
สรุปข่าว AI ประจำวันที่ 19 มีนาคม 2569: MiniMax M2.7 แรงเท่า GLM-5 ในต้นทุนถูกกว่า 3 เท่า, Mamba-3 เปิดตัว, Unsloth Studio และอีกมากมาย
MiniMax M2.7 โมเดลที่ "วิวัฒนาการตัวเอง" ขึ้นแท่น SOTA เทียบชั้น GLM-5 ในราคาถูกกว่าสามเท่า
ยังไม่ทันผ่านสองเดือนหลัง IPO บริษัท MiniMax จากจีนก็กลับมาสร้างแรงกระเพื่อมในวงการ AI อีกครั้งด้วยการเปิดตัว MiniMax M2.7 โมเดลภาษาขนาดใหญ่รุ่นใหม่ล่าสุดที่ทำคะแนนเทียบเท่า GLM-5 ของ Z.ai ซึ่งเป็นโมเดลโอเพนซอร์สที่ดีที่สุดในขณะนี้ แต่จุดเด่นที่แท้จริงอยู่ที่ประสิทธิภาพด้านต้นทุน โดย Artificial Analysis ระบุว่า M2.7 ได้คะแนน Intelligence Index 50 เท่ากับ GLM-5 (Reasoning) แต่ค่าใช้จ่ายในการรัน benchmark เต็มรูปแบบอยู่ที่เพียง 176 ดอลลาร์ ด้วยราคา 0.30/1.20 ดอลลาร์ต่อล้านโทเค็น สำหรับ input/output ซึ่งถูกกว่า GLM-5 มากกว่าสามเท่า
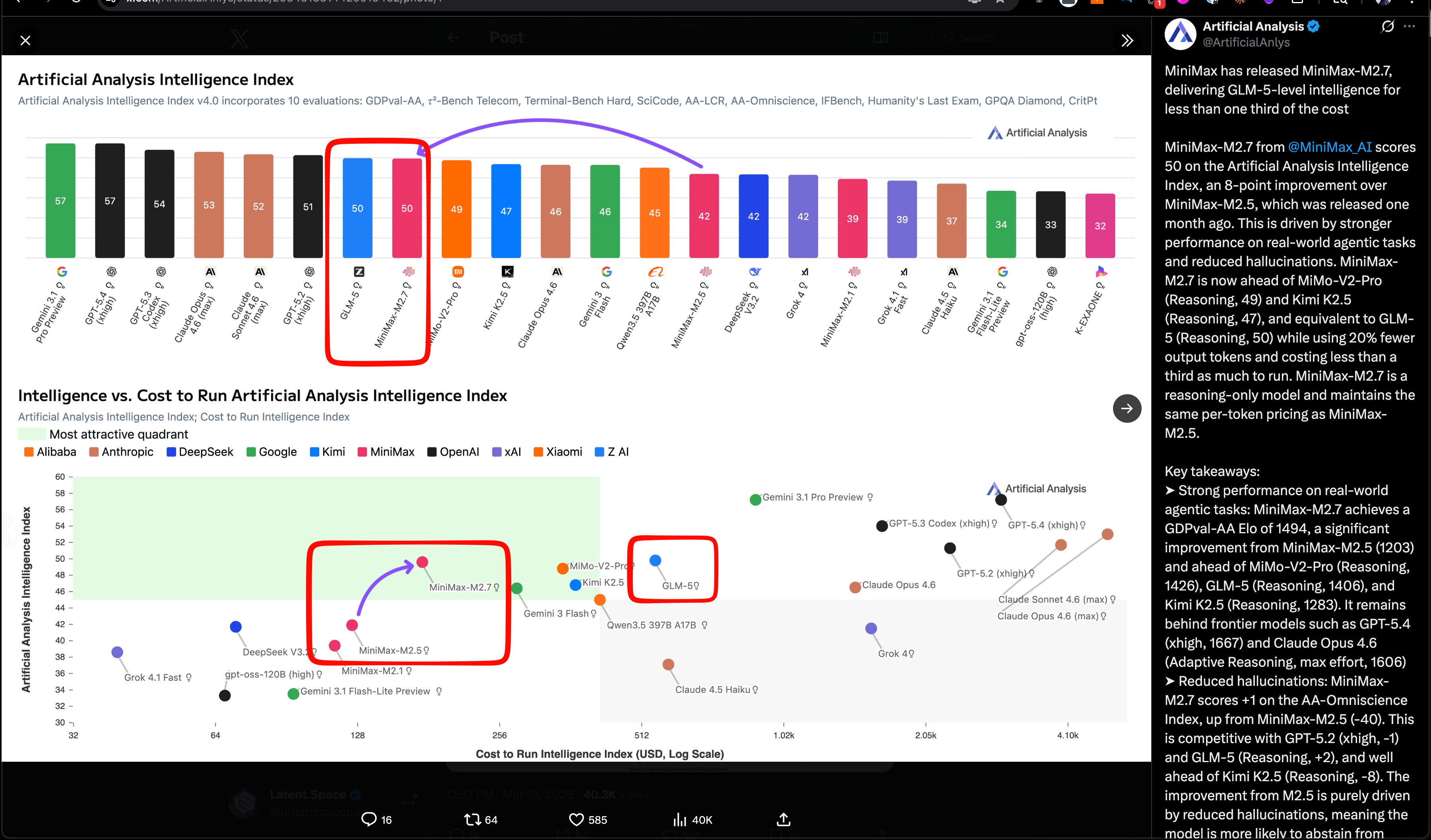
สิ่งที่น่าสนใจยิ่งกว่าคือ ทีมพัฒนาเรียก M2.7 ว่าเป็นโมเดลแรกที่ "มีส่วนร่วมอย่างลึกซึ้งในวิวัฒนาการของตัวเอง" [Self-Evolution] โดยอ้างว่าโมเดลสามารถจัดการ workflow ได้ 30-50% ด้วยตัวเอง ตั้งแต่การวิเคราะห์จุดที่ล้มเหลว วางแผนปรับปรุง แก้ไขโค้ด และประเมินผลลัพธ์ ส่งผลให้ประสิทธิภาพดีขึ้นถึง 30% ในการทดสอบภายใน
ด้านคะแนน benchmark M2.7 ทำได้ 56.22% บน SWE-Pro, 57.0% บน Terminal Bench 2 และ 97% ในด้าน skill adherence จาก 40 ทักษะขึ้นไป
ในแง่ของคุณภาพเอาต์พุต M2.7 ยังได้คะแนน GDPval-AA Elo 1494 นำหน้า MiMo-V2-Pro (1426), GLM-5 (1406) และ Kimi K2.5 (1283) พร้อมลดปัญหา hallucination ลงอย่างมากเมื่อเทียบกับ M2.5 รุ่นก่อนหน้า โมเดลนี้พร้อมใช้งานแล้วบนหลายแพลตฟอร์ม ได้แก่ Ollama, Trae, OpenRouter, Vercel และอื่น ๆ
Xiaomi MiMo-V2-Pro เข้าสู่สนาม Reasoning Model แบบ API-Only
Xiaomi ไม่ได้มีแค่สมาร์ทโฟนและรถยนต์ไฟฟ้า แต่ตอนนี้กำลังรุกตลาด AI อย่างจริงจังด้วย MiMo-V2-Pro โมเดลแบบ API-only ที่ได้คะแนน Intelligence Index 49 จาก Artificial Analysis รองรับ context ยาวถึง 1 ล้านโทเค็น ในราคา 1/3 ดอลลาร์ต่อล้านโทเค็น สำหรับ input และ output ตามลำดับ
จุดเด่นของ MiMo-V2-Pro อยู่ที่ ประสิทธิภาพการใช้โทเค็น [Token Efficiency] ที่ดีกว่าคู่แข่ง และได้คะแนน AA-Omniscience สูงกว่าค่าเฉลี่ย (+5) เนื่องจากมีอัตรา hallucination ต่ำ โมเดลนี้ต่อยอดจาก MiMo-V2-Flash รุ่นก่อนหน้าที่เป็นโอเพนซอร์ส (พารามิเตอร์รวม 309 พันล้าน / ใช้งานจริง 15 พันล้าน ภายใต้ลิขสิทธิ์ MIT) แต่ V2-Pro ในตอนนี้เปิดให้ใช้งานผ่าน API เท่านั้น
Mamba-3 เปิดตัว: สถาปัตยกรรม SSM สำหรับยุค Inference-Heavy
Cartesia เปิดตัว Mamba-3 สถาปัตยกรรม State Space Model [SSM] รุ่นใหม่ที่ออกแบบมาเพื่อโลกที่เน้น inference เป็นหลัก โดย Albert Gu ผู้คิดค้นสถาปัตยกรรม Mamba ดั้งเดิมร่วมสนับสนุนในการพัฒนาและทดสอบ
ปฏิกิริยาจากชุมชนนักวิจัยมุ่งเน้นไปที่การนำ Mamba-3 ไปใช้ใน สถาปัตยกรรมแบบไฮบริด [Hybrid Architecture] มากกว่าการใช้งาน SSM แบบเดี่ยว นักวิจัยหลายคนเสนอว่า Mamba-3 อาจเข้ามาแทนที่ Gated DeltaNet ในโมเดลไฮบริดรุ่นถัดไปอย่าง Qwen3.5 และ Kimi Linear รวมถึงมีการพูดถึงการ "ปลดล็อก Muon สำหรับ SSM" ซึ่งอาจเปิดทางให้เทคนิคการเทรนแบบใหม่ ๆ สำหรับสถาปัตยกรรมประเภทนี้
Harness Engineering: จุดเปลี่ยนจาก "Prompting" สู่การออกแบบระบบ AI
หนึ่งในธีมที่โดดเด่นที่สุดในสัปดาห์นี้คือแนวคิดที่ว่า คอขวดของ AI agent ไม่ใช่โมเดลพื้นฐานอีกต่อไป แต่เป็นสภาพแวดล้อมการทำงานรอบข้าง หรือที่เรียกว่า Harness Engineering บทสัมภาษณ์ของ Michael Bolin อธิบายว่า coding agent เป็นปัญหาของเครื่องมือ ความอ่านง่ายของ repo ข้อจำกัด และ feedback loop มากกว่าจะเป็นเรื่องของโมเดลล้วน ๆ
มุมมองนี้สอดคล้องกับข้อโต้แย้งที่ว่า GPT-5.4 mini มีความสำคัญเพราะ subagent ที่ถูกและเร็วเปลี่ยนแปลงสิ่งที่คุ้มค่าจะมอบหมายงานให้ AI ทำ และ Harrison Chase จาก LangChain ก็เผยแพร่บทวิเคราะห์ที่มองว่า Claude Code, OpenClaw, Manus และอื่น ๆ ล้วนเป็นการแยกส่วนแบบเดียวกัน: โมเดล + runtime + harness
Skills กลายเป็นมาตรฐานร่วมของ Agent Stack ต่าง ๆ
แนวคิดเรื่อง Skills กำลังกลายเป็น abstraction ที่ใช้ร่วมกันข้ามระบบ agent ต่าง ๆ โดยมีการอธิบายรูปแบบการใช้งานจริง ได้แก่ progressive disclosure, trace inspection, session distillation, CI-triggered skills และ self-improving skills
มีข้อเสนอว่าการกระจาย skills ผ่าน MCP resources อาจแก้ปัญหาเรื่องความล้าสมัยและการจัดการเวอร์ชัน ขณะที่ Anthropic ชี้แจงว่า skill ไม่ใช่แค่ข้อความธรรมดา แต่เป็นโฟลเดอร์ที่รวมสคริปต์ สินทรัพย์ และข้อมูลเข้าด้วยกัน โดยฟิลด์ description มีหน้าที่ระบุว่าเมื่อใดควร trigger skill นั้น ๆ
MCP ยังเดินหน้า แต่เสียงวิพากษ์เริ่มดังขึ้น
ฝั่งที่สนับสนุน Model Context Protocol [MCP] มีการเปิดตัวที่น่าสนใจ เช่น Google Colab ปล่อย MCP server แบบโอเพนซอร์สที่ช่วยให้ agent ในเครื่องสามารถควบคุม Colab GPU runtime ได้ และ Gemini API อัปเดตให้รองรับ built-in tools ร่วมกับ custom functions ในการเรียกครั้งเดียว
แต่ฝั่งตรงข้ามก็มีเสียงคัดค้านที่ชัดเจน โดยนักพัฒนาบางรายออกมาพูดตรง ๆ ว่า "MCP เป็นความผิดพลาด จงใช้ CLI" สะท้อนมุมมองที่ว่า CLI แบบดั้งเดิมอาจเรียบง่ายและมีประสิทธิภาพกว่าสำหรับหลายกรณีการใช้งาน การถกเถียงนี้ชี้ให้เห็นว่าระบบนิเวศยังไม่ลงตัวว่ามาตรฐานใดจะเป็นผู้ชนะ
Headless SaaS: ซอฟต์แวร์ยุคใหม่ที่สร้างมาเพื่อ AI Agent
แนวคิดใหม่ที่กำลังก่อตัวคือ Headless SaaS ซอฟต์แวร์แบบเดิมที่ถูกสร้างใหม่ให้เป็น API สำหรับ agent โดยเฉพาะ ไม่มี UI สำหรับมนุษย์ แนวคิดนี้สอดคล้องกับผลิตภัณฑ์ที่เปิดตัวอย่าง Rippling AI analyst และ Anthropic ที่จัดเวิร์กช็อปเรื่อง Claude สำหรับ Excel/PowerPoint
มุมมองนี้ชี้ว่าในอนาคต แอปจดบันทึกการประชุมจะไม่ใช่แค่แอปจดบันทึกอีกต่อไป แต่จะกลายเป็น แอป context และ data สำหรับ AI ที่กว้างกว่ามาก นี่อาจเป็นจุดเริ่มต้นของคลื่นลูกใหม่ในวงการ SaaS ที่ทุกอย่างถูกออกแบบมาให้ agent เป็นผู้ใช้หลัก
Attention Residual: กรณีศึกษาของการออกแบบร่วมระหว่างโมเดลและ Infra
งานวิจัย Attention Residual [AttnRes] จาก Kimi/Moonshot กลายเป็นกรณีศึกษาที่ได้รับความสนใจในฐานะตัวอย่างของ algorithm-system co-design ปัญหาหลักคือ full attention residual สร้างแรงกดดันต่อ pipeline parallelism เนื่องจากรูปแบบการสื่อสารและหน่วยความจำที่ไม่สมมาตร
วิธีแก้ไขคือ Block Attention Residual ร่วมกับ cross-stage caching ที่ช่วยคืนสมดุลให้ระบบ แนวทางนี้ตอกย้ำว่าการพัฒนาโมเดลขนาดใหญ่ในระดับ production ต้องอาศัยความเชี่ยวชาญทั้งด้าน kernel optimization, algorithm design และ numerical rigor ไปพร้อม ๆ กัน
Custom Kernel จัดแพ็กเกจง่ายขึ้นด้วย Hugging Face Kernels Library
Hugging Face เปิดตัว kernels library ใหม่ที่มุ่งทำให้การแชร์และรวม custom kernel เข้ากับโปรเจกต์ต่าง ๆ ง่ายขึ้นผ่าน Hub เป้าหมายคือลดความยุ่งยากในการเขียนและกระจาย fused/custom kernels โดยไม่ต้องให้ทุกทีมจัดการเรื่อง installation และ integration ด้วยตัวเอง
แนวทางการ optimize inference ที่ได้รับการพูดถึงมากยังคงเป็นหลักการเดิม: ปิดช่องว่างระหว่างการเรียก kernel, ใช้ torch.compile ในการ fuse operations และใช้ custom kernel เฉพาะกรณีที่จำเป็นจริง ๆ ฝั่งฮาร์ดแวร์มีข้อสังเกตว่า bandwidth ของ NVLink ที่โฆษณาอาจทำให้เข้าใจผิดได้ เพราะไม่ได้เป็น duplex ในแบบที่หลายคนคิด
คอขวดด้านการผลิตชิป: เครื่อง EUV ของ ASML อาจจำกัดการเติบโตของ AI
มีการวิเคราะห์ที่ชี้ว่า เครื่อง EUV [Extreme Ultraviolet Lithography] ของ ASML และห่วงโซ่อุปทานที่แคบมากอาจจำกัดกำลังการผลิตไว้ที่ราว 100 เครื่องต่อปี ภายในปี 2573 (2030) ทำให้เทคโนโลยี lithography กลายเป็น เพดานสำคัญของการ scaling AI ในทศวรรษนี้
นี่เป็นมุมมองที่น่าสนใจสำหรับนักลงทุน เพราะหมายความว่าไม่ว่าความต้องการ compute จะเพิ่มขึ้นมากเพียงใด กำลังการผลิตจริงอาจถูกจำกัดด้วยปัจจัยทางกายภาพที่แก้ไขได้ยาก ซึ่งอาจส่งผลต่อราคาชิปและการแข่งขันด้าน AI infrastructure ในระยะยาว
Document AI: ยุคของ Multimodal Parser แบบ End-to-End
Baidu เปิดตัว Qianfan-OCR โมเดลขนาด 4 พันล้านพารามิเตอร์ที่รวมความสามารถด้าน การดึงข้อมูลจากตาราง, การจดจำสูตรคณิตศาสตร์, การเข้าใจกราฟ และ Key Information Extraction เข้าไว้ในการประมวลผลรอบเดียว
ในฝั่งโอเพนซอร์ส Vik Paruchuri เปิดตัว Chandra OCR 2 ที่อ้างว่าได้คะแนน 85.9% บน olmOCR bench รองรับมากกว่า 90 ภาษา และมีความสามารถที่ดีขึ้นในด้าน layout, ลายมือ, คณิตศาสตร์, แบบฟอร์ม และตาราง ทั้งหมดนี้ในโมเดลขนาดเพียง 4 พันล้านพารามิเตอร์
ฝั่งแพลตฟอร์ม LlamaIndex เน้นย้ำว่า document agent ระดับ production ต้องการมากกว่าแค่การแปลงเป็น markdown แต่ต้องมี layout detection, segmentation, metadata context และ visual grounding เพื่อรองรับ workflow ที่มนุษย์สามารถตรวจสอบได้
MUVERA: ลดหน่วยความจำ Multi-Vector Retrieval ลง 70%
งานวิจัย MUVERA นำเสนอวิธีบีบอัด multi-vector retrieval ให้เป็น encoding แบบมิติคงที่ ซึ่งช่วยลดการใช้หน่วยความจำได้ราว 70% และทำให้กราฟ HNSW เล็กลงมาก แม้จะแลกมาด้วย recall และ throughput ที่ลดลงบ้าง
การวิจัยนี้ตอกย้ำข้อจำกัดของ single-vector retrieval ใน setting ที่ยากขึ้น โดยเฉพาะกรณี out-of-distribution ซึ่งเป็นปัญหาที่สำคัญสำหรับระบบ RAG ในการใช้งานจริง
Context Engineering: ผู้สืบทอดตำแหน่ง Prompt Engineering
LlamaIndex ประกาศชัดว่า Context Engineering คือตัวแทนยุคใหม่ของ prompt engineering โดยมี structured parsing/extraction เป็นเครื่องมือหลัก แนวคิดนี้สอดคล้องกับการที่ Hugging Face เปิดให้แสดงผลเอกสารวิจัยในรูปแบบ Markdown สำหรับ agent พร้อม Paper Pages skill ที่ช่วยค้นหาและอ่านเอกสารวิจัยได้อย่างมีประสิทธิภาพด้านโทเค็น
การเปลี่ยนแปลงนี้สะท้อนว่าการออกแบบ prompt เพียงอย่างเดียวไม่เพียงพออีกต่อไป สิ่งที่จำเป็นคือ การจัดการ context ทั้งระบบ ตั้งแต่การแยกวิเคราะห์เอกสาร การจัดโครงสร้างข้อมูล ไปจนถึงการเลือกว่าจะป้อนข้อมูลอะไรให้โมเดลในแต่ละขั้นตอน
ปัญหาความน่าเชื่อถือของ LLM-as-Judge: เปลี่ยนผู้ตัดสิน คะแนนเปลี่ยนทันที
มีการเปิดเผยตัวอย่างที่ชัดเจนว่าการใช้ LLM เป็นผู้ตัดสิน [LLM-as-Judge] มีปัญหาด้านความสอดคล้อง โดยโมเดลตัวหนึ่งได้คะแนนเพียง 10% เมื่อใช้ GPT-5.2 เป็นผู้ตัดสิน แต่ได้ 43.5% เมื่อเปลี่ยนเป็น GPT-5.1 ทั้งที่เอกสารวิจัยรายงานไว้ที่ 34%
บทเรียนสำคัญคือ อย่าใช้ LLM-as-Judge โดยไม่ตรวจสอบ correlation กับการตัดสินของมนุษย์ หรือปรับแต่งให้เหมาะสมก่อน เพราะการเลือกผู้ตัดสินอาจส่งผลต่อข้อสรุปมากกว่าคุณภาพจริงของโมเดล
สัดส่วนข้อมูล Pretraining กลับมาเป็นปัจจัยสำคัญ
งานวิจัยหลายชิ้นชี้ว่า การผสมข้อมูล SFT เข้าไปในขั้นตอน pretraining อาจให้ผลดีกว่าแนวทาง pretrain-then-finetune แบบดั้งเดิม โดยมีการค้นพบ scaling law สำหรับสัดส่วนการผสม ภายใต้งบโทเค็นที่กำหนด
นักวิจัยหลายคนยังโต้แย้งว่า domain adaptation ได้ประโยชน์มากกว่าจากการผสมข้อมูลตั้งแต่เนิ่น ๆ หรือแม้แต่การ ทำซ้ำชุดข้อมูลคุณภาพสูงขนาดเล็ก 10-50 รอบ ในระหว่าง pretraining มากกว่าการ finetune แบบตรง ๆ ซึ่งอาจเปลี่ยนวิธีคิดเรื่อง pipeline การเทรนโมเดลไปอย่างมาก
NVIDIA Nemotron 3 Ultra: Base Model ขนาด 500 พันล้านพารามิเตอร์
NVIDIA เปิดตัว Nemotron 3 Ultra Base โมเดลขนาดประมาณ 500 พันล้านพารามิเตอร์ ที่อ้างว่าเป็น base model โอเพนซอร์สที่ดีที่สุด พร้อมประสิทธิภาพสูงกว่า 5 เท่าบน NVIDIA GB200 NVL72 โดยเปรียบเทียบกับ GLM และ Kimi K2 ในหลาย benchmark ทั้ง MMLU Pro, HumanEval, GSM8K และ Multilingual Global MMLU
ทว่ามีเสียงวิพากษ์ว่าการเปรียบเทียบไม่ชัดเจนว่าใช้ GLM เวอร์ชันไหน และ Kimi K2 เป็นโมเดลที่ออกมาแปดเดือนแล้ว มีข้อสังเกตด้วยว่ากราฟเริ่มต้นที่ 60% ซึ่งทำให้ช่องว่างด้านประสิทธิภาพดูเกินจริง
GPT-5.4 Mini และ Nano เปิดตัว: ถูกลงแต่แพงกว่ารุ่นก่อน
OpenAI เปิดตัว GPT-5.4 mini และ nano ที่มีประสิทธิภาพสูงในหลาย task โดย GPT-5.4 ทำคะแนนนำหน้าในด้าน software engineering และ expert scientific reasoning แต่ราคากลับสูงขึ้นจากรุ่นก่อน โดย GPT-5.4 nano อยู่ที่ 0.20/1.25 ดอลลาร์ เทียบกับ GPT-5 nano รุ่นเก่าที่ 0.05/0.40 ดอลลาร์
ในแง่ของคู่แข่ง Gemini 3.1 Flash-Lite ได้รับคำชมเรื่องความคุ้มค่า โดยมีความแม่นยำ 75% ในราคาที่ถูกกว่า Gemini 3.1 Pro ถึง 96.1% จากการทดสอบ 1 หมื่นครั้ง และเร็วกว่า 3.8 เท่า ทำให้เป็นตัวเลือกที่น่าสนใจสำหรับการใช้งานที่คำนึงถึงงบประมาณ
Unsloth Studio: Web UI โอเพนซอร์สสำหรับเทรนและรัน LLM ในเครื่อง
Unsloth Studio เปิดตัวในฐานะ Web UI โอเพนซอร์ส สำหรับเทรนและรัน LLM บนเครื่องของตัวเองทั้ง Mac, Windows และ Linux อ้างว่าสามารถเทรนโมเดลมากกว่า 500 รุ่น ได้เร็วกว่าสองเท่า ใช้ VRAM น้อยลง 70% รองรับ GGUF, vision, audio และ embedding models
ฟีเจอร์เด่น ได้แก่ การเปรียบเทียบโมเดลแบบเคียงข้างกัน, self-healing tool calling, web search, สร้าง dataset อัตโนมัติจากไฟล์ PDF, CSV และ DOCX รวมถึง code execution สำหรับทดสอบความถูกต้อง และส่งออกโมเดลเป็น GGUF และ Safetensors ติดตั้งง่ายด้วย pip install unsloth
ชุมชนตอบรับอย่างดี โดยมองว่าเป็นทางเลือกโอเพนซอร์สที่แท้จริงของ LM Studio และช่วยลดอุปสรรคทางเทคนิคสำหรับการ fine-tune โมเดลอย่างมาก
Krasis LLM Runtime: รันโมเดลขนาดใหญ่บน GPU ตัวเดียว
Krasis LLM Runtime นำเสนอวิธีรันโมเดลขนาดใหญ่อย่าง Qwen3-235B บน GPU ตัวเดียวอย่าง RTX 5080 โดยใช้เทคนิค streaming expert weights ผ่าน GPU ร่วมกับการจัดการ VRAM และ system RAM อย่างมีประสิทธิภาพ
แม้จะมีเสียงสงสัยเรื่องความเป็นไปได้ แต่ผู้ใช้หลายคนแสดงความสนใจที่จะทดสอบกับฮาร์ดแวร์ของตัวเอง นี่เป็นอีกหนึ่งตัวอย่างของเทรนด์ที่มุ่งทำให้โมเดลขนาดใหญ่เข้าถึงได้บนฮาร์ดแวร์ระดับผู้บริโภค
Topaz NeuroStream: อ้างลด VRAM ได้ 95% สำหรับโมเดลประมวลผลภาพ
Topaz Labs ร่วมมือกับ NVIDIA เปิดตัว Topaz NeuroStream เทคโนโลยีที่อ้างว่าลดการใช้ VRAM ลงได้ถึง 95% สำหรับโมเดล AI ขนาดใหญ่ในงานประมวลผลภาพและวิดีโอ จากที่ต้องใช้ 56GB VRAM เหลือเพียง 2.8GB ทำให้สามารถรันบน GPU ระดับผู้บริโภคได้
แม้จะน่าตื่นเต้น แต่ชุมชนยังแสดงความกังขาเนื่องจากยังไม่มีรายละเอียดทางเทคนิคที่ชัดเจน บางคนคาดว่าอาจเป็นการโหลดและปลดเลเยอร์ของโมเดลเข้า-ออกแบบลำดับ ซึ่งต้องรอดูผลการทดสอบจริง
OpenAI Parameter Golf: ความท้าทายเทรนโมเดลในขนาด 16MB
OpenAI เปิดตัว Parameter Golf ความท้าทายด้านการเทรนโมเดลที่ต้อง fit โมเดลภาษาที่ดีที่สุดใน artifact ขนาด 16MB โดยเทรนภายใน 10 นาทีบน 8×H100 พร้อมทุ่มงบ compute มูลค่า 1 ล้านดอลลาร์ สำหรับการแข่งขัน นี่เป็นการต่อยอดจากวัฒนธรรม NanoGPT speedrun ที่เน้นประสิทธิภาพสูงสุดในข้อจำกัดที่กำหนด
Anthropic สัมภาษณ์คน 8 หมื่นคนด้วย AI ในหนึ่งสัปดาห์
Anthropic ใช้ Claude สัมภาษณ์ผู้คน 80,508 คน ภายในหนึ่งสัปดาห์เกี่ยวกับความหวังและความกังวลต่อ AI ซึ่งบริษัทเรียกว่าเป็น การศึกษาเชิงคุณภาพขนาดใหญ่ที่สุดในประเภทนี้ งานวิจัยนี้น่าสนใจทั้งในแง่การวัดผลทางสังคมและในฐานะสัญญาณว่าการสัมภาษณ์ผ่านโมเดล AI อาจกลายเป็นเครื่องมือวิจัยมาตรฐานในอนาคต
Runway แสดงตัวอย่าง Real-Time Video Generation บนฮาร์ดแวร์ NVIDIA Vera Rubin
Runway ร่วมกับ NVIDIA แสดงตัวอย่างงานวิจัยด้านการสร้างวิดีโอ HD แบบ real-time ด้วย time-to-first-frame ต่ำกว่า 100 มิลลิวินาที บนฮาร์ดแวร์ Vera Rubin หากเทคโนโลยีนี้สามารถขยายผลได้จริง จะเป็นการเปลี่ยนแปลงเชิงคุณภาพในวิธีที่ผู้ใช้โต้ตอบกับโมเดลสร้างวิดีโอ จากที่ต้องรอหลายวินาทีหรือนาที เป็นการตอบสนองแบบทันที
เทรนด์การใช้ Claude Code ในธุรกิจและการพัฒนา
ในชุมชนผู้ใช้ Claude มีหลายเทรนด์ที่น่าสนใจ ผู้ใช้บางรายเปลี่ยนมาใช้ Claude Code เป็นเครื่องมือหลักแทน Claude.ai โดยสิ้นเชิง โดยรวมระบบ CRM, content management และ lead sourcing เข้าไว้ในคำสั่งเดียวจาก terminal มีตัวอย่างการตั้งค่า agent หลายตัวที่ทำงานต่อเนื่องกันตั้งแต่รวบรวมข้อมูล ออกแบบเว็บไซต์ ไปจนถึง deploy บน Vercel ใช้เวลาเพียง 30 นาที ถึง 6 ชั่วโมง
Anthropic ยังเปิดตัว remote access สำหรับ Claude Cowork ในรูปแบบ research preview สำหรับสมาชิก Max ที่ช่วยให้เริ่มงานจากมือถือและทำต่อบนเดสก์ท็อปได้ ขณะที่มีการสร้างระบบ Obsidian + Claude ที่ใช้ MCP server ส่วนตัวเพื่อแชร์ context ข้ามเซสชัน พร้อม multi-agent orchestrator ที่ประสานงานระหว่าง Claude, Codex และ Gemini CLI
บทความนี้รวบรวมข้อมูลจากแหล่งข่าวเทคโนโลยี AI หลายแห่ง ณ วันที่ 19 มีนาคม พ.ศ. 2569 ข้อมูลอาจมีการเปลี่ยนแปลงได้ตามพัฒนาการของเทคโนโลยี