
Context Drought — หน้าต่างบริบท 1 ล้านโทเค็นยังติดคอขวด HBM และวงการ AI อาจต้อง "ปันส่วน" บริบทในอนาคต
Anthropic เปิดใช้งานหน้าต่างบริบท 1 ล้านโทเค็นอย่างเป็นทางการ — แต่มาช้ากว่า Gemini และ OpenAI
Anthropic ได้รับเสียงชื่นชมจากการเปิดให้ใช้งานโมเดลที่รองรับหน้าต่างบริบท 1 ล้านโทเค็นแบบ GA (General Availability) อย่างเป็นทางการ พร้อมผลทดสอบ MRCR (Multi-Round Context Retrieval) ที่ทำได้สูงสุดเป็นประวัติการณ์ — ช่วยต่อสู้กับปัญหา Context Rot (การเสื่อมสลายของบริบท) ได้นานที่สุดเท่าที่เป็นไปได้
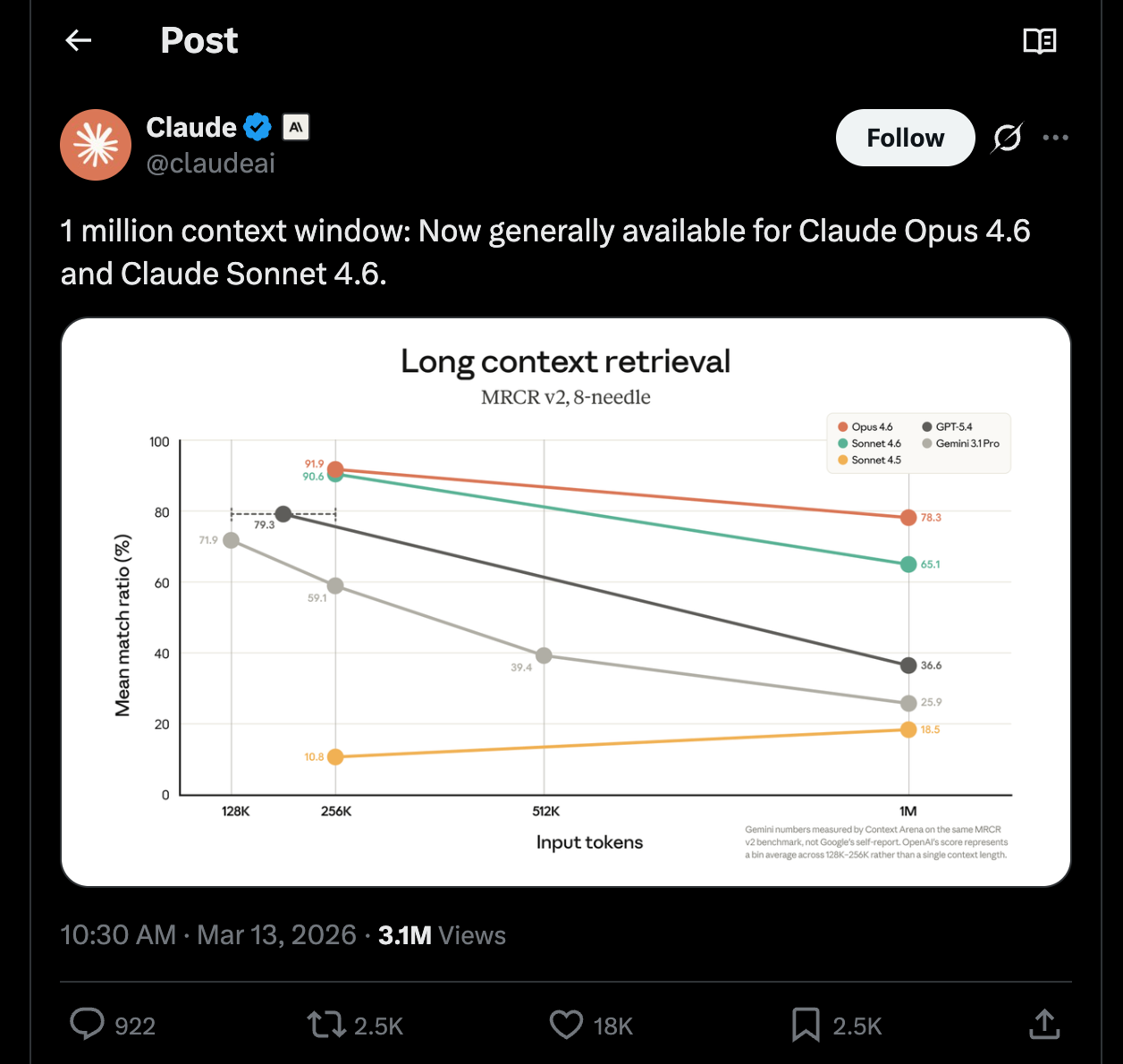
แม้จะเป็นฟีเจอร์ที่มีประโยชน์อย่างมาก และโมเดลที่ขยับเขตแดนของ "โซนโง่" จากการบีบอัดบริบทออกไปได้ไกลขึ้นนั้นเป็นสิ่งที่น่ายินดี แต่ก็ต้องย้อนรำลึกว่าหน้าต่างบริบท 1 ล้านโทเค็นเคยเปิดให้ใช้งาน GA ตั้งแต่เดือนมีนาคม 2024 — หลังจากที่ Gemini ทำได้ตั้งแต่กุมภาพันธ์ 2024 — และ Anthropic เพิ่งมาเปิดให้ใช้งานหลังจาก OpenAI เปิด GA ของตัวเองไปเมื่อสัปดาห์ก่อน
นับจากที่หน้าต่างบริบท 1 ล้านโทเค็นเป็นไปได้ในทางทฤษฎีมาแล้ว 2 ปีเต็ม หมายความว่าการเติบโตของขนาดหน้าต่างบริบทอยู่ที่ต่ำกว่า 1 หลัก (order of magnitude) ในรอบ 2 ปี — ซึ่งช้ากว่ามากเมื่อเทียบกับมิติอื่น ๆ ของ LLM (ไม่ว่าจะเป็นต้นทุน ความเร็ว หรือคุณภาพ)
ทำไมหน้าต่างบริบทถึงไปต่อไม่ได้ — ปัญหาคือ HBM และ DRAM ขาดแคลนทั่วโลก
สาเหตุหลักอยู่ที่ วิกฤตหน่วยความจำระดับโลก — ไม่มี HBM (High Bandwidth Memory) หรือแม้แต่ DRAM เพียงพอที่จะรองรับบริบทมหาศาลเหล่านี้ที่ฝั่งการประมวลผล (inference) ได้ พอดแคสต์กับ Doug O'Laughlin ให้รายละเอียดเรื่องนี้อย่างชัดเจน
swyx กล่าวว่า ทุกคนรวมถึง Sam Altman ต่างทำนายว่าหน้าต่างบริบทจะยาวขึ้น แต่ในความเป็นจริงมันติดอยู่ที่ 1 ล้านมา 2 ปีแล้ว และจะไม่ไปถึง 100 ล้านหรือ 1 ล้านล้านโทเค็น — "นี่คือจุดที่เราอยู่แล้ว อาจจะอีก 5-10 ปี"
