
สรุปข่าว AI: Claude ปล่อยฟีเจอร์รัวทั้งสัปดาห์, ARC-AGI-3 โมเดลทำได้ไม่ถึง 1%, Sora ปิดตัว, Intel GPU 32GB
Anthropic ปล่อยฟีเจอร์ใหม่ Claude รัวทั้งสัปดาห์ — Channels, Dispatch, Computer Use และอีกมาก
สัปดาห์ที่ผ่านมาถือเป็นหนึ่งในช่วงเวลาที่คึกคักที่สุดในประวัติศาสตร์ของ Anthropic เมื่อบริษัทเปิดตัวฟีเจอร์ใหม่สำหรับ Claude พร้อมกันหลายตัวในคราวเดียว จนทีมภายในเรียกสัปดาห์นี้ว่า "Claude Launch Week" อย่างไม่เป็นทางการ ฟีเจอร์ที่ปล่อยออกมาประกอบด้วย [Channels] สำหรับการสื่อสารแบบช่องทาง, [Dispatch] สำหรับการสั่งงานระยะไกล, [Projects] สำหรับจัดการโปรเจกต์ระยะยาว, [Computer Use] สำหรับควบคุมคอมพิวเตอร์โดยตรง, [Auto Mode] สำหรับการทำงานอัตโนมัติ และการรองรับ [iMessage] เพื่อขยายช่องทางการสื่อสาร
ฟีเจอร์เหล่านี้ไม่ได้เป็นเพียงการอัปเดตเล็กน้อย แต่แต่ละตัวสะท้อนทิศทางกลยุทธ์ที่ชัดเจนของ Anthropic ในการขยาย Claude จาก [chatbot] ทั่วไปสู่แพลตฟอร์มที่ใช้งานได้จริงในระดับองค์กร [Channels] เปิดให้ทีมงานสร้างช่องการสนทนาแบบ [persistent] ที่ Claude เข้าถึงได้ตลอดเวลา ช่วยลดปัญหา [context loss] ที่เคยเป็นอุปสรรคสำคัญในการใช้งานแบบองค์กร เพราะแต่เดิมทุกครั้งที่เริ่ม [session] ใหม่ Claude จะ "ลืม" บริบทของโปรเจกต์ทั้งหมด
[Dispatch] ก้าวไปอีกขั้นด้วยการให้ผู้ใช้ส่งงานไปยัง Claude แบบ [asynchronous] และรับผลลัพธ์กลับมาในภายหลัง เหมาะกับงานที่ต้องใช้เวลานานหรืองานที่ต้องการให้ Claude ทำงานในพื้นหลังขณะที่ผู้ใช้ทำงานอื่น ส่วน [Projects] ช่วยให้ Claude รักษาความรู้เกี่ยวกับโปรเจกต์เฉพาะไว้ได้ระยะยาว รวมถึงความเข้าใจเรื่องโครงสร้างโค้ด ความต้องการของลูกค้า และมาตรฐานการทำงานของทีม
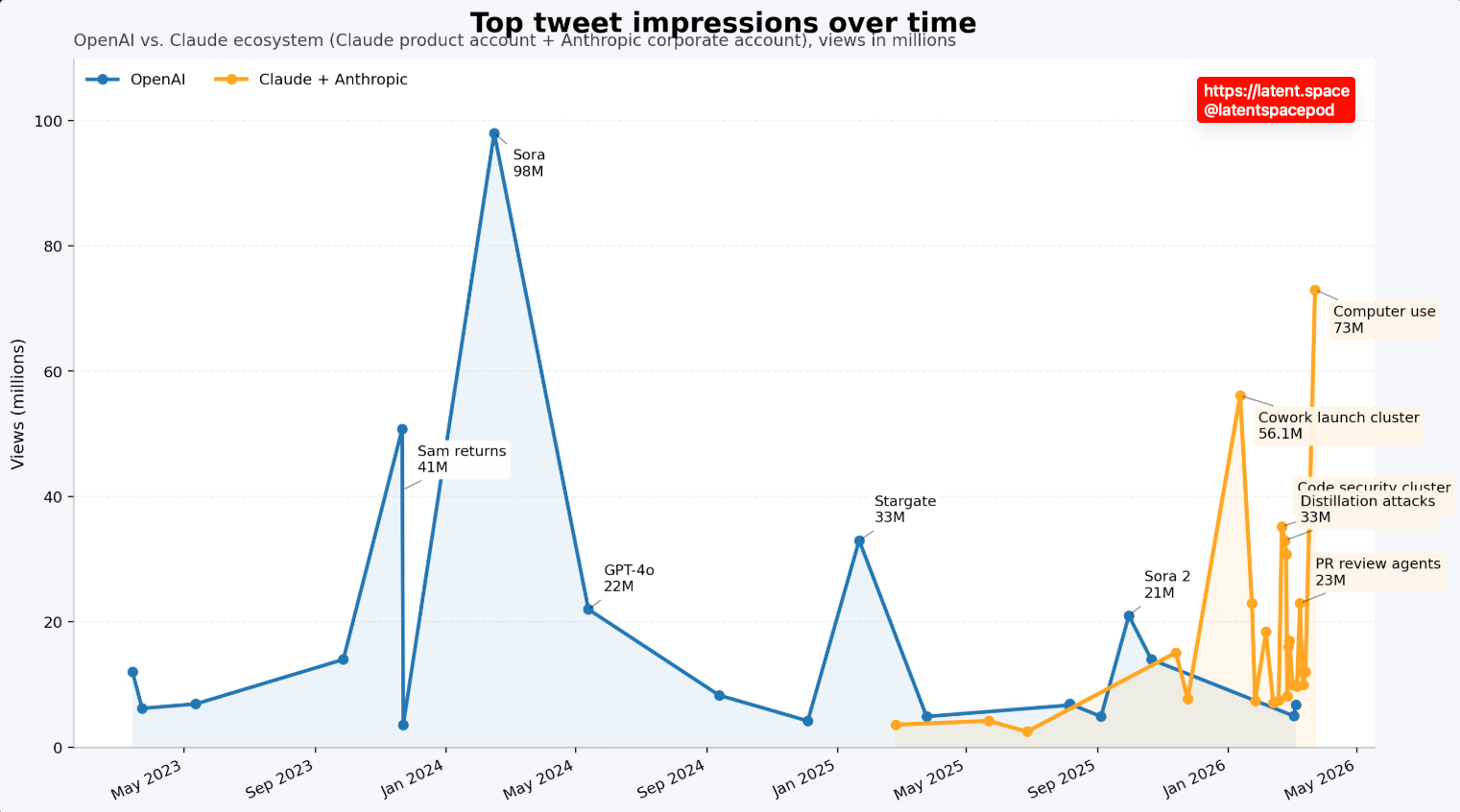
ตัวเลข [impressions] ของ Claude บนแพลตฟอร์มโซเชียลมีเดียพุ่งสูงขึ้นอย่างมีนัยสำคัญในสัปดาห์นี้ สูงกว่าสถิติเดิมที่บัญชี [Codex] ของ [OpenAI] เคยทำไว้ที่ 2.5 ล้านครั้ง นักวิเคราะห์หลายรายมองว่าทิศทางนี้กำลังมุ่งสู่การเป็น [super-app] ที่รวมการสนทนา การทำงานอัตโนมัติ และการควบคุมอุปกรณ์ไว้ในที่เดียว สิ่งที่น่าสังเกตอีกประการคือจังหวะการพัฒนาแบบ [self-recursive development] ที่ [Claude Code] ช่วยเขียนโค้ดสำหรับฟีเจอร์ใหม่ของตัวเอง กลายเป็นวงจรเร่งตัวเองที่อาจยิ่งเพิ่มความเร็วในการพัฒนาต่อไปอีก
ARC-AGI-3 เปิดตัว — โมเดล AI ระดับแนวหน้าทำคะแนนได้ไม่ถึง 1%
François Chollet และทีม [ARC Prize] เปิดตัว [ARC-AGI-3] เบนช์มาร์กรุ่นใหม่ที่ออกแบบมาเพื่อวัดความสามารถในการคิดเชิงนามธรรมของ [AI] ในรูปแบบที่แตกต่างจากเวอร์ชันก่อนหน้าอย่างสิ้นเชิง แทนที่จะเป็นการแก้ปริศนาภาพนิ่งแบบเดิมที่ทำกันมา [ARC-AGI-3] ใช้สภาพแวดล้อมแบบ [interactive] ที่ผู้ทดสอบต้องแก้ปริศนาและเล่นเกมโดยอาศัยการตัดสินใจแบบ [real-time] ผ่านการส่ง [input] และรับ [feedback] วนซ้ำ ผลลัพธ์สร้างความตกตะลึงในวงการ — มนุษย์สามารถแก้โจทย์ได้ 100% ของงานทั้งหมด ขณะที่ โมเดล [AI] ระดับ [frontier] ทำคะแนนได้ไม่ถึง 1%
สิ่งที่ [ARC-AGI-3] วัดคือความสามารถในการ [generalize] แบบไม่ต้องเตรียมตัวล่วงหน้า ([zero-preparation generalization]) ซึ่งหมายความว่าโมเดลต้องเผชิญกับสถานการณ์ที่ไม่เคยเห็นมาก่อน และต้องสร้างกลยุทธ์ใหม่ในทันที แทนที่จะพึ่งพาการจดจำรูปแบบจากข้อมูล [training] ที่มีอยู่ ความแตกต่างนี้สำคัญมาก เพราะ [AI] ยุคปัจจุบันเก่งมากในการจดจำและนำรูปแบบที่เคยเห็นมาใช้ แต่ยังอ่อนแอในการสร้างกลยุทธ์ใหม่จากสถานการณ์ที่ไม่คุ้นเคย
ระบบการให้คะแนนเป็นแบบ [efficiency-based] ที่เปรียบเทียบกับจำนวนการกระทำของมนุษย์ที่เก่งเป็นอันดับสอง ทำให้วัดได้ทั้งความถูกต้องและประสิทธิภาพในการใช้ทรัพยากรไปพร้อมกัน ไม่ใช่แค่วัดว่าผ่านหรือไม่ผ่านเท่านั้น เกิดข้อถกเถียงในชุมชนเรื่องวิธีการให้คะแนน เนื่องจากโปรโตคอลใหม่ทำให้ตัวเลข "ต่ำกว่า 1%" นั้นยากที่จะเปรียบเทียบโดยตรงกับ [ARC] เวอร์ชันก่อนหน้า Chollet ชี้แจงว่านี่เป็นความตั้งใจ เพราะสภาพแวดล้อมที่แตกต่างกันอย่างสิ้นเชิงทำให้การเทียบตัวเลขโดยตรงไม่มีความหมาย
