยอทะยานในการ scale กับขีดจำกัดของ serving infrastructure
Error 529 หมายถึงสถานะ overloaded ที่ server ไม่สามารถประมวลผล request ได้ทัน เป็นสัญญาณที่ชัดเจนว่าปริมาณการใช้งานเกินกว่าที่ระบบออกแบบมารองรับ ในช่วงเวลาเดียวกันที่ Anthropic กำลังเตรียมเปิดตัวโมเดลใหม่ที่ใหญ่กว่าและหนักกว่า ปัญหาการขยาย serving capacity จึงกลายเป็นโจทย์สำคัญอันดับต้น บางนักวิเคราะห์มองว่าการที่ Claude มีปัญหา uptime ในช่วง peak demand อาจทำให้ผู้ใช้ระดับองค์กรบางส่วนหันไปพิจารณาโซลูชันทางเลือกในระหว่างที่ Anthropic แก้ไขปัญหา capacity ให้สมดุลกับ demand ที่เพิ่มขึ้น
GLM-5.1 จากจีนไล่จี้ Claude — ช่องว่าง Open-Closed แคบลงอย่างรวดเร็ว
[Zhipu] เปิดตัว GLM-5.1 ผล coding evaluation แสดงคะแนน 45.3 เทียบกับ Claude Opus 4.6 ที่ 47.9 ห่างกันเพียง 2.6 คะแนน ซึ่งแคบมากเทียบกับปีที่แล้ว โมเดล coding จากจีนทั้ง open-weight และ semi-open กำลังปิดช่องว่างกับโมเดลปิดจากตะวันตกอย่างรวดเร็ว
ความน่าสนใจของ GLM-5.1 อยู่ที่ไม่ใช่เพียงคะแนน benchmark เท่านั้น แต่เป็นสัญญาณว่าการวิจัยด้าน AI ในจีนกำลังเดินหน้าด้วยความเร็วสูงแม้มีการจำกัดส่งออกชิปจากสหรัฐ ทีม Zhipu ใช้เทคนิค training optimization ที่แตกต่างออกไปเพื่อชดเชยการขาด H100 รุ่นใหม่ รวมถึงการใช้ data flywheel จากผู้ใช้จำนวนมากในประเทศจีน ช่องว่าง 2.6 คะแนนที่เหลืออยู่นั้นถือว่าไม่มีนัยสำคัญในทางปฏิบัติสำหรับงานหลายประเภท และหากแนวโน้มนี้ดำเนินต่อไป GLM-5.2 หรือรุ่นถัดไปอาจแซงหน้า Claude ใน coding benchmark ได้ภายในปลายปี 2569
เศรษฐศาสตร์การรันโมเดลในเครื่อง — ถูกลงจนคุ้มค่าแล้ว
Local model กลายเป็น "good enough" สำหรับ workflow จำนวนมาก ผู้ใช้เลิกจ่ายค่า [TTS] subscription แพงๆ หันมาใช้ Qwen 3.5 14B ในเครื่อง ส่วน Qwen 27B คู่กับ Hermes Agent ให้ผลคุ้มค่า และ Qwen3.5-35B บีบอัดใส่ [VRAM] 24GB ได้โดยเสียประสิทธิภาพแค่ ~1%
แนวโน้มนี้เกิดจากการผสานกันของสามปัจจัย ได้แก่ ต้นทุน API ที่ยังสูงสำหรับงานที่ต้องการ volume มาก, คุณภาพของโมเดลขนาดกลางที่ดีขึ้นอย่างก้าวกระโดด และ hardware ราคาพันดอลลาร์ที่มี [VRAM] เพียงพอสำหรับโมเดล 14-35B แล้ว เมื่อคำนวณต้นทุนต่อ token ในระยะยาว การลงทุน GPU ครั้งเดียวสำหรับ workload ที่คาดเดาได้มักคืนทุนได้ภายใน 6-12 เดือน โดยเฉพาะสำหรับนักพัฒนาหรือทีมที่ใช้งาน inference เป็นประจำทุกวัน เทคนิค quantization ที่ก้าวหน้าขึ้นทำให้ model ขนาดใหญ่ใส่ลง consumer hardware ได้โดยไม่เสียคุณภาพมากนัก
TurboQuant ถูกตั้งคำถาม — ข้อกล่าวหาเรื่อง Benchmark ไม่ยุติธรรม
เปเปอร์ [TurboQuant] ของ [Google] ที่ ICLR 2026 ถูกกล่าวหาว่าเปรียบเทียบ [TurboQuant] บน GPU กับ [RaBitQ] บน CPU อย่างไม่ยุติธรรม ข้อวิจารณ์ดังกล่าวไม่ได้ทำให้คุณค่าทาง engineering เป็นโมฆะ แต่ก่อให้เกิดคำถามต่อ comparative claims ที่นำเสนอในงานวิจัย
ปัญหา benchmark methodology นี้ไม่ใช่ครั้งแรกในวงการ AI ชุมชนวิจัยตั้งข้อสังเกตว่าการเลือก hardware baseline ที่ไม่เท่ากันเป็นวิธีที่ทำให้ตัวเลขความเร็วดูดีเกินจริงโดยไม่จำเป็นต้องโกหก ในกรณีนี้ ถ้า [RaBitQ] ถูกรันบน GPU เช่นเดียวกัน ช่องว่างด้านประสิทธิภาพที่อ้างอิงในเปเปอร์อาจแคบลงมาก นักพัฒนาที่สนใจ [TurboQuant] จึงควรทดสอบกับ workload จริงของตัวเองแทนที่จะเชื่อตัวเลขในเปเปอร์อย่างไม่ตั้งคำถาม เพราะผลลัพธ์จริงขึ้นอยู่กับ hardware, model size และ context length ที่ใช้งาน
TurboQuant ทำงานบน MacBook Air — รัน Qwen 3.5-9B บนเครื่อง 16GB
แม้มีข้อถกเถียงด้าน benchmark [TurboQuant] มีคุณค่าจริงในทางปฏิบัติ โดยสามารถรัน Qwen 3.5-9B พร้อม context 20,000 token บน MacBook Air M4 16GB ได้ ซึ่งเป็นไปไม่ได้ก่อนหน้านี้ด้วยเทคนิค quantization แบบเดิม อย่างไรก็ตาม implementation ถูกพบว่าเป็นเวอร์ชันดัดแปลงจาก [Jan.ai] เพียงเล็กน้อย ซึ่งสะท้อนว่างานวิจัยส่วนหนึ่งยืนอยู่บนไหล่ยักษ์ของ open-source community
ความสำเร็จในการรัน context 20,000 token บน RAM ขนาด 16GB มีนัยสำคัญสำหรับผู้ใช้ทั่วไปที่ไม่มีงบประมาณซื้อ GPU แพงๆ เพราะ MacBook Air M4 เป็นเครื่องที่ซื้อได้ในงบ 30,000-40,000 บาท ความสามารถดังกล่าวเปิดโอกาสให้นักพัฒนา freelance และนักศึกษาเข้าถึง local inference ที่ใช้งานได้จริงสำหรับงาน coding assistance, summarization และ document analysis โดยไม่ต้องพึ่ง cloud API ทุกครั้ง ข้อที่น่าสังเกตคือ Apple Silicon มีความได้เปรียบด้าน unified memory bandwidth ซึ่งทำให้ quantized model ทำงานได้ดีกว่า discrete GPU ที่ VRAM เท่ากัน นอกจากนี้ M4 มี Neural Engine ที่ช่วยเร่ง matrix multiply บางประเภทได้เพิ่มเติมอีกด้วย
TurboQuant KV Optimization — เร่ง decode เร็วขึ้น 22.8%
หนึ่งในนวัตกรรมสำคัญของ [TurboQuant] คือการข้าม 90% ของงาน KV dequantization โดยอาศัย attention sparsity ผลลัพธ์คือ +22.8% decode speed ที่ 32K context บน M5 Max ด้วยการแก้ kernel เพียง ~3 บรรทัด และ perplexity ไม่เปลี่ยน ผลลัพธ์ consistent ข้ามหลาย hardware
หัวใจของเทคนิคนี้คือการสังเกตว่าใน attention mechanism ส่วนใหญ่ของ KV cache นั้น token ส่วนมากมี attention weight ต่ำมากจน dequantization ไม่มีผลต่อ output สุดท้าย ดังนั้นการข้ามขั้นตอนนั้นสำหรับ token ที่ "sparse" จึงช่วยลด memory bandwidth อย่างมีนัยสำคัญโดยไม่กระทบ output คุณภาพ การที่การปรับปรุงนี้ทำได้ด้วยการแก้ kernel เพียง 3 บรรทัดแสดงว่ามันเป็น optimization ที่ elegant และ maintainable ทำให้ developers สามารถ integrate ได้ง่ายโดยไม่ต้องเปลี่ยนสถาปัตยกรรมโมเดล สิ่งที่ทำให้ผลลัพธ์น่าเชื่อถือยิ่งขึ้นคือ perplexity ไม่เปลี่ยนแปลงแม้เพิ่มความเร็ว 22.8% ซึ่งบ่งชี้ว่า sparsity assumption ที่ใช้นั้นตรงกับธรรมชาติของ attention pattern จริงในโมเดลภาษา
RotorQuant — เร็วกว่า TurboQuant 10-19 เท่า ด้วย Clifford Algebra
[RotorQuant] ใช้ Clifford rotors แทน random orthogonal matrices ทำให้เร็วกว่า [TurboQuant] 10-19 เท่า ใช้พารามิเตอร์น้อยกว่า 44 เท่า ได้ cosine similarity 0.990 เทียบกับ 0.991 มี fused CUDA kernels และ Metal shaders รองรับทั้ง NVIDIA GPU และ Apple Silicon trade-off คือ MSE สูงกว่าบน random vectors แต่ real-model performance แข็งแกร่งด้วย [QJL] correction
การใช้ Clifford algebra ซึ่งเป็นคณิตศาสตร์จากทฤษฎี geometric algebra ในการ quantize โมเดลเป็นแนวทางที่ต่างออกไปจากวิธีมาตรฐาน Clifford rotors มีคุณสมบัติพิเศษที่สามารถแทน rotation ใน high-dimensional space ได้อย่างกะทัดรัด ทำให้ต้องการพารามิเตอร์น้อยกว่ามากในการบรรลุการ transform ที่เทียบเท่ากัน ผลลัพธ์ที่ได้คือ quantization matrix ที่คำนวณเร็วกว่ามาก ประสิทธิภาพ 10-19 เท่าเมื่อเทียบกับ [TurboQuant] บน use case ที่เหมาะสมนั้นเปิดโอกาสให้รัน long context บน edge device ที่มีข้อจำกัดพลังงานได้ การที่ [RotorQuant] ใช้พารามิเตอร์น้อยกว่า 44 เท่าในขณะที่ cosine similarity ต่างกันเพียง 0.001 (0.990 vs 0.991) แสดงว่า mathematical structure ที่เลือกมามีความเหมาะสมกับลักษณะของ weight distribution ใน LLM อย่างมาก
Hermes Agent ผนวก Hugging Face — 28 โมเดลพร้อมใช้งานทันที
[Nous Research] integrate [Hugging Face] เป็น first-class inference provider ใน Hermes Agent มี 28 โมเดลคัดเลือกพร้อมใช้ พร้อม memory ต่อเนื่อง, persistent machine access และสามารถเลือก model ได้ตาม workload ใช้งานง่ายกว่า browser-automation agent อย่าง [OpenClaw]
การที่ [Hugging Face] เป็น inference provider ใน Hermes Agent หมายความว่าผู้ใช้ไม่ต้องตั้ง inference server เองอีกต่อไป สามารถเลือกโมเดลจากรายการ 28 โมเดลที่คัดกรองมาแล้ว และ Hermes จะจัดการ routing ให้อัตโนมัติ ฟีเจอร์ persistent machine access ทำให้ agent สามารถทำงานข้ามเซสชันได้โดยไม่ต้อง setup ใหม่ทุกครั้ง ซึ่งสำคัญมากสำหรับงาน long-running tasks เช่น การวิเคราะห์ codebase ขนาดใหญ่หรือการรัน evaluation suite ที่ใช้เวลานาน ความสามารถในการสลับโมเดลตาม workload ยังช่วยควบคุมต้นทุนได้โดยใช้โมเดลใหญ่เฉพาะเมื่อจำเป็น การที่ [Nous Research] เลือก [Hugging Face] เป็น first-class partner สะท้อนว่า open-source model ecosystem กำลังกลายเป็น infrastructure สำคัญสำหรับ agentic workflows แทนที่จะเป็นแค่ทางเลือกราคาถูก
โครงสร้างพื้นฐาน Agent กำลังก้าวสู่วุฒิภาวะ
[Hugging Face] เรียกร้อง open agent traces datasets พร้อมแนะนำ Agent Data Protocol [LangChain] ออก agent eval readiness checklist, Deep Agents IDE UI และ [LangSmith] Prompt Hub สำหรับ prompt promotion และ rollback ทิศทางชัดเจน — agent กำลังเปลี่ยนจาก "chatbot with tools" เป็น software lifecycle primitives
Agent Data Protocol ที่ [Hugging Face] เสนอมีเป้าหมายสร้าง standard สำหรับ log การทำงานของ agent ซึ่งจำเป็นสำหรับการสร้าง dataset ฝึก agent รุ่นต่อไปให้ดีขึ้น ปัญหาปัจจุบันคือแต่ละบริษัทเก็บ trace ในรูปแบบที่ต่างกัน ทำให้ไม่สามารถ transfer learning ข้ามระบบได้ ในด้านของ [LangChain] การออก eval readiness checklist แสดงว่า community กำลังจริงจังกับการ test agent ก่อน deploy ในระบบ production ซึ่งแตกต่างจากยุคแรกที่ agent ถูก deploy แบบ trial-and-error [LangSmith] Prompt Hub ที่รองรับ promotion และ rollback นำแนวคิด [GitOps] มาใช้กับ prompt management ซึ่งเป็นสัญญาณว่า agentic software กำลังพัฒนาเป็นสาขาวิศวกรรมที่มี discipline เป็นของตัวเอง
AA-AgentPerf — Benchmark Agent จาก Trajectory จริง
Benchmark ใหม่ชื่อ AA-AgentPerf ใช้ real coding-agent trajectories ที่ sequence length เกิน 100K token วัด throughput เป็น concurrent users ต่อ accelerator ต่อ kW ต่อ dollar และต่อ rack สะท้อนต้นทุน deploy จริงมากกว่า synthetic token benchmarks
ความสำคัญของ AA-AgentPerf อยู่ที่มันวัด metric ที่ผู้ใช้จริงสนใจ ไม่ใช่ metric ที่ทดสอบง่าย synthetic benchmarks มักสั้นและ predictable ทำให้โมเดลที่ optimize เฉพาะ benchmark เหล่านั้นทำงานได้แย่กับ agent task จริงที่มี context ยาวและ decision branching ซับซ้อน การใช้ real trajectories จาก coding agents จึงสะท้อนความสามารถที่แท้จริงได้ดีกว่า นอกจากนี้การวัดเป็น concurrent users ต่อ kW ต่อ dollar ช่วยให้ทีม engineering ตัดสินใจเรื่อง infrastructure ได้แม่นยำขึ้น เพราะสามารถเปรียบเทียบ ROI ของ hardware ต่างรุ่นบน workload ที่ใกล้เคียงกับ production จริง AA-AgentPerf ยังช่วยเปิดเผยความแตกต่างระหว่างโมเดลที่ดูเหมือนกันบน leaderboard ทั่วไปแต่มีพฤติกรรมต่างกันมากเมื่อต้องรัน multi-step agent tasks ที่ context สะสมเกิน 100K token
Codex Ecosystem เข้าสู่ Workspace-Native
[OpenAI] นำเสนอ Codex plugins และ use-case gallery สำหรับ developer ecosystem ใหม่ [Box] ปล่อย Codex plugin สำหรับ automate งานเหนือ Box content center of gravity ของ Codex เลื่อนจาก prompt-response ไปสู่ persistent workspaces ที่มี PR flow, terminal และ plugins ฝังอยู่
การที่ [Box] เป็นหนึ่งในรายแรกที่ปล่อย Codex plugin แสดงให้เห็นว่า enterprise content management กำลังเชื่อมโยงกับ AI coding workflows โดยตรง ผู้ใช้สามารถ trigger code generation หรือ document automation จาก content ที่เก็บอยู่ใน Box ได้โดยไม่ต้องออกจาก workspace สิ่งที่น่าสนใจคือ paradigm ของ Codex กำลังเปลี่ยนจากเครื่องมือ autocomplete ธรรมดาไปเป็นระบบที่มี context เต็ม project สามารถสร้าง PR, รัน test ใน terminal และดึง plugin ภายนอกมาใช้ได้ภายใน session เดียว ทิศทางนี้ทำให้ Codex แข่งขันกับ full IDE environments อย่าง [VS Code] Copilot มากขึ้น use-case gallery ที่ [OpenAI] เพิ่งเปิดตัวยังเป็นพื้นที่ที่ developer สามารถแชร์ Codex workflow ที่ได้ผลจริงกับ community ซึ่งช่วยเร่ง adoption ในองค์กรที่ไม่รู้ว่าจะเริ่มต้นใช้งานจากตรงไหน
Meta SAM 3.1 — ประมวลผล 16 วัตถุพร้อมกัน เร็วขึ้น 2 เท่า
[Meta] SAM 3.1 เป็น drop-in update จาก SAM 3 มีฟีเจอร์ object multiplexing ที่ process สูงสุด 16 วัตถุใน forward pass เดียว Video segmentation throughput เพิ่มจาก 16 FPS เป็น 32 FPS บน H100 เป็น improvement ที่สำคัญสำหรับ production video pipelines
SAM หรือ Segment Anything Model เป็นโมเดล computer vision ที่ใช้แพร่หลายในงาน video analysis, robotics และ augmented reality การที่ SAM 3.1 เป็น drop-in update หมายความว่าทีมที่ใช้ SAM 3 อยู่แล้วสามารถอัปเกรดได้ทันทีโดยไม่ต้องเปลี่ยน pipeline การ double throughput จาก 16 เป็น 32 FPS บน H100 มีผลกระทบตรงต่อต้นทุน เพราะงานเดิมที่ต้องใช้ H100 สองตัวสามารถทำได้ด้วยตัวเดียว object multiplexing ที่รอง 16 วัตถุพร้อมกันในหนึ่ง forward pass ยังเปิดโอกาสใหม่ในงาน multi-object tracking เช่น การวิเคราะห์ฝูงชนหรือ warehouse robotics ที่ต้องติดตามวัตถุหลายชิ้นพร้อมกัน
LeWorldModel และ Open-Source Robotics
[LeCun] ปล่อย [LeWorldModel] ที่ใช้ [SIGReg] ป้องกัน representational collapse ทำ planning เร็วขึ้น 48 เท่า ใช้ token น้อยลง ~200 เท่า ในสัปดาห์เดียวกัน [Unitree] เปิด humanoid teleoperation dataset และ [AI2] ปล่อย [MolmoBot] สำหรับ robotic manipulation ทั้งหมด open-source
[LeWorldModel] ถูกออกแบบมาเพื่อแก้ปัญหา representational collapse ซึ่งเป็นปัญหาที่ world models มักเจอเมื่อ latent space ล้มลงและโมเดลไม่สามารถวางแผนระยะยาวได้ [SIGReg] เป็นเทคนิค regularization ที่ช่วยรักษา structure ของ representation ให้คงสภาพตลอดการ training ผลลัพธ์คือโมเดลที่ planning เร็วกว่าเดิมมากและใช้ token น้อยกว่า 200 เท่าซึ่งหมายถึงต้นทุน inference ที่ต่ำลงอย่างมีนัยสำคัญ สำหรับ [Unitree] การเปิด teleoperation dataset ช่วยให้ทีมวิจัยทั่วโลกฝึก imitation learning สำหรับ humanoid robot โดยไม่ต้องเก็บข้อมูลเอง ซึ่งเป็นข้อจำกัดสำคัญของการพัฒนา robotic AI มาโดยตลอด
Cohere Transcribe — 33 ชั่วโมงใน 12 นาที
โมเดล transcription ขนาด 2B พารามิเตอร์ จาก [Cohere] ภายใต้ลิขสิทธิ์ [Apache 2.0] สามารถถอดเสียง 33 ชั่วโมง เสร็จสิ้นใน 12 นาที บน A100 ตัวเดียว เร็วกว่า realtime ถึง ~165 เท่า
ความเร็ว 165x realtime บน A100 ตัวเดียวเป็นตัวเลขที่น่าประทับใจมากเมื่อเทียบกับ baseline อย่าง [Whisper] ของ [OpenAI] ที่มักทำงานในช่วง 10-50x realtime ขึ้นอยู่กับ model size ขนาด 2B พารามิเตอร์ถือว่ากะทัดรัดสำหรับ speech model ซึ่งทำให้สามารถ deploy บน server ราคาไม่แพงได้ ลิขสิทธิ์ Apache 2.0 เปิดให้นำไปใช้เชิงพาณิชย์ได้อย่างอิสระ ซึ่งต่างจาก proprietary transcription API ที่มีต้นทุนต่อชั่วโมง โมเดลนี้จึงน่าสนใจเป็นพิเศษสำหรับธุรกิจที่ต้องการถอดเสียงปริมาณมาก เช่น call center analytics, media transcription หรือ legal documentation
DGX Spark ปะทะ Mac Studio — รัน 397B ในราคา $10,000
สรุปการเปรียบเทียบ hardware สองตัวเลือกหลักในงบ ~$10,000: Mac Studio M3 Ultra 512GB ทำความเร็ว 30-40 tok/s, bandwidth ~800 GB/s, prefill ช้ากว่า ส่วน Dual DGX Spark ทำได้ 27-28 tok/s, prefill เร็วกว่า, มี CUDA tensor cores แต่ setup ซับซ้อนกว่า ทั้งคู่คืนทุนใน ~10 เดือน เมื่อเทียบกับค่า API ~$2,000 ต่อเดือน
ตัวเลขนี้อิงกับการรัน Qwen3.5 397B ซึ่งมีประสิทธิภาพใกล้เคียง Claude Opus บน coding tasks Mac Studio M3 Ultra มีข้อได้เปรียบด้าน unified memory ที่ทำให้ memory bandwidth สูงกว่าและ setup ง่ายกว่า ส่วน Dual DGX Spark มีข้อได้เปรียบด้าน CUDA ecosystem ที่มี library และ optimization tools มากกว่า สำหรับผู้ที่ใช้ open-source model เป็นหลัก Mac Studio M3 Ultra อาจเป็นตัวเลือกที่ดีกว่าในแง่ความสะดวก แต่ถ้าทีมคุ้นกับ CUDA workflow แล้ว DGX Spark ให้ prefill performance ที่ดีกว่าสำหรับงานที่ต้องประมวลผล prompt ยาวๆ บ่อยครั้ง
AI ช่วยออกแบบวัคซีน mRNA สำหรับรักษามะเร็งในสุนัข
Paul Conyngham ใช้ [ChatGPT] ออกแบบ mRNA vaccine protocol สำหรับมะเร็งในสุนัขของตัวเอง และ Sam Altman แชร์เรื่องราวนี้จนกลายเป็นประเด็นถกเถียงเรื่อง AI-enabled personalized medicine โดยเฉพาะคำถามว่าควรใช้ AI ในงานที่มีผลต่อชีวิตมากแค่ไหน
เรื่องของ Conyngham เป็นตัวอย่างที่แสดงให้เห็นว่า AI กำลัง democratize การเข้าถึงความรู้ทางการแพทย์เฉพาะทางในระดับที่ไม่เคยเกิดขึ้นมาก่อน การออกแบบ mRNA protocol ซึ่งเดิมต้องอาศัยทีมนักวิจัยและเวลาหลายเดือน กลายเป็นสิ่งที่บุคคลทั่วไปสามารถเข้าถึงแนวคิดเบื้องต้นได้ภายในชั่วโมง อย่างไรก็ตาม ผู้เชี่ยวชาญด้านชีวจริยธรรมชี้ว่าระหว่าง AI ที่ให้ framework กับการนำไปใช้จริงกับชีวิตยังมีช่องว่างของ clinical validation ที่ไม่ควรข้ามไป กรณีนี้จึงจุดชนวนถกเถียงที่กว้างกว่าแค่เรื่องสัตว์เลี้ยง นั่นคือเส้นแบ่งของความรับผิดชอบเมื่อ AI ให้คำแนะนำทางการแพทย์
แนวทาง Build เครื่องรัน LLM ในงบ $10,000
สำหรับผู้ที่ต้องการ build เครื่อง local inference ในงบ $10,000 ตัวเลือกหลักได้แก่: RTX 4090 (24GB VRAM ต่อการ์ด), A6000/A40 มือสอง (48GB ต่อการ์ด), Mac Studio M3 Ultra (512GB unified memory) และ 2x DGX Spark (รัน Qwen3.5-122B ที่ ~40 tok/s) คำแนะนำคือต้องมี VRAM หรือ unified memory อย่างน้อย 256GB สำหรับโมเดลระดับ frontier
สำหรับการ build PC ด้วย discrete GPU A6000 มือสองราคาประมาณ $3,000-4,000 ต่อใบเป็นตัวเลือกที่คุ้มค่าที่สุดในแง่ VRAM ต่อดอลลาร์ สองใบรวมกันได้ 96GB ในราคาไม่ถึง $8,000 ส่วน RTX 4090 แพงกว่าต่อ GB แต่มี tensor cores รุ่นใหม่ที่เร็วกว่า ข้อควรระวังสำหรับ multi-GPU setup คือ bandwidth ระหว่าง GPU ผ่าน PCIe ต่ำกว่า NVLink มาก ซึ่งอาจเป็น bottleneck สำหรับโมเดลที่ต้องการ all-reduce บ่อย นอกจากนี้ ชิป M5 Ultra ของ Apple คาดว่าจะเปิดตัวกลางปี 2569 อาจมี unified memory สูงถึง 512GB+ พร้อม bandwidth ที่สูงกว่า M3 Ultra ซึ่งจะเปลี่ยน price/performance landscape อีกครั้ง
ภาพรวม — GPU Economics เปลี่ยนเกม
ธีมหลักของสัปดาห์นี้คือ เศรษฐศาสตร์ GPU กำลังเปลี่ยนทิศ H100 ที่เคยคิดว่าจะค่อยๆ เสื่อมมูลค่า กลับแข็งค่าขึ้นเพราะ reasoning model และ AI agent ต้องการ compute ยาวนานกว่าที่คาด Anthropic เตรียมโมเดลยักษ์ Capybara ที่อาจเป็น leap ครั้งใหญ่ แต่ต้องแก้ปัญหา infrastructure ที่ทำให้ Error 529 พุ่งก่อน
ในขณะเดียวกัน โมเดลเปิดจากจีนอย่าง GLM-5.1 ไล่จี้ Claude ใน coding benchmark จนเหลือช่องว่างเพียง 2.6 คะแนน สะท้อนว่าความได้เปรียบของ closed-source western models กำลังแคบลงอย่างมีนัยสำคัญ Quantization techniques อย่าง TurboQuant และ RotorQuant ทำให้โมเดลใหญ่รันบนเครื่องเล็กได้จริงในทางปฏิบัติ ไม่ใช่แค่ในทาง theoretical และ agent infrastructure กำลังเติบโตเป็นผู้ใหญ่ด้วย eval frameworks, trace datasets และ production-grade tooling ที่เริ่มมี standard เป็นของตัวเอง ทั้งหมดนี้ชี้ว่า AI ในปี 2569 กำลังเดินหน้าพร้อมกันทั้งในแนวรุก frontier model ขนาดยักษ์ และแนวกระจาย local deployment ที่เข้าถึงได้มากขึ้น
ข้อมูล ณ วันที่ 28 มีนาคม 2569 — บทความนี้จัดทำขึ้นเพื่อให้ข้อมูลเท่านั้น ไม่ได้เป็นคำแนะนำด้านการลงทุนแต่อย่างใด