Doug O'Laughlin เสริมว่าสิ่งที่อาจเกิดขึ้นคือ "การปันส่วนบริบท" (context rationing) — ผู้ใช้ฟรีอาจได้หน้าต่างบริบทเพียง 1,000 โทเค็น ขณะที่บริบท 1 ล้านโทเค็นจะถูกตั้งราคาเป็น "คฤหาสน์" ของโลก AI
ทาง AINews ตั้งเดิมพันว่า หน้าต่างบริบทจะไม่เพิ่มขึ้นอย่างมีนัยสำคัญจาก 1 ล้านในอีก 2 ปีข้างหน้า — ซึ่งถือเป็นการเดิมพันครั้งใหญ่ในเวลา AI
Anthropic อัปเดตโครงสร้างพื้นฐาน — Opus 4.6 รองรับ 1 ล้านโทเค็นเป็นค่าเริ่มต้น พร้อมยกเลิกค่าธรรมเนียมพิเศษ
Anthropic ปล่อยอัปเดตด้านโครงสร้างพื้นฐานที่สำคัญอย่างเงียบ ๆ — Opus 4.6 ที่รองรับบริบท 1 ล้านโทเค็นกลายเป็นค่าเริ่มต้นสำหรับผู้ใช้ Max, Team และ Enterprise พร้อมกันนั้นได้ ยกเลิกค่าธรรมเนียมพิเศษสำหรับบริบทยาว บน API ถอดข้อกำหนด beta header ออก และขยายขีดจำกัดสื่อเป็น 600 รูปภาพ/หน้า PDF ต่อคำขอ
ตัวเลขที่น่าจับตามองที่สุดคือ 78.3% บน MRCR v2 ที่ 1 ล้านโทเค็น — ซึ่งผู้สังเกตการณ์หลายรายเรียกว่าเป็นสถิติสูงสุดใหม่ของการทดสอบบริบทยาว
MCP ถูกประกาศ "ตาย" บน Twitter — แต่ความต้องการยังพุ่ง
กระแสวิพากษ์ MCP (Model Context Protocol) ส่วนใหญ่เป็นเรื่องของ ความสะดวกในการใช้งาน ไม่ใช่ความต้องการ — วิศวกรจำนวนมากถกเถียงกันว่า MCP "ตาย" แล้วหรือแค่ถูกพูดถึงมากเกินไป @pamelafox ล้อเลียนว่า "MCP ถูกประกาศตายบน Twitter หลังจากคนลองใช้ curl" ขณะที่ @tadasayy โต้แย้งว่ายอดการใช้งานยังเพิ่มขึ้นต่อเนื่อง
มุมมองที่มีสาระมากกว่ามาจาก @llama_index — MCP tools เหมาะเมื่อต้องการ API ที่กำหนดไว้แน่นอนและดูแลจากส่วนกลาง รวมถึงข้อมูลพื้นฐานที่เปลี่ยนแปลงเร็ว ส่วน skills นั้นเบากว่าแต่มีโอกาสผิดพลาดสูงกว่า นอกจากนี้ @bromann ชี้ให้เห็นว่า Chrome v146 เพิ่มการรองรับ MCP บนเว็บ โดยแสดง LangChain Deep Agent ที่ท่องเว็บ X อย่างต่อเนื่องและสรุปรายวัน