แม้แต่นักวิจารณ์ที่ตั้งคำถามเรื่องวิธีคะแนนก็ยังยอมรับว่าเบนช์มาร์กนี้เปิดเผยจุดอ่อนที่แท้จริงของ [LLM agents] ในสภาพแวดล้อมแบบ [interactive] ที่มี [feedback] เบาบาง นัยที่สำคัญที่สุดของผลลัพธ์นี้คือช่องว่างขนาดใหญ่ยังคงอยู่ระหว่างการ "ดูฉลาด" ในการสนทนาทั่วไปกับการ "คิดและปรับตัวได้จริง" เมื่อเผชิญสถานการณ์ใหม่ที่ไม่คุ้นเคย
โครงสร้างพื้นฐาน Agent เข้มข้นขึ้น — LangChain, Cursor, Imbue, Sierra ปล่อยเครื่องมือใหม่
สัปดาห์นี้เป็นสัปดาห์สำคัญสำหรับโครงสร้างพื้นฐานด้าน [AI agent] โดยมีการเปิดตัวเครื่องมือใหม่จากหลายบริษัทพร้อมกัน สะท้อนให้เห็นว่าตลาดกำลังเคลื่อนจากการพัฒนาโมเดล [AI] ไปสู่การสร้างระบบนิเวศที่ช่วยให้ [agent] ทำงานในโลกจริงได้อย่างมีประสิทธิภาพและน่าเชื่อถือ
- [LangChain] เปิดตัว [Fleet] shareable skills — [registry] สำหรับ [domain knowledge] ที่ใช้ซ้ำข้าม [agent] ได้ ช่วยลดการเขียนโค้ดซ้ำและให้ทีมพัฒนาแชร์ความรู้เฉพาะทางระหว่างโปรเจกต์ได้ง่ายขึ้น ก่อนหน้านี้การสร้าง [agent] ใหม่แต่ละตัวมักต้องสร้างทักษะเฉพาะทางตั้งแต่ต้น
- Anthropic เผยแพร่รายละเอียดวิธีการทำงานของ [Claude Code auto mode] — ระบบใช้ [classifier] เป็นตัวกลางในการอนุมัติแต่ละขั้นตอน ซึ่งเป็นแนวทางที่ช่วยให้ [agent] ทำงานได้อย่างปลอดภัยโดยไม่ต้องรอการยืนยันจากมนุษย์ในทุกครั้ง แต่ยังคงความโปร่งใสในการตัดสินใจ
- [Browserbase] ร่วมมือกับ [Prime Intellect] พัฒนาการฝึก [browser agent] บน [BrowserEnv] เพื่อให้ [agent] สามารถนำทางและทำงานบนเว็บไซต์ได้อย่างแม่นยำมากขึ้น โดยใช้ [reinforcement learning] จากสภาพแวดล้อมเบราว์เซอร์จริง
- [Cursor] เปิดตัว [self-hosted cloud agents] ที่ให้การประมวลผลอยู่ภายในเครือข่ายของลูกค้าองค์กร แก้ปัญหาด้านความเป็นส่วนตัวและ [compliance] ที่เคยขัดขวางการนำ [AI coding tools] มาใช้ในองค์กรขนาดใหญ่ โดยเฉพาะในอุตสาหกรรมที่มีกฎระเบียบเข้มงวด
- [Imbue] ปล่อย [Keystone] — [agent] ที่สร้าง [dev containers] สำหรับ [repo] ใดก็ได้อัตโนมัติ ลดเวลา [onboarding] สำหรับนักพัฒนาใหม่จากหลายชั่วโมงเหลือเพียงไม่กี่นาที เพราะ [Keystone] จะวิเคราะห์ [repo] และตั้งค่าสภาพแวดล้อมพัฒนาที่เหมาะสมให้โดยอัตโนมัติ
- [Sierra] เปิดตัว [Ghostwriter] — "agent สำหรับสร้าง agents" ที่เน้น [customer experience] [Ghostwriter] ช่วยบริษัทออกแบบและปรับแต่ง [AI agent] สำหรับงาน [customer service] โดยเฉพาะ ลดความต้องการผู้เชี่ยวชาญด้าน [AI] ในองค์กร
แนวโน้มที่เห็นชัดจากเครื่องมือเหล่านี้คือการเปลี่ยนจาก [framework] แบบเปิดกว้างที่ให้นักพัฒนาประกอบทุกอย่างเอง มาเป็นเครื่องมือที่มี "ความคิดเห็น" ชัดเจนว่า [agent] ควรทำงานอย่างไร สะท้อนการเติบโตของตลาด [AI agent] จากระยะทดลองสู่ระยะใช้งานจริงในองค์กรที่ต้องการความน่าเชื่อถือและความสม่ำเสมอ
OpenAI ปิดตัว Sora — ขาดทุนวันละ 5 แสนดอลลาร์ ย้ายทรัพยากรไป Coding
[OpenAI] ประกาศยุติ [Sora] แพลตฟอร์มสร้างวิดีโอด้วย [AI] อย่างเป็นทางการ ถือเป็นการปิดฉากของผลิตภัณฑ์ที่เคยสร้างความฮือฮาอย่างมากตั้งแต่ตอนเปิดตัวเมื่อต้นปีก่อน ตัวเลขที่หลุดออกมาจากภายในชี้ว่า [Sora] กำลัง ขาดทุนราว 5 แสนดอลลาร์ต่อวัน (ประมาณ 17.5 ล้านบาท) เนื่องจากต้นทุนการประมวลผลสำหรับการสร้างวิดีโอสูงกว่าที่ประมาณการไว้มาก และยากที่จะลดลงได้ในระยะเวลาอันใกล้ด้วยเทคโนโลยีปัจจุบัน
สิ่งที่น่าแปลกใจคือแม้แต่ความร่วมมือระดับพันล้านดอลลาร์กับ [Disney] ซึ่งได้รับสิทธิ์ใช้ตัวละครกว่า 200 ตัวสำหรับสร้างคอนเทนต์ด้วย [AI] ก็ไม่สามารถพลิกสถานการณ์ทางการเงินได้ นักวิเคราะห์ชี้ว่าปัญหาหลักคือช่องว่างที่ใหญ่เกินไประหว่างต้นทุนต่อคลิปกับราคาที่ผู้ใช้ทั่วไปและผู้สร้างคอนเทนต์ยอมจ่าย ในขณะที่คู่แข่งอย่าง [Runway] และ [Kling] สามารถควบคุมต้นทุนได้ดีกว่าและให้คุณภาพที่เพียงพอสำหรับความต้องการส่วนใหญ่
[OpenAI] ตัดสินใจโยกทรัพยากรทั้งด้านวิศวกรและโครงสร้างพื้นฐาน [compute] จาก [Sora] ไปสู่ด้าน [coding] และ [enterprise] ซึ่งมีอัตรากำไรสูงกว่าและมีความต้องการจากตลาดที่ชัดเจนกว่า การปิด [Sora] ยืนยันอีกครั้งว่าแม้แต่บริษัท [AI] ระดับแนวหน้าก็ต้องเลือกสนามรบที่ตัวเองมีความได้เปรียบ การเป็นผู้บุกเบิกเทคโนโลยีไม่ได้รับประกันความสำเร็จทางธุรกิจ [compute] ที่ถูกปลดปล่อยจาก [Sora] คาดว่าจะถูกนำไปใช้กับโมเดลใหม่รหัส "Spud"
OpenAI "Spud" — โมเดลใหม่ที่อาจเปลี่ยนเกม
[OpenAI] เสร็จสิ้นการ [pretrain] โมเดลใหม่รหัส "Spud" แล้ว ข้อมูลที่ไหลออกมาจากแหล่งข่าวภายในชี้ว่า [Spud] อาจเป็นก้าวกระโดดสำคัญในด้าน [base model] ซึ่งเป็นจุดที่ [OpenAI] เคยถูกวิจารณ์ว่าตามหลังคู่แข่งในช่วงที่ผ่านมา [Sam Altman] กำลังเปลี่ยนโฟกัสองค์กรจากการเน้นประเด็น [safety] มาสู่การเร่ง [scaling] มากขึ้น สะท้อนการแข่งขันที่เข้มข้นกับ [Anthropic], [Google DeepMind] และ [DeepSeek]
[Dylan Patel] นักวิเคราะห์จาก [SemiAnalysis] ซึ่งติดตามอุตสาหกรรม [semiconductor] และ [AI] อย่างใกล้ชิดให้ความเห็นว่า [OpenAI] มี [Reinforcement Learning] ที่ดีที่สุดในอุตสาหกรรม แต่เคยมีจุดอ่อนเรื่อง [pretrained model] ที่ไม่แข็งแกร่งพอเมื่อเทียบกับ [Gemini Ultra] และ [Claude 3.7] ถ้า [Spud] แก้ปัญหา [base model] ได้ และนำมารวมกับความเชี่ยวชาญด้าน [RL] ที่มีอยู่แล้ว ผลลัพธ์อาจสร้างความเปลี่ยนแปลงอย่างมีนัยสำคัญในอันดับ [benchmark] ทั่วโลก และอาจพลิกสมดุลการแข่งขันในอุตสาหกรรมที่กำลังเดือดนี้
GigaChat 3.1 Ultra 702B — โมเดลยักษ์จากรัสเซียเปิดน้ำหนักแบบเสรี
รัสเซียก้าวเข้าสู่เวที [AI] โอเพนซอร์สระดับโลกด้วย [GigaChat] 3.1 Ultra ขนาด 702 พันล้านพารามิเตอร์แบบ [MoE] (Mixture of Experts) เผยแพร่ภายใต้สัญญาอนุญาต [MIT] ซึ่งเป็นหนึ่งในสัญญาอนุญาตที่ยืดหยุ่นที่สุดในวงการซอฟต์แวร์เปิด นักพัฒนาจึงสามารถนำไปใช้ในเชิงพาณิชย์ได้อย่างอิสระโดยไม่มีข้อจำกัดพิเศษ โมเดลอ้างว่าเอาชนะ [DeepSeek-V3-0324] และ [Qwen3-235B] ใน [MMLU] ภาษารัสเซียและ [Math 500] ซึ่งหากเป็นจริงจะเป็นโมเดลที่แข็งแกร่งมากสำหรับงานภาษารัสเซียโดยเฉพาะ
นอกจาก [Ultra] แล้วยังมี [Lightning model] ขนาด 10B พารามิเตอร์ (active 1.8B) สำหรับ [inference] บนเครื่องส่วนตัว ทำให้นักพัฒนาที่ไม่มีทรัพยากรระดับ [datacenter] ก็สามารถทดลองใช้งานได้ การออกแบบแบบ [MoE] ทำให้ขนาดพารามิเตอร์ที่ใช้จริงระหว่าง [inference] น้อยกว่าตัวเลข 702B มาก โมเดลรองรับ 14 ภาษา แม้ว่าประสิทธิภาพจะเด่นชัดที่สุดในภาษารัสเซีย
อย่างไรก็ตามมีข้อกังวลที่ควรพิจารณาก่อนนำไปใช้งาน เนื่องจากผู้พัฒนาหลักคือ [Sber] ซึ่งเป็นธนาคารของรัฐรัสเซียที่อยู่ภายใต้การกำกับดูแลของรัฐบาล คำถามเรื่อง [bias] ทางการเมือง การกรองเนื้อหาในหัวข้อละเอียดอ่อนที่เกี่ยวกับรัสเซีย และความเป็นอิสระจากการควบคุมของรัฐบาลยังต้องการการตรวจสอบจากชุมชนอิสระอย่างละเอียด ชุมชนนักพัฒนา [AI] กำลังติดตามว่าการทดสอบอิสระจะยืนยันผลลัพธ์ที่ [Sber] อ้างหรือไม่
Google Lyria 3 Pro — สร้างเพลงด้วย AI ยาวถึง 3 นาที ราคาเริ่มต้น 1.40 บาท
[Google] เปิดตัว [Lyria] 3 Pro ซึ่งเป็นการอัปเกรดครั้งสำคัญของโมเดลสร้างเพลงด้วย [AI] โดยขยายความยาวสูงสุดจาก 30 วินาทีเป็น 3 นาทีเต็ม ซึ่งเพียงพอสำหรับเพลงที่สมบูรณ์ในรูปแบบทั่วไป การเพิ่มความยาวนี้ไม่ใช่เรื่องง่าย เพราะโมเดลต้องรักษาความสอดคล้องทางดนตรีตลอดทั้งเพลง ทั้งในแง่ [melody], [harmony], [rhythm] และ [timbre]
[Lyria 3 Pro] ยังควบคุมโครงสร้างเพลงได้ในระดับละเอียด ครอบคลุม [intro], [verse], [chorus], [bridge] และ [outro] ทำให้ผู้ใช้สามารถระบุได้ว่าต้องการให้แต่ละส่วนของเพลงเป็นแบบไหน ฟีเจอร์เพิ่มเติมที่น่าสนใจได้แก่ [tempo control] สำหรับควบคุมจังหวะ, [time-aligned lyrics] สำหรับซิงค์เนื้อเพลงกับจังหวะดนตรีอย่างแม่นยำ, [image-to-music] สำหรับสร้างเพลงที่สื่ออารมณ์จากภาพ และลายน้ำ [SynthID] สำหรับระบุว่าเพลงสร้างด้วย [AI] เพื่อความโปร่งใส ในด้านราคาอยู่ที่ $0.08 ต่อเพลง (Pro) และ $0.04 ต่อเพลง (Clip) ใช้งานผ่าน [Gemini], [Google AI Studio] และ [Gemini API] การเปิดตัวนี้วางตำแหน่ง [Google] ให้แข่งขันโดยตรงกับ [Suno] และ [Udio] ซึ่งครองตลาด [AI music generation] อยู่
LongCat-Next จาก Meituan — โมเดล Multimodal 68.5B รวมภาพ เสียง ภาษา
[Meituan] บริษัทเทคโนโลยีจากจีนที่รู้จักกันในฐานะแพลตฟอร์มส่งอาหารและบริการท้องถิ่น เปิดตัว [LongCat-Next] โมเดลขนาด 68.5 พันล้านพารามิเตอร์แบบ [MoE] ที่มี [active parameters] เพียง 3 พันล้านในระหว่าง [inference] ทำให้ต้นทุนการใช้งานต่ำกว่าขนาดพารามิเตอร์รวมมาก โมเดลใช้สถาปัตยกรรม [discrete-native autoregressive] ที่รวม [token] จากภาษา ภาพ และเสียงไว้ใน [token space] เดียวกัน แทนที่จะแยกแต่ละ [modality] ออกจากกันแล้วค่อยรวมทีหลัง
จุดเด่นทางเทคนิคที่สำคัญคือการใช้ [dNaViT] สำหรับ [any-resolution vision tokenizing] ซึ่งทำให้โมเดลรับภาพที่มีความละเอียดและอัตราส่วนต่างกันได้โดยไม่ต้องปรับขนาดหรือตัดภาพ ส่งผลให้ประสิทธิภาพด้าน [OCR] และการเข้าใจ [GUI] ([graphical user interface]) สูงกว่าโมเดลที่จำกัดความละเอียด [input] นอกจากนี้ [LongCat-Next] ยังรองรับ [image generation] และ [speech synthesis] ทำให้เป็นโมเดลแบบ [any-to-any] ที่ครบถ้วน ซึ่งยังหาได้ยากในโมเดลโอเพนซอร์สทั่วไป การเปิดตัวนี้แสดงให้เห็นว่าบริษัทเทคโนโลยีจีนนอกกลุ่ม [AI] หลักอย่าง [Alibaba] หรือ [Baidu] ก็กำลังลงทุนอย่างจริงจังในการวิจัย [foundational AI]
Sakana AI Scientist ตีพิมพ์ใน Nature — หลักฐาน "Scaling Law ของวิทยาศาสตร์"
ระบบ "The AI Scientist" ของ [Sakana AI] ซึ่งเป็นบริษัทสตาร์ทอัพจากญี่ปุ่นที่ก่อตั้งโดยอดีตนักวิจัยจาก [Google DeepMind] ได้รับการตีพิมพ์งานวิจัยในวารสาร [Nature] หนึ่งในวารสารวิชาการที่มีอิทธิพลสูงสุดในโลก การตีพิมพ์ในวารสารระดับนี้ไม่ใช่เรื่องเล็กน้อย เพราะกระบวนการ [peer review] ของ [Nature] เข้มงวดมาก และสะท้อนว่างานนี้มีคุณภาพถึงระดับที่ชุมชนวิทยาศาสตร์กระแสหลักยอมรับ
ระบบนี้ทำงาน [end-to-end] ครอบคลุมทุกขั้นตอนของกระบวนการวิจัย ตั้งแต่การสร้างสมมติฐาน ออกแบบการทดลอง เขียนโค้ดทดสอบ ดำเนินการทดลอง วิเคราะห์ผลลัพธ์ เขียนบทความวิชาการ จนถึง [peer review] อัตโนมัติ สิ่งที่น่าสนใจที่สุดคือหลักฐานของ "scaling law ของวิทยาศาสตร์" ซึ่งชี้ว่ายิ่ง [foundation model] ที่ใช้เป็นฐานมีความสามารถสูงขึ้น บทความวิชาการที่ [AI] สร้างก็ยิ่งมีคุณภาพสูงขึ้นตาม สร้างวงจรเร่งตัวเองที่อาจส่งผลกระทบต่อการวิจัยทางวิทยาศาสตร์อย่างลึกซึ้ง แม้จะยังมีข้อถกเถียงเรื่องความคิดสร้างสรรค์และความเป็นต้นฉบับของงานวิจัยที่ [AI] สร้างเมื่อเทียบกับนักวิทยาศาสตร์มนุษย์
Intel Arc Pro B70 — VRAM 32GB ราคาต่ำกว่า 1,000 ดอลลาร์
[Intel] เปิดตัว [Arc Pro B70] ในราคา 949 ดอลลาร์ (ราว 33,000 บาท) มาพร้อม [VRAM] 32GB [GDDR6], แบนด์วิดท์ 608 GB/s, [TDP] 290W ประสิทธิภาพ [int8] อยู่ที่ 387 [TOPS] เมื่อเทียบกับ [RTX 4000 PRO] ของ [NVIDIA] ที่ทำได้ 1,290 [TOPS] ทำให้ชัดเจนว่า [Arc Pro B70] ไม่ได้แข่งขันในแง่ความเร็วประมวลผลต่อใบ แต่แข่งขันในมิติที่ต่างออกไป
จุดขายที่ [Intel] เน้นคือ ราคาต่อ [VRAM] ที่ดีที่สุดในตลาด ณ ราคานั้น นักพัฒนาที่ต้องการรัน [large language model] ขนาด 70B พารามิเตอร์ทั้งตัวต้องการ [GPU memory] อย่างน้อย 80-140 GB ขึ้นอยู่กับ [quantization] ที่ใช้ ซึ่งปกติต้องใช้ [A100] หรือ [H100] ราคาหลายหมื่นดอลลาร์ต่อใบ แต่การซื้อ [Arc Pro B70] 4 ใบในราคา 4,000 ดอลลาร์ = 128GB GPU memory ทำให้สามารถรันโมเดล 70B ทั้งตัวได้ในงบประมาณที่เข้าถึงได้สำหรับทีมขนาดเล็กหรือนักวิจัยรายบุคคล [Intel] ยังร่วมมือกับ [vLLM] ให้รองรับตั้งแต่วันแรก อย่างไรก็ตาม [software stack] ที่ยังตามหลัง [CUDA] ของ [NVIDIA] อยู่มากจะเป็นอุปสรรคสำคัญสำหรับการนำไปใช้ในวงกว้าง
สนามรบ Inference — Mamba2 187 tok/s ถึง 625K context, WebGPU 24B ในเบราว์เซอร์
ด้าน [inference efficiency] มีพัฒนาการสำคัญหลายด้านพร้อมกันในสัปดาห์นี้ ความก้าวหน้าเหล่านี้มีความสำคัญไม่แพ้การพัฒนาโมเดลใหม่ เพราะ [inference] คือต้นทุนหลักของการให้บริการ [AI] จริง
[NVIDIA Mamba2 Nemotron Cascade 2] ทำความเร็วคงที่ที่ 187 [tok/s] แม้ขยาย [context] ถึง 625K [tokens] บน [RTX 3090] ซึ่งเป็นความสำเร็จที่น่าประทับใจ เพราะโมเดลแบบ [Transformer] ทั่วไปจะช้าลงแบบ [quadratic] เมื่อ [context] ยาวขึ้น สถาปัตยกรรม [Mamba] ที่ใช้ [state space model] แทน [self-attention] จึงเหมาะกับงานที่ต้องการ [context] ยาวมากอย่างการวิเคราะห์เอกสารยาวหรือการสนทนาระยะยาว
[Cursor Composer 2] เลือกใช้ [Fireworks] สำหรับ [RL inference] เพราะวัดได้ว่าเร็วกว่า [SGLang] และ [TRT] อย่างมีนัยสำคัญในงานประเภทนี้ [Google TurboQuant] สามารถลด [KV-cache memory] ได้ถึง 6 เท่าโดยไม่กระทบคุณภาพเอาต์พุต ซึ่งช่วยลดต้นทุน [inference] ได้อย่างมาก [vLLM] เวอร์ชันล่าสุดสามารถจัดการ [KV-cache tokens] ได้มากกว่า 4 ล้าน [tokens] และที่น่าทึ่งที่สุดคือโมเดลขนาด 24B รันในเบราว์เซอร์ผ่าน [WebGPU] ที่ 50 [tok/s] บน [M4 Max] ซึ่งแสดงให้เห็นว่า [AI] ระดับสูงสามารถทำงานบนอุปกรณ์ส่วนตัวได้โดยไม่ต้องพึ่ง [server] ภายนอก ลดความกังวลเรื่องความเป็นส่วนตัวของข้อมูลได้อย่างมาก
Claude Code — ผู้ใช้ร้องเรียน Usage Limits ถูกลดอย่างเงียบ ๆ
เกิดกระแสวิจารณ์จากผู้ใช้ [Claude Code] เรื่อง [usage limits] ที่ดูเหมือนถูกลดลงอย่างมีนัยสำคัญโดยไม่มีประกาศอย่างเป็นทางการล่วงหน้า ทำให้ผู้ใช้จำนวนมากพบว่าโควต้าการใช้งานของตัวเองหมดเร็วกว่าที่เคยเป็นมากโดยไม่ทราบสาเหตุ ปัญหาที่รายงานพบบ่อยที่สุดคือ [session] เก่าที่ [cache] หมดอายุแล้วต้อง [rewrite] ใหม่ทั้งหมด ซึ่งกินโควต้าไปมาก เพียงแค่พิมพ์ "hey" ใน [session] เก่าที่ [cache] หมดอายุ ก็ใช้ [limit] ไปได้ถึง 22% ทันที
ปัญหาซับซ้อนขึ้นจากระบบ [cache] ที่หมดอายุเร็ว — 5 นาทีสำหรับผู้ใช้ [Pro] และ 1 ชั่วโมงสำหรับผู้ใช้ [Max] เมื่อ [cache] หมดอายุ ระบบต้อง [rewrite] โดยมีต้นทุนสูงกว่าปกติ 1.25 เท่า นอกจากนี้ระบบ [rolling window] 5 ชั่วโมงยังสร้างความสับสนเรื่อง [rollover charging] ที่ผู้ใช้คาดการณ์ได้ยาก ผู้ใช้ที่จ่ายค่า [Max 5x/20x] ซึ่งเป็นแพ็คเกจระดับสูงสุดและราคาแพงที่สุดก็ยังถูกจำกัดการใช้งานอย่างรวดเร็ว [Anthropic] ยังไม่มีการตอบสนองอย่างเป็นทางการต่อข้อร้องเรียนเหล่านี้ ซึ่งสร้างความไม่พอใจในหมู่ผู้ใช้ระดับพรีเมียม
Claude Code /dream — ระบบ "AI REM Sleep" จัดการหน่วยความจำ
ฟีเจอร์ใหม่ /dream ของ [Claude Code] ได้รับการสนใจอย่างมากจากชุมชนนักพัฒนา เพราะแนวคิดการใช้อุปมา "[REM Sleep]" สำหรับการจัดระเบียบหน่วยความจำของ [AI] นั้นตรงไปตรงมาและเข้าใจง่าย ในระหว่าง [REM Sleep] สมองมนุษย์จะประมวลผลความทรงจำจากวันนั้น ลบข้อมูลที่ไม่สำคัญ และสร้างการเชื่อมโยงใหม่ระหว่างข้อมูลที่เก็บไว้ /dream ใช้หลักการเดียวกันกับ [memory files] ของ [agent]
ระบบทำงานใน 4 เฟสหลัก คือ Orient (ประเมินสถานะหน่วยความจำปัจจุบันและระบุสิ่งที่ต้องการการจัดการ), Gather signal (รวบรวมข้อมูลจาก [session] ล่าสุดและ [feedback] ที่ได้รับ), Consolidate (รวมและสรุปข้อมูลที่เกี่ยวข้อง ลบความซ้ำซ้อน) และ Prune & index (ลบข้อมูลที่ล้าสมัยและจัดทำดัชนีใหม่เพื่อให้ค้นหาได้รวดเร็ว) ระบบเริ่มทำงานอัตโนมัติเมื่อผ่าน 24+ ชั่วโมงและ 5+ [sessions] นับตั้งแต่ครั้งล่าสุด ในระหว่างทำงาน /dream จะเป็น [read-only] กับ [codebase] ทั้งหมด แก้ไขเฉพาะ [memory files] เพื่อป้องกันผลข้างเคียงที่ไม่ตั้งใจ ผู้ใช้สามารถเรียกใช้ด้วยตัวเองได้ผ่านคำสั่ง /memory
Claude Computer Use — ควบคุมเมาส์คีย์บอร์ดบน Mac
ฟีเจอร์ [Computer Use] บน [Mac] ที่ปล่อยใน [research preview] สำหรับผู้ใช้ [Pro] และ [Max] เปิดให้ Claude สามารถควบคุมเมาส์และคีย์บอร์ดบนเครื่อง [Mac] ได้โดยตรง วิธีการทำงานพื้นฐานคือการถ่ายภาพหน้าจอเพื่อเข้าใจ [context] ปัจจุบัน แล้วจึงตัดสินใจว่าจะคลิก พิมพ์ หรือเลื่อนอะไร ซึ่งคล้ายกับวิธีที่มนุษย์มองหน้าจอก่อนใช้งาน แต่ทำงานด้วยความถี่สูงกว่ามาก
ในด้านความน่าเชื่อถือ ระบบทำได้ดีในงานง่าย ๆ ที่มีขั้นตอนชัดเจนราว 80% เช่น การเปิดแอปพลิเคชัน การกรอกฟอร์ม หรือการนำทางในเว็บไซต์ แต่ลดลงเหลือประมาณ 50% สำหรับงานที่ซับซ้อนหรือต้องการการตัดสินใจในบริบทที่หลากหลาย ข้อจำกัดที่ยังพบอยู่คือปัญหากับ [captcha] และ [2FA] ซึ่งออกแบบมาเพื่อป้องกัน [bot] โดยเฉพาะ ฟีเจอร์นี้ใช้ร่วมกับ [Dispatch] ได้สำหรับสั่งงานโทรศัพท์ระยะไกล เปิดความเป็นไปได้ใหม่สำหรับงาน [automation] ที่เดิมต้องการมนุษย์
Kimi "Attention Residuals" — นวัตกรรมสถาปัตยกรรมที่ดึงดูด Musk และ Karpathy
[Kimi] ซึ่งเป็น [AI assistant] จาก [Moonshot AI] บริษัทสตาร์ทอัพจากจีนที่เติบโตรวดเร็วในช่วงที่ผ่านมา นำเสนองานวิจัยเรื่อง "Attention Residuals" ซึ่งเป็นนวัตกรรมสถาปัตยกรรมที่ได้รับความสนใจอย่างกว้างขวางจากชุมชน [AI] ทั่วโลก แนวคิดหลักคือการให้แต่ละ [layer] ใน [transformer] สามารถอ้างอิงข้อมูลจาก [layer] ก่อนหน้าด้วย [learned input-dependent weights] แทนที่จะส่งต่อข้อมูลแบบตรงไปตรงมาเหมือนสถาปัตยกรรมทั่วไป ทำให้แต่ละ [layer] มีความ "ยืดหยุ่น" ในการตัดสินใจว่าจะรับข้อมูลจาก [layer] ไหนมากน้อยแค่ไหน
ผลการทดสอบชี้ว่าเทคนิคนี้ให้ประสิทธิภาพเทียบเท่าการใช้ [compute] เพิ่มขึ้น 1.25 เท่า แต่มี [overhead] จริงไม่ถึง 2% ซึ่งหมายความว่าได้ผลลัพธ์เหมือนโมเดลที่ใหญ่ขึ้นโดยแทบไม่ต้องจ่ายต้นทุนเพิ่ม งานนี้ดึงดูดความสนใจจาก [Elon Musk] และ [Andrej Karpathy] ซึ่งทั้งคู่แสดงความสนใจต่อสาธารณะ บ่งชี้ว่างานวิจัยนี้ได้รับการยอมรับจากผู้เชี่ยวชาญระดับสูงในอุตสาหกรรม [Cursor] ประกาศว่าได้นำโมเดล [Kimi] มาใช้งานแล้ว อย่างไรก็ตาม [MiniMax] ซึ่งเป็นบริษัทจีนอีกแห่งถูกจับได้ว่าคัดลอกโค้ดของ [Kimi] ก่อกรณีพิพาทเรื่องทรัพย์สินทางปัญญาในชุมชน [AI] จีน
ทางเลือกหลัง LiteLLM ถูกโจมตี Supply Chain
เหตุการณ์ [supply chain attack] ที่กระทบ [LiteLLM] ไลบรารียอดนิยมสำหรับ [LLM routing] สร้างแรงกระเพื่อมในชุมชนนักพัฒนาอย่างมาก เพราะ [LiteLLM] เป็น [dependency] หลักของโปรเจกต์ [AI] จำนวนมากทั่วโลก การโจมตีแบบ [supply chain] เกิดขึ้นเมื่อ [package] ที่ใช้กันอย่างแพร่หลายถูกฝังโค้ดอันตรายไว้ และผู้ใช้ที่ติดตั้งหรืออัปเดตโดยไม่ระวังก็จะได้รับโค้ดนั้นมาด้วยโดยไม่รู้ตัว
ชุมชนเริ่มหันหาทางเลือก ได้แก่ [Bifrost] ที่อ้างว่าเร็วกว่า [LiteLLM] ถึง 50 เท่าในแง่ [P99 latency] เหมาะกับงานที่ต้องการความเร็วสูง, [Kosong] ที่มีน้ำหนักเบาและ [dependency tree] น้อยมาก ลดพื้นที่เสี่ยงต่อการโจมตี และ [Helicone] ที่มีระบบ [analytics] ครบถ้วนพร้อมการตรวจสอบ [prompt] และ [response] บทเรียนสำคัญที่ชุมชนนักพัฒนา [AI] สรุปได้จากเหตุการณ์นี้คือการลด [dependency tree] ให้เล็กที่สุด และการ [pin version] ทุก [package] อย่างเข้มงวดเพื่อป้องกันการถูกโจมตีในลักษณะเดิม ความปลอดภัยของห่วงโซ่อุปทานซอฟต์แวร์เป็นเรื่องที่ไม่ควรมองข้าม
daVinci-MagiHuman — โมเดลสร้างวิดีโอ Open Source 15B
ทีม [GAIR] เปิดตัว [daVinci-MagiHuman] โมเดลสร้างวิดีโอแบบโอเพนซอร์สขนาด 15 พันล้านพารามิเตอร์ที่เน้นการสร้างวิดีโอของมนุษย์โดยเฉพาะ ครอบคลุมทั้งการเดิน การพูด และการแสดงออกทางสีหน้า ซึ่งเป็นหนึ่งในโจทย์ที่ยากที่สุดในการสร้างวิดีโอด้วย [AI] เพราะมนุษย์มีความไวสูงในการจับข้อผิดพลาดของการเคลื่อนไหวมนุษย์
ทีมอ้างว่าสามารถสร้างวิดีโอได้เร็วกว่า [LTX] 2.3 แบบเต็ม (65GB) ซึ่งหากเป็นจริงจะเป็นความก้าวหน้าที่น่าสนใจมากในแง่การเข้าถึงด้วยฮาร์ดแวร์ทั่วไป อย่างไรก็ตามมีข้อถกเถียงในชุมชนเรื่องความน่าเชื่อถือของ [benchmark] ที่ใช้ โดยนักวิจารณ์ชี้ว่าตัวเลขมาจาก [still frames] ไม่ใช่คุณภาพ [motion] จริง นอกจากนี้คุณภาพ [physical consistency] ซึ่งหมายถึงการที่วัตถุเคลื่อนไหวตามกฎฟิสิกส์จริง ยังต่ำกว่า [LTX] 2.3 อย่างเห็นได้ชัด ชุมชนรอการทดสอบอิสระเพื่อยืนยันข้อเรียกร้อง
ข่าวลือ DeepSeek โมเดลใหม่ — ถูกหักล้างเป็นของปลอม
ข่าวลือที่แพร่กระจายในช่วงต้นสัปดาห์ว่าพนักงาน [DeepSeek] ได้รั่วไหลข้อมูลว่าบริษัทกำลังพัฒนาโมเดลใหม่ที่เหนือกว่า [DeepSeek V3.2] อย่างมีนัยสำคัญ สร้างความฮือฮาในชุมชน [AI] เป็นอย่างมากก่อนที่จะถูกยืนยันว่าเป็นข่าวปลอมทั้งหมด ไม่มีแหล่งที่มาที่น่าเชื่อถือ ไม่มีเอกสารจริง และไม่มีการยืนยันจาก [DeepSeek] อย่างเป็นทางการแต่อย่างใด
แม้ข่าวจะเป็นเท็จ แต่ปฏิกิริยาที่เกิดขึ้นก่อนการหักล้างสะท้อนสิ่งที่สำคัญ — ชุมชน [AI] ทั่วโลกจับตา [DeepSeek] อย่างใกล้ชิดมาก ทุกการเคลื่อนไหวของบริษัทนี้กลายเป็นข่าวใหญ่ในทันที นี่เป็นผลมาจากการที่ [DeepSeek V3] และ [R1] สร้างความประหลาดใจให้วงการในช่วงต้นปีด้วยประสิทธิภาพระดับสูงในราคาที่ต่ำกว่าคู่แข่งตะวันตกอย่างมาก และชุมชนกังวลว่าจะเกิดการ "ช็อก" แบบนั้นอีกครั้ง
Hugging Face Buckets — ท้าชน S3 ด้วย Deduplication อัจฉริยะ
[Hugging Face] เปิดตัว [HF Buckets] บริการจัดเก็บข้อมูลที่ออกแบบมาเพื่อกลุ่มเป้าหมาย [AI] และ [ML] โดยเฉพาะ เมื่อเปรียบเทียบราคาต่อ [TB] แล้ว [HF Buckets] สามารถแข่งขันกับ [Amazon S3] ได้อย่างสมน้ำสมเนื้อ แต่จุดเด่นที่แท้จริงไม่ได้อยู่ที่ราคาอย่างเดียว
สิ่งที่ทำให้ [HF Buckets] แตกต่างจากบริการจัดเก็บทั่วไปคือ [Xet-style chunk-level deduplication] ซึ่งเป็นระบบที่ตรวจจับข้อมูลซ้ำกันในระดับ [chunk] ไม่ใช่ระดับไฟล์ทั้งหมด ทำให้ประหยัดพื้นที่ได้มากเมื่อเก็บ [dataset] และ [checkpoint] ที่มักมีส่วนซ้ำกันจำนวนมาก ตัวอย่างเช่น [checkpoint] ของโมเดลเดียวกันในขั้นตอนการฝึกที่ต่างกัน หรือ [dataset] ที่มีข้อมูลทับซ้อนกัน สโลแกน "Your disk is no longer the limit" สะท้อนวิสัยทัศน์ที่ [Hugging Face] ต้องการเป็น [AI infrastructure] ครบวงจร ไม่ใช่แค่แพลตฟอร์มแชร์โมเดล
Karpathy เตือน — Memory ระยะยาวของ AI มักสร้างปัญหามากกว่าช่วย
[Andrej Karpathy] อดีตผู้อำนวยการ [AI] ของ [Tesla] และอดีตนักวิจัยหลักจาก [OpenAI] ซึ่งปัจจุบันมีสถานะเป็นนักคิดที่มีอิทธิพลสูงในวงการ [AI] แสดงความเห็นที่น่าคิดเรื่อง [long-lived memory] ใน [AI] ว่าในทางปฏิบัติมักสร้างปัญหามากกว่าประโยชน์ที่คาดหวัง
ข้อกังวลหลักของ [Karpathy] คือ [memory] ระยะยาวมักจะ [overfit] กับข้อมูลผู้ใช้ที่ล้าสมัยหรือบริบทที่เปลี่ยนแปลงไปแล้ว ตัวอย่างที่เข้าใจง่ายคือถ้า [AI] จำว่าผู้ใช้ชอบภาษา [Python] แต่ผู้ใช้ได้ย้ายไปใช้ [Rust] เป็นหลักแล้ว [AI] ที่ยึดติดกับ [memory] เก่าจะยังคงแนะนำ [Python] ซ้ำ ๆ สร้างความรำคาญมากกว่าประโยชน์ ความเห็นนี้สอดคล้องกับฟีเจอร์ /dream ของ [Claude Code] ที่พยายามแก้ปัญหาเรื่องนี้ด้วยการ [prune memory] เป็นระยะ แต่ประเด็นที่ [Karpathy] ตั้งคือแม้แต่การ [prune] ก็อาจไม่เพียงพอ เพราะปัญหาเชิงโครงสร้างของการเก็บ [memory] ระยะยาวยังต้องการวิธีแก้ที่ดีกว่าเดิม
World Models และ Self-Improving Agents — งานวิจัยสำคัญ 3 ชิ้น
สัปดาห์นี้มีงานวิจัยสำคัญ 3 ชิ้นที่ชี้ทิศทางเดียวกันอย่างน่าสนใจ ทั้งหมดเกี่ยวข้องกับการที่ [AI] เคลื่อนสู่ความสามารถในการเข้าใจโลก วางแผนระยะยาว และปรับปรุงตัวเองได้ ซึ่งเป็นคุณสมบัติที่นักวิจัยมองว่าจำเป็นสำหรับ [AI] ที่มีประโยชน์จริงในโลกที่ซับซ้อน
[LeWorldModel] เป็น [JEPA world model] ขนาดเพียง 15M พารามิเตอร์ที่ฝึกได้บน [GPU] เดียว ใช้ [latent planning] ที่เร็วกว่าแนวทางเดิมอย่างมีนัยสำคัญ ความสำคัญของงานนี้อยู่ที่การแสดงให้เห็นว่า [world model] ที่ใช้งานได้จริงไม่จำเป็นต้องมีขนาดมหึมา ทำให้การวิจัยเรื่อง [AI planning] เข้าถึงได้สำหรับทีมขนาดเล็กและนักวิจัยรายบุคคล
[Hyperagents] นำเสนอกระบวนการ [self-improvement] แบบแก้ไขได้ที่วัดผลได้ชัดเจน ความแม่นยำในการ [review paper] เพิ่มจาก 0.0 เป็น 0.710 ผ่านการปรับปรุงตัวเองซ้ำ ๆ โดยไม่ต้องรับข้อมูลจากมนุษย์เพิ่มเติม กระบวนการนี้แตกต่างจาก [self-improvement] แบบเดิมที่มักเป็น [black box] ไม่สามารถตรวจสอบหรือแก้ไขได้ง่าย
[MemCollab] เป็นแนวทางใหม่สำหรับการแบ่งปัน [memory] ข้าม [agents] หลายตัว โดยแยกความรู้สากล ([world knowledge]) ออกจาก [bias] เฉพาะโมเดล ทำให้ [agents] หลายตัวสามารถเรียนรู้จากกันและกันโดยไม่รับเอา [bias] มาด้วย ทั้งสามงานชี้ให้เห็นทิศทางเดียวกัน — [AI] กำลังเคลื่อนสู่ระบบที่เข้าใจบริบท วางแผน และปรับตัวได้เอง ซึ่งเป็นรากฐานสำหรับ [AI] ที่มีประโยชน์จริงในงานที่ซับซ้อน
ภาพรวมสัปดาห์ — การแข่งขันเข้มข้นขึ้นในทุกมิติ
สัปดาห์นี้แสดงให้เห็นการแข่งขันที่เข้มข้นในทุกระดับของอุตสาหกรรม [AI] พร้อมกัน ในระดับสถาปัตยกรรมโมเดล งานวิจัยอย่าง [Kimi Attention Residuals] และ [LongCat-Next] แสดงให้เห็นว่าบริษัทจากเอเชียกำลังสร้างนวัตกรรมทางเทคนิคในระดับที่เทียบได้กับห้องวิจัยชั้นนำของตะวันตก ขณะที่ [GigaChat] จากรัสเซียแสดงว่าประเทศนอกวงจร [Silicon Valley] ก็กำลังลงทุนอย่างจริงจังใน [AI] ระดับโลก
ในระดับผลิตภัณฑ์ [Claude launch week] ของ [Anthropic] และ [Google Lyria 3 Pro] สะท้อนการแข่งขันที่เคลื่อนจากการพัฒนาโมเดลเพื่อวัด [benchmark] มาสู่การสร้างผลิตภัณฑ์ที่ผู้ใช้ต้องการใช้จริงในชีวิตประจำวัน ในระดับโครงสร้างพื้นฐาน เครื่องมืออย่าง [Agent tools], [HF Buckets] และความก้าวหน้าด้าน [inference optimization] กำลังทำให้ต้นทุนการใช้ [AI] ลดลงและเข้าถึงได้กว้างขึ้นทั้งสำหรับองค์กรและผู้ใช้ทั่วไป
การปิด [Sora] เป็นสัญญาณเตือนที่ชัดเจนว่าแม้แต่บริษัทที่มีทรัพยากรมากที่สุดในโลกก็ต้องเลือกสนามรบที่ตัวเองมีความได้เปรียบทางเศรษฐกิจ ขณะที่ [ARC-AGI-3] เตือนว่ายังมีช่องว่างขนาดใหญ่ระหว่าง [AI] กับมนุษย์ในด้านการคิดเชิงนามธรรมและการปรับตัวในสถานการณ์ใหม่ที่ไม่คุ้นเคย ความก้าวหน้าด้าน [inference efficiency] โดยเฉพาะการที่โมเดลขนาด 24B รันในเบราว์เซอร์ได้ที่ความเร็วที่ใช้งานได้จริง กำลังทำให้ [AI] ทรงพลังเข้าถึงได้ง่ายขึ้นเรื่อย ๆ แม้แต่บนอุปกรณ์ส่วนตัวทั่วไป
ภาพรวมที่เห็นชัดที่สุดในสัปดาห์นี้คือความเร็วที่อุตสาหกรรม [AI] กำลังพัฒนา ทั้งในแง่เทคนิคและธุรกิจ บริษัทที่ปรับตัวช้าหรือเลือกสนามรบผิดอาจพบว่าตัวเองอยู่ในสถานการณ์คล้าย [Sora] ที่มีเทคโนโลยีน่าประทับใจแต่ขาดความยั่งยืนทางธุรกิจ ในขณะเดียวกัน [ARC-AGI-3] เตือนให้ระลึกว่าความก้าวหน้าในระยะสั้นที่วัดด้วย [benchmark] ทั่วไปยังไม่ได้สะท้อนถึงความสามารถในการคิดและปรับตัวที่แท้จริงของมนุษย์
ข้อมูล ณ วันที่ 26 มีนาคม 2569 — บทความนี้จัดทำขึ้นเพื่อให้ข้อมูลเท่านั้น ไม่ได้เป็นคำแนะนำด้านการลงทุนแต่อย่างใด