
Anthropic เปิดตัว Claude Cowork ตอบโต้ OpenClaw — OpenAI ปล่อย GPT-5.4 Mini/Nano เน้น agent เขียนโค้ด
Anthropic เปิดตัว Claude Cowork — คำตอบต่อ OpenClaw ที่หลายคนเปรียบเทียบในเชิงบวก
หลังจากที่ Jensen Huang กล่าวบนเวที GTC ว่าทุกบริษัทต้องมีกลยุทธ์ OpenClaw Anthropic ก็มีคำตอบของตัวเองแล้ว — Claude Cowork ถูกเปิดตัวอย่างเป็นทางการ
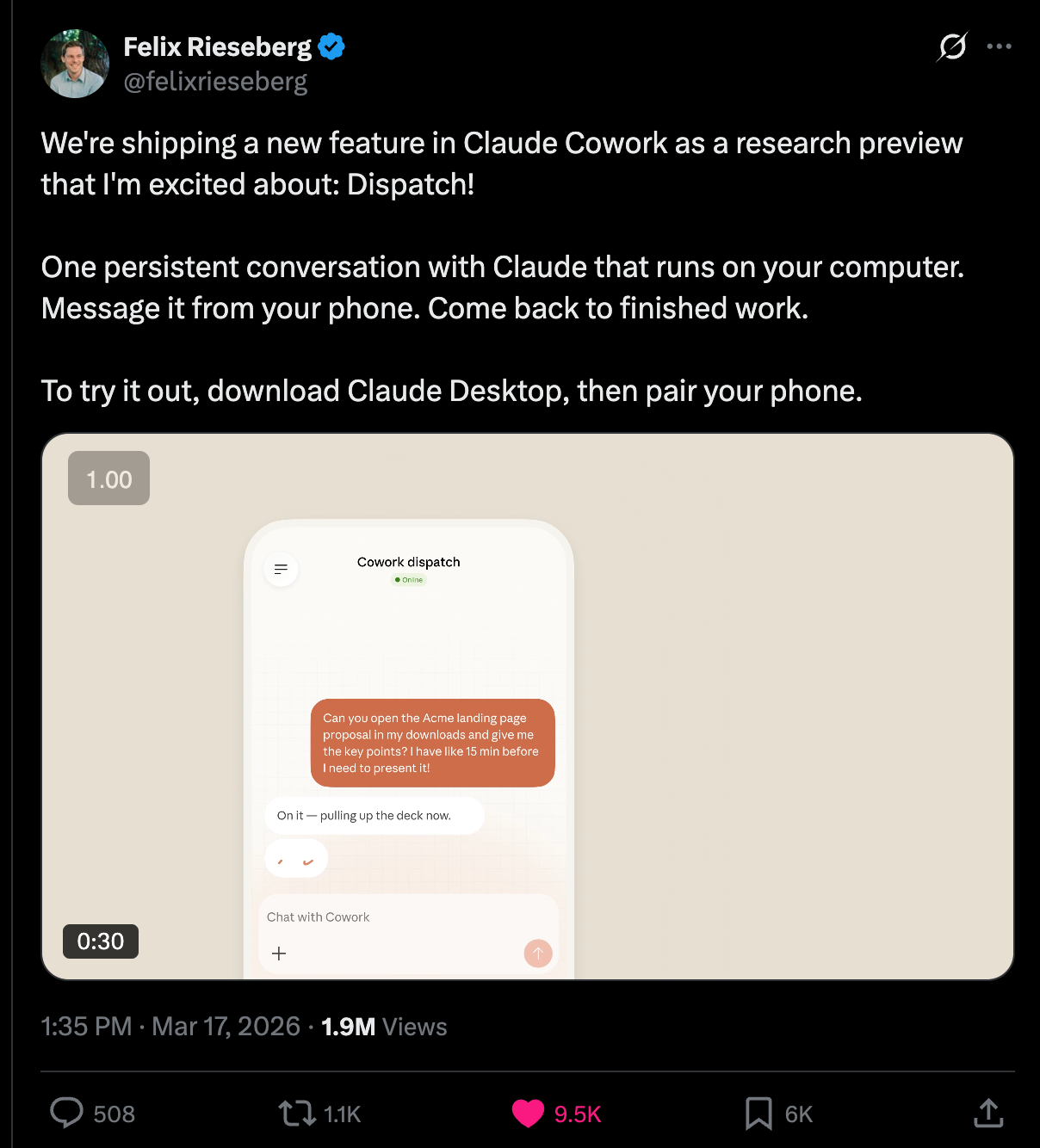
หลายคนตั้งแต่ Simon Willison ไปจนถึง Ethan Mollick เปรียบเทียบ Claude Cowork กับ OpenClaw ในเชิงบวก Anthropic ที่เคยถูกวิจารณ์ว่า "ทำพลาด" ในเรื่องความสัมพันธ์กับ Clawdbot ตอนนี้มีคำตอบแล้ว — และเป็นคำตอบที่ค่อนข้างดี โดยเฉพาะในด้านการเลือกเทคนิคเกี่ยวกับ sandboxing และ Electron
OpenAI เปิดตัว GPT-5.4 Mini และ Nano — เร็วขึ้น 2 เท่า พร้อมหน้าต่างบริบท 400K สำหรับ agent เขียนโค้ด
OpenAI เปิดตัว GPT-5.4 mini และ GPT-5.4 nano วางตำแหน่งเป็นโมเดลขนาดเล็กที่มีความสามารถสูงสุด GPT-5.4 mini เร็วกว่า GPT-5 mini มากกว่า 2 เท่า เน้นงานเขียนโค้ด, computer use, ความเข้าใจมัลติโมดัล และ subagents พร้อมหน้าต่างบริบท 400K บน API
OpenAI ยังอ้างว่า mini เข้าใกล้ประสิทธิภาพของ GPT-5.4 ขนาดใหญ่ในการประเมินรวมถึง SWE-Bench Pro และ OSWorld-Verified โดยใช้โควตา Codex เพียง 30% ของ GPT-5.4 ทำให้เป็นค่าเริ่มต้นใหม่สำหรับขั้นตอนการทำงานเขียนโค้ดพื้นหลังและการกระจาย subagent
การตอบรับ GPT-5.4 Mini — ดีด้านเขียนโค้ด แต่ราคาสูงขึ้นและยังมีจุดอ่อนเรื่องความจริง
นักพัฒนาเน้นประโยชน์ของ mini สำหรับ subagents ใน Codex, งาน computer-use และผลิตภัณฑ์ภายนอกเช่น Windsurf แต่ความคิดเห็นยังมุ่งไปที่รูปแบบที่คุ้นเคยของ OpenAI — ประสิทธิภาพดีขึ้นแต่ราคาสูงขึ้น
- ราคา mini — $0.75/ล้านโทเค็นขาเข้า และ $4.5/ล้านโทเค็นขาออก
- Mercor APEX-Agents — รายงาน 24.5% Pass@1 สำหรับ mini ด้วย xhigh reasoning นำหน้าคู่แข่งบางรายในการทดสอบนี้
- BullshitBench — โมเดลขนาดเล็กใหม่ได้คะแนนค่อนข้างต่ำในการต้านทานกับดักข้อเท็จจริงเท็จ/ศัพท์เฉพาะ
OpenAI ยังยอมรับปัญหาการปรับแต่งพฤติกรรม — @michpokrass กล่าวว่าอัปเดต 5.3 instant ล่าสุดลดพฤติกรรม "clickbait น่ารำคาญ" ลง
โครงสร้างพื้นฐาน Agent — sandbox, subagents และ Open SWE กำลังสุกงอม
หลายการเปิดตัวชี้ไปที่ชุดเครื่องมือที่สุกงอมรอบการทำงานที่ปลอดภัย การประสานงาน และความสะดวกในการติดตั้ง มากกว่าแค่โมเดลพื้นฐานที่ดีขึ้น
- LangSmith Sandboxes — LangChain เปิดตัว sandbox สำหรับการรันโค้ดชั่วคราวที่ปลอดภัย โดย @hwchase17 แย้งอย่างชัดเจนว่า "agent จำนวนมากขึ้นเรื่อย ๆ จะเขียนและรันโค้ด"
- Open SWE — LangChain เปิดเผย agent เขียนโค้ดพื้นหลังแบบโอเพนซอร์ส ตามแบบระบบภายในที่ใช้ที่ Stripe, Ramp และ Coinbase รวมกับ Slack, Linear และ GitHub ใช้ subagents บวก middleware แยกชั้นโครงร่างควบคุม, sandbox, ชั้นเรียก และการตรวจสอบ
นี่เป็นก้าวสำคัญจาก "chat copilots" ไปสู่ agent วิศวกรรมภายในที่ติดตั้งใช้งานได้จริง
Subagents และการรันโค้ดที่ปลอดภัยกลายเป็นฟีเจอร์ระดับ first-class ทั่วทั้งระบบนิเวศ
Codex ของ OpenAI รองรับ subagents แล้ว และ GPT-5.4 mini ถูกวางตำแหน่งว่าเหมาะสมเป็นพิเศษสำหรับกรณีใช้งานนี้ Hermes Agent v0.3.0 เป็นอีกสัญญาณที่แข็งแกร่ง — 248 PR ใน 5 วัน พร้อมฟีเจอร์ต่าง ๆ
- สถาปัตยกรรมปลั๊กอิน — ระดับ first-class
- ควบคุม Chrome แบบสด — ผ่าน CDP
- โหมดเสียง — ใช้ Whisper ในเครื่อง
- การปกปิด PII — ลบข้อมูลส่วนบุคคลอัตโนมัติ
- การรวมระบบ IDE — พร้อมผู้ให้บริการอย่าง Browser Use
ทิศทางสอดคล้องกันทั่วทั้งผู้ให้บริการ — มูลค่าของ agent ขึ้นอยู่กับสภาพแวดล้อมการรันที่ปลอดภัย ทักษะ/ปลั๊กอินที่ประกอบได้ และพื้นผิวที่เหมาะกับขั้นตอนการทำงานมากกว่าแค่ผลการทดสอบดิบ
Attention Residuals และ "vertical attention" — attention ข้ามเลเยอร์กำลังมาแรง
งานวิจัย Attention Residuals ของ Moonshot บน arXiv จุดชนวนการอภิปรายทางเทคนิคอย่างมากเกี่ยวกับ "vertical attention" หรือ attention ข้ามเลเยอร์ คำอธิบายจาก @ZhihuFrontier วางกรอบแนวคิดว่าแต่ละเลเยอร์ query สถานะของเลเยอร์ก่อนหน้า — ขยาย attention จากการโต้ตอบแบบแนวนอนในลำดับไปสู่หน่วยความจำระหว่างเลเยอร์
ปฏิกิริยาจากชุมชนเน้นว่าแนวคิดนี้ไม่ได้แยกตัว — @rosinality ชี้ว่า ByteDance ก็ทำ attention over depth เช่นกัน ข้อเรียกร้องทางระบบที่น่าสนใจคือ เนื่องจากจำนวนเลเยอร์ << ความยาวลำดับ vertical attention บางรูปแบบอาจซ่อนอยู่ใต้การคำนวณที่มีอยู่และแทบไม่เพิ่มความหน่วง
Mamba-3 เสริมกรณีของสถาปัตยกรรม hybrid ที่เน้น inference — เร็วที่สุดสำหรับ prefill+decode ที่ 1.5B
อีกหนึ่งการเปิดตัวสถาปัตยกรรมสำคัญคือ Mamba-3 นำเสนอโดย @_albertgu และ @tri_dao เป็นก้าวล่าสุดในการทำให้โมเดล linear/state-space แข่งขันได้มากขึ้นในยุค hybrid โดยเน้นประสิทธิภาพ inference อย่างชัดเจน ไม่ใช่การแทนที่ transformer ทั้งหมด
- ประสิทธิภาพ — แข็งแกร่งที่สุดในบรรดาโมเดล linear
- ความเร็ว — prefill+decode เร็วที่สุดที่ 1.5B
- กรณีใช้งาน — RL ที่เน้น inference และงาน rollout ยาวเป็นพื้นที่ที่อุดมสมบูรณ์เป็นพิเศษ
ประเด็นที่กว้างกว่าจากทั้ง Attention Residuals และ Mamba-3 คือห้องปฏิบัติการยังคงค้นหาวิธีผ่อนคลายคอขวดของ full-transformer โดยไม่เสียความเข้ากันได้กับระบบนิเวศมากเกินไป
GTC เน้นข้อความ inference, agents และโลกทัศน์ "โรงงานโทเค็น"
หลายโพสต์สะท้อนการวางกรอบของ Jensen Huang ว่าคอมพิวเตอร์ในอนาคตคือระบบสำหรับ "การผลิตโทเค็น" โดย inference กำลังขับเคลื่อนคลื่นกำลังการผลิตถัดไป
- LangChain — เฟรมเวิร์กทะลุ 1 พันล้านการดาวน์โหลดและเข้าร่วม NVIDIA Nemotron Coalition
- Nemotron 3 Nano 4B — @ggerganov เน้นการรองรับใน llama.cpp
- Hugging Face — สรุปการเปิดเผยของ NVIDIA ตั้งแต่โมเดลให้เหตุผล ชุดข้อมูลหุ่นยนต์ ไปจนถึง world models
เครื่องมือ agent แบบเปิดและระดับองค์กรครอง GTC — H Company, Perplexity และ Jensen เรื่อง $1T
- H Company — Holotron-12B — โมเดลมัลติโมดัลแบบเปิดที่สร้างร่วมกับ NVIDIA สำหรับ agent ที่ใช้คอมพิวเตอร์
- Perplexity — Comet Enterprise — นำ AI browser มาสู่ทีมองค์กร พร้อมการควบคุมการเผยแพร่และการรวม CrowdStrike Falcon
- Jensen เรื่อง $1T — @TheTuringPost เน้นคำพูดของ Jensen ว่าโอกาสโครงสร้างพื้นฐาน AI มูลค่า 1 ล้านล้านดอลลาร์ที่มักถูกอ้างถึงนั้นครอบคลุมแค่ส่วนหนึ่งของสแต็กถึงปี 2027 เสริมว่าอุตสาหกรรมยังอยู่ในช่วงเริ่มต้นมากของการสร้างโครงสร้างพื้นฐาน inference
เครื่องมือโอเพนซอร์สและ agent ในเครื่อง — Unsloth Studio, hf CLI และ Ollama อัปเกรด
- Hugging Face hf CLI — ส่วนขยายที่ตรวจจับโมเดล/quant ท้องถิ่นที่ดีที่สุดสำหรับฮาร์ดแวร์ที่มีอยู่โดยอัตโนมัติ แล้วเปิด agent เขียนโค้ดในเครื่อง
- Unsloth Studio — web UI โอเพนซอร์สสำหรับฝึกและรันโมเดลมากกว่า 500 ตัวในเครื่อง ทั้ง Mac/Windows/Linux อ้างว่าฝึกเร็วขึ้น 2 เท่าใช้ VRAM น้อยลง 70% รองรับ GGUF ข้อมูลสังเคราะห์ tool calling และการรันโค้ด
- Ollama — เพิ่มปลั๊กอิน web search/fetch และรองรับการเปิดแบบ headless สำหรับขั้นตอนการทำงาน OpenClaw
ระบบนิเวศ "agent เขียนโค้ดแบบเปิด" ชัดเจนขึ้น — แนวหน้าไม่ใช่แค่โมเดลเปิดอีกต่อไป แต่เป็นโครงร่างควบคุมเปิด
มีการบรรจบกันที่เพิ่มขึ้นบนรูปแบบ — โครงร่างควบคุมที่ไม่ผูกกับโมเดล ทักษะที่มีโครงสร้าง abstractions สำหรับระบบไฟล์/สถานะ และการรันแบบชั่วคราวบนคลาวด์หรือในเครื่อง
- LangChain Deep Agents — สร้างซ้ำโครงร่างควบคุมแบบ Claude Code ภายใต้สัญญาอนุญาต MIT ตรวจสอบได้
- Hermes Agent — ระบบปลั๊กอินและความเป็นมิตรกับโมเดลในเครื่องผลักดันเข้าสู่การสนทนาเดียวกัน
นี่เป็นหนึ่งในแนวโน้มที่ชัดเจนที่สุด — แนวหน้าไม่ใช่แค่โมเดลที่มีน้ำหนักเปิดอีกต่อไป แต่เป็นโครงร่างควบคุมเปิดและชั้นรันไทม์สำหรับการติดตั้ง agent จริง
ทวีตเด่นประจำสัปดาห์ — GPT-5.4 Mini, Cursor RL, Mamba-3, Unsloth Studio ครองชาร์ต
- GPT-5.4 mini/nano — ประกาศเทคนิคที่สำคัญที่สุดของวัน โดยเฉพาะสำหรับงาน agent เขียนโค้ด
- Cursor RL-based context compaction — Cursor ฝึก Composer ให้สรุปตัวเองผ่าน RL แทนการใช้ prompt ลดข้อผิดพลาดการบีบอัด 50%
- Mamba-3 — หนึ่งในอัปเดตสถาปัตยกรรมที่สำคัญที่สุดในการสร้างแบบจำลองลำดับรอบนี้
- Unsloth Studio — การเปิดตัวผลิตภัณฑ์โอเพนซอร์สที่แข็งแกร่งที่สุด เน้นผู้ปฏิบัติงานด้านการฝึก/inference ในเครื่อง
- Kimi Attention Residuals — ขับเคลื่อนการอภิปรายด้านสถาปัตยกรรมส่วนใหญ่
Unsloth Studio บน Reddit — UI โอเพนซอร์สสำหรับฝึกโมเดลในเครื่องที่ได้รับเสียงตอบรับดี
Unsloth Studio ได้รับความสนใจสูงบน Reddit (998 + 579 activity) ในฐานะคู่แข่ง LMStudio แบบโอเพนซอร์ส เข้ากันได้กับ Llama.cpp รองรับ auto-healing tool calling, การรันโค้ด Python/bash, เสียง วิชัน และ LLM finetuning ติดตั้งง่ายผ่าน pip install unsloth
ผู้แสดงความคิดเห็นชื่นชมการมี fine-tuning และ inference รวมอยู่ในเครื่องมือเดียว ต่างจากปัจจุบันที่ต้องใช้หลายโปรเจกต์ ยังมีการรอคอยการรองรับ AMD อย่างเป็นทางการที่จะช่วยขยายการใช้งาน
Qwen3.5-9B ทำได้ดีในการทดสอบเอกสาร — ชนะโมเดลระดับแนวหน้าในบางด้าน
Qwen3.5-9B อันดับ #9 ด้วยคะแนน 77.0 ในการทดสอบเอกสาร AI เทียบกับ GPT-5.4 ที่อันดับ #4 ด้วยคะแนน 81.0 โดย Qwen3.5-9B ทำได้ดีเป็นพิเศษใน "Key Information Extraction" และ "Table Understanding" รวมถึง OmniOCR แต่ตามหลังใน OmniDoc และ IDP Core
ผู้แสดงความคิดเห็นชี้ว่าโมเดลขนาดเล็กอย่าง Qwen3.5-9B สามารถทำงานได้อย่างมีประสิทธิภาพบนฮาร์ดแวร์ระดับล่าง เช่น ultrabooks ทำให้เป็นตัวเลือกที่ประหยัดพลังงานสำหรับงานที่ไม่ต้องการเวลาตอบสนองเร็วที่สุด
Mistral Small 4 — โมเดล hybrid 119B พารามิเตอร์ ลดความหน่วง 40% รวมความสามารถ 3 ตระกูล
Mistral Small 4 เป็นโมเดล hybrid ขนาด 119 พันล้านพารามิเตอร์ หน้าต่างบริบท 256K ที่รวมความสามารถจาก 3 ตระกูลโมเดล — Instruct, Reasoning (เดิมคือ Magistral) และ Devstral ใช้สถาปัตยกรรม MoE กับผู้เชี่ยวชาญ 128 ตัว และใช้งาน 4 ตัวต่อครั้ง (6.5B พารามิเตอร์ที่ใช้งานจริง)
- ความหน่วง — ลดลง 40%
- สัญญาอนุญาต — Apache 2.0 สำหรับทั้งเชิงพาณิชย์และไม่ใช่เชิงพาณิชย์
- ฟีเจอร์ — รองรับมัลติโมดัล ความพยายามในการให้เหตุผลที่ปรับได้ function calling ดั้งเดิม
มีการเปรียบเทียบกับ Qwen3.5-122B-A10B — Mistral ใช้งาน 6.5B พารามิเตอร์ ขณะที่ Qwen3.5 ใช้ 10B ซึ่งอาจอธิบายว่าทำไม Mistral ไม่ชนะ Qwen3.5 ในภาพรวม อย่างไรก็ตาม pool ผู้เชี่ยวชาญที่ใหญ่กว่าอาจเป็นข้อได้เปรียบในบางงาน
DGX Station พร้อมจำหน่ายผ่านตัวแทน OEM — ราคา 85-90K ดอลลาร์
NVIDIA DGX Station พร้อมจำหน่ายผ่านตัวแทน OEM เช่น Dell และ Exxact ในราคา 85,000-90,000 ดอลลาร์ (418 activity) เครื่องออกแบบมาสำหรับงาน AI และ deep learning พร้อมระบบระบายความร้อนขั้นสูง จุดที่น่าสนใจคือแนวคิด "coherent memory" ที่อนุญาตให้แบ่งปันข้อมูลระหว่าง CPU และ GPU อย่างมีประสิทธิภาพ แต่เครื่องไม่มีเอาต์พุตวิดีโอเว้นแต่จะติดตั้งการ์ดเพิ่ม — สะท้อนการออกแบบที่เน้นงานคำนวณไม่ใช่งานกราฟิก
NVIDIA Nemotron 3 Ultra ~500B — อ้างว่าเป็นโมเดลเปิดที่ดีที่สุด แต่ถูกตั้งคำถามเรื่องการเปรียบเทียบ
สไลด์จากงานนำเสนอ NVIDIA แสดง Nemotron 3 Ultra Base ขนาดประมาณ 500B อ้างว่าเป็น "โมเดลเปิดพื้นฐานที่ดีที่สุด" ด้วยประสิทธิภาพ 5 เท่า ผู้แสดงความคิดเห็นแสดงความสงสัยเกี่ยวกับการทดสอบ — NVIDIA ไม่ระบุว่าใช้ GLM รุ่นไหนสำหรับเปรียบเทียบ และโมเดล Kimi K2 นั้นเก่า 8 เดือนแล้ว ยังมีการวิจารณ์เทคนิคการนำเสนอที่เริ่มกราฟที่ 60% ซึ่งทำให้ช่องว่างดูใหญ่เกินจริง
CEO Anthropic คาดว่า 50% ของงานระดับเริ่มต้นจะหายไปใน 3 ปี
CEO ของ Anthropic ทำนายว่า 50% ของงานระดับเริ่มต้นสำหรับพนักงานออฟฟิศจะถูกกำจัดภายใน 3 ปีข้างหน้า เนื่องจากความก้าวหน้าของเทคโนโลยี AI (2,162 activity) คำกล่าวนี้เน้นย้ำการรวม AI เข้ากับสถานที่ทำงานอย่างรวดเร็ว อาจแทนที่งานที่มนุษย์ทำมาโดยตลอด
ผู้แสดงความคิดเห็นเน้นประสบการณ์ส่วนตัวที่ AI ถูกใช้ทำงานอย่างไม่เหมาะสม นำไปสู่ข้อผิดพลาดและข้อสรุปที่ไม่ถูกต้อง แต่ฝ่ายบริหารอาจเลือก AI เพราะความเร็ว ทำลายคุณค่าของคนทำงานที่มีทักษะ มีการเรียกร้องนโยบายเช่น Universal Basic Income เพื่อรับมือกับการเปลี่ยนแปลงนี้
ผลสำรวจ NBC — คนอเมริกันมองลบต่อ AI มากกว่าเกือบทุกหัวข้อ
ผลสำรวจของ NBC News เปิดเผยว่ามีเพียง 26% ของผู้มีสิทธิเลือกตั้งที่มองบวกต่อ AI ขณะที่ 46% มองลบ ทำให้ AI เป็นที่นิยมน้อยกว่าเกือบทุกหัวข้อ (1,146 activity)
ผู้แสดงความคิดเห็นชี้ว่ามีข้อขัดแย้ง — ผู้ใช้ AI บ่อยยังคงมีความไม่พอใจเนื่องจากการอ้างเกินจริงเกี่ยวกับความสามารถของ AI โดยเฉพาะเรื่องการแทนที่งาน การรับรู้ของสาธารณชนถูกครอบงำโดยภาพลบเช่นการเลิกจ้างและการเฝ้าระวัง มากกว่าการใช้งานจริงเช่น chatbot เพื่อการศึกษา