หน่วยความจำกลายเป็นตัวแปรสำคัญของ AI Agent — IBM พิสูจน์ว่าการเรียนรู้จากประสบการณ์ช่วยเพิ่มประสิทธิภาพได้จริง
เธรดเชิงเทคนิคที่น่าสนใจที่สุดเกี่ยวกับ agent คือเรื่อง หน่วยความจำถาวรและการปรับปรุงตัวเอง — @dair_ai เน้นงานวิจัยของ IBM ที่สกัดเคล็ดลับด้านกลยุทธ์ การกู้คืน และการเพิ่มประสิทธิภาพที่นำกลับมาใช้ซ้ำได้จากเส้นทางการทำงานของ agent ผลลัพธ์คือการทำงานใน AppWorld เพิ่มจาก 69.6% เป็น 73.2% และเป้าหมายสถานการณ์เพิ่มจาก 50.0% เป็น 64.3% — โดยได้ผลมากที่สุดในงานที่ยาก
ในขณะเดียวกัน @omarsar0 สรุปงานวิจัยที่มองหน่วยความจำของระบบ multi-agent เป็นปัญหาสถาปัตยกรรมคอมพิวเตอร์ — มีลำดับชั้นแคช/หน่วยความจำ ความสอดคล้อง และการควบคุมการเข้าถึง แทนที่จะเป็นแค่ "เพิ่มบริบท" ซึ่งสอดคล้องกับผลิตภัณฑ์อย่าง Hermes Agent — agent ที่โฮสต์ได้เอง เก็บรักษาทักษะและหน่วยความจำเฉพาะผู้ใช้ไว้ตลอดเวลา
Agent UX กำลังเปลี่ยนไปสู่โหมดทำงานต่อเนื่องข้ามอุปกรณ์
หลายผลิตภัณฑ์ที่เปิดตัวสัปดาห์นี้ผลักดัน agent ให้เข้าใกล้แนวคิด "คอมพิวเตอร์ส่วนบุคคลเป็นผู้ประสานงาน" มากขึ้น
- Perplexity Computer — เปิดตัวบน iOS พร้อมการซิงโครไนซ์ข้ามอุปกรณ์ ให้ผู้ใช้เริ่มหรือจัดการงาน browser-computer จากโทรศัพท์หรือเดสก์ท็อปได้
- Claude Code — @bcherny แสดงวิธีเริ่มเซสชันจากแล็ปท็อปผ่านโทรศัพท์
- Genspark Claw — ถูกนำเสนอเป็น "พนักงาน AI" ที่มีคอมพิวเตอร์คลาวด์ถาวร
รูปแบบร่วมกันคือ — สถานะเซสชันถาวร การทำงานแบบรีโมต และการประสานงานข้ามหลายโมเดล/เครื่องมือ
IndexCache เพิ่มความเร็ว sparse attention ใน DeepSeek — ลดดัชนี 75% แต่คุณภาพเท่าเดิม
เธรดด้านระบบที่โดดเด่นมาจาก @realYushiBai ที่แนะนำ IndexCache — เทคนิคที่นำข้อมูลดัชนีของ sparse attention กลับมาใช้ซ้ำข้ามเลเยอร์ใน DeepSeek Sparse Attention
- GLM-5 (744B) — เร็วขึ้น ~1.2 เท่าแบบครบกระบวนการ โดยคุณภาพเท่าเดิม
- โมเดลทดลอง 30B ที่บริบท 200K — prefill เร็วขึ้น 1.82 เท่า และ decode เร็วขึ้น 1.48 เท่า หลังลบดัชนี 75% ออก
สิ่งที่น่าสนใจคือเทคนิคนี้เป็นการเพิ่มประสิทธิภาพเชิงปฏิบัติที่ต้องการ "การเปลี่ยนโค้ดน้อยมาก" — ซึ่งเป็นประเภทของการปรับปรุงที่ห้องปฏิบัติการต่าง ๆ ให้ความสำคัญในตอนนี้
การเพิ่มประสิทธิภาพ KV/cache กำลังขยายออกไปนอกเหนือจาก LLM แบบ autoregressive
@RisingSayak เน้น Klein KV ของ Black Forest Labs ที่ฉีด KV แคชจากภาพอ้างอิงเข้าสู่ขั้นตอน denoising ของ DiT ในภายหลัง สำหรับการแก้ไขภาพแบบหลายอ้างอิง — อ้างว่าเร็วขึ้นถึง 2.5 เท่า
ด้านโครงสร้างพื้นฐาน Satya Nadella กล่าวว่า Microsoft เป็นผู้ให้บริการคลาวด์รายแรกที่ตรวจสอบระบบ NVIDIA Vera Rubin NVL72 ขณะที่ @LambdaAPI ผลักดันแนวคิด "bare metal เหนือ hypervisor" สำหรับคลัสเตอร์ยุค Rubin และ @tinygrad เสนอจุดสิ้นสุดที่รุนแรงกว่า — "exabox" ที่เปิดเผยเป็น GPU ยักษ์ตัวเดียวที่ควบคุมด้วย Python ในปี 2027
งานวิจัยสุดท้าทาย — การค้นหาแบบ Gaussian สุ่มเทียบชั้น RL fine-tuning ได้
ผลการวิจัยด้าน post-training ที่ถูกพูดถึงมากที่สุดคือ RandOpt / Neural Thickets จากผู้เขียนในเครือ MIT — อ้างว่าเพียงแค่เพิ่มสัญญาณรบกวนแบบ Gaussian ลงในน้ำหนักของโมเดลที่ผ่านการ pretrain แล้ว จากนั้นทำ ensembling ก็สามารถทำได้เทียบเท่าหรือดีกว่า GRPO/PPO ในงานด้านการให้เหตุผล การเขียนโค้ด การเขียน เคมี และ VLM
คำอธิบายคือโมเดล pretrain ขนาดใหญ่อาศัยอยู่ในย่านท้องถิ่นที่หนาแน่นไปด้วยผู้เชี่ยวชาญเฉพาะงานที่มีประโยชน์ — เรียกว่า "neural thickets" — ทำให้ post-training ง่ายกว่าที่สัญชาตญาณการเพิ่มประสิทธิภาพแบบมาตรฐานจะคาดการณ์ไว้
Generic Data Replay และ Pre-Pre-Training — ได้รับความสนใจอีกครั้ง
@TheTuringPost สรุปงานวิจัยของ Stanford เกี่ยวกับ generic data replay ที่รายงานการปรับปรุง 1.87 เท่า ระหว่าง fine-tuning และ 2.06 เท่า ระหว่าง mid-training พร้อมผลลัพธ์ downstream ที่เป็นรูปธรรม เช่น +4.5% ในการนำทางเว็บแบบ agentic และ +2% ใน Basque QA
การสนทนาแยกต่างหากเกี่ยวกับ "pre-pre-training" บ่งบอกว่าชุมชนกำลังทบทวนการออกแบบขั้นตอน/ส่วนผสมในช่วงต้นของ training pipeline ไม่ใช่แค่เทคนิค post-training อีกต่อไป
การประเมินยังเป็นคอขวด — แม้แต่ GPT-5.4 ก็ปฏิเสธข้อความทางคณิตศาสตร์ที่ผิดได้แค่ 40%
BrokenArXiv เป็นการทดสอบที่แม้แต่ GPT-5.4 ก็ปฏิเสธข้อความทางคณิตศาสตร์ที่ถูกดัดแปลงให้ผิดจากบทความล่าสุดได้เพียง 40% เท่านั้น @paul_cal แย้งว่าสิ่งนี้ทำให้ GPT-5.4 ได้เปรียบ Claude ในด้านการตรวจจับข้อผิดพลาดแบบ "การตรวจสอบการพิสูจน์" แม้ว่าการทดสอบความถูกต้องอื่น ๆ จะไม่เห็นด้วยก็ตาม
สำหรับการค้นคืน/ค้นหา MADQA พบว่า agent ทำได้ใกล้เคียงกับความแม่นยำในการตอบของมนุษย์ โดยใช้การค้นหาแบบไล่ทีละรายการแทนการนำทางเอกสารอย่างมีกลยุทธ์ — เหลือช่องว่างอีกราว 20% เมื่อเทียบกับประสิทธิภาพแบบ oracle
OpenFold3 Preview 2 — โมเดลชีววิทยาโอเพนซอร์สที่สมบูรณ์ที่สุดในปัจจุบัน
@MoAlQuraishi ประกาศ OpenFold3 preview 2 โดยระบุว่าปิดช่องว่างกับ AlphaFold3 ได้มากในทุกรูปแบบ พร้อมเปิดเผยไม่เพียงแค่น้ำหนักโมเดล แต่รวมถึง ชุดข้อมูลฝึกและการตั้งค่า ทำให้เป็น "โมเดลที่ใช้ AF3 เป็นฐานเพียงตัวเดียวในปัจจุบันที่สามารถฝึกและสร้างซ้ำได้ตั้งแต่ต้น" — จุดสำคัญคือความสามารถในการสร้างซ้ำ เนื่องจากการเผยแพร่โมเดลชีววิทยาแบบ "เปิด" หลายตัวยังหยุดอยู่ก่อนจะถึงการฝึกซ้ำแบบครบกระบวนการ
WAXAL — ชุดข้อมูลเสียงพูดโอเพนซอร์สสำหรับ 27 ภาษาแอฟริกัน ครอบคลุมผู้พูดกว่า 100 ล้านคน
@osanseviero ประกาศ WAXAL — ชุดข้อมูลเสียงพูดหลายภาษาแบบเปิดที่ครอบคลุม 17 ภาษาแอฟริกันสำหรับ TTS และ 19 ภาษาสำหรับ ASR ต่อมา @GoogleResearch อธิบายว่ามี เสียงมากกว่า 2,400 ชั่วโมง ครอบคลุม 27 ภาษาในแอฟริกาใต้สะฮารา และผู้พูดมากกว่า 100 ล้านคน ทั้งสองฝ่ายระบุว่า WAXAL เป็นทรัพยากรที่หาได้ยากและมีรากฐานจากชุมชนสำหรับ AI ด้านเสียงภาษาแอฟริกัน
กระแสโอเพนซอร์สเข้มข้นขึ้น — John Carmack สนับสนุนให้ใช้โค้ดเปิดฝึก AI
ความคิดเห็นที่แข็งกร้าวที่สุดมาจาก @ID_AA_Carmack (John Carmack) ที่แย้งว่าโค้ดโอเพนซอร์สเป็นของขวัญที่มูลค่าถูกขยายให้ใหญ่ขึ้นด้วยการฝึก AI ไม่ใช่ถูกทำลาย @giffmana และ @perrymetzger เห็นด้วย
มุมมองที่เป็นกลางมากที่สุดมาจาก @wightmanr ที่แย้งว่า agent เขียนโค้ดอาจข้ามการระบุแหล่งที่มาและข้อกำหนดสัญญาอนุญาตในลักษณะที่อาจทำให้ผู้ดูแลโครงการหมดกำลังใจ — และเสนอว่าโปรโตคอลสำหรับการปฏิบัติตามกฎของ agent อาจกลายเป็นสิ่งสำคัญ
ขั้นตอนการทำงานของ agent เขียนโค้ดยิ่งอิสระมากขึ้น — จากผู้ช่วยสู่โรงงานซอฟต์แวร์
มีตัวอย่างมากมายของวิศวกรที่เปลี่ยนจาก "copilot" ไปสู่โรงงานซอฟต์แวร์แบบ multi-agent
- @matvelloso — อธิบายระบบที่มี 5 agent ทำ code review/test/security/perf และอีก 2 agent ทำการรวมโค้ดและตรวจสอบ regression
- @swyx — สรุปแนวโน้มเป็น "โค้ดของคุณคือโครงสร้างพื้นฐานของคุณ"
- FactoryAI — กลายเป็นเลเยอร์ "โรงงานซอฟต์แวร์" ที่พบเห็นบ่อยขึ้นเรื่อย ๆ ตามที่ @gokulr และ @matanSF ชี้ให้เห็น
การวิจัยอัตโนมัติกลายเป็นหมวดหมู่ผลิตภัณฑ์ — แต่ไม่ใช่แนวคิดใหม่
autoresearch ของ Karpathy และแฮกกาธอนที่เกี่ยวข้องได้รับความสนใจอย่างมาก แต่หลายทวีตก็ชี้ว่าแนวคิดนี้ทับซ้อนกับระบบเก่า ๆ เช่น DSPy, GEPA และ pipeline การเพิ่มประสิทธิภาพแบบ Bayesian
คำแนะนำที่เป็นประโยชน์ที่สุดมาจาก @dbreunig ที่แนะนำ optimize_anything สำหรับคนที่สนใจรูปแบบการปรับปรุงตัวเองแบบวนซ้ำ Together AI ก็เปิดตัว Open Deep Research v2 พร้อมเปิดเผยแอป ชุดข้อมูลการประเมิน โค้ด และบล็อก
ทวีตเด่นประจำสัปดาห์ — จัดอันดับตามการมีส่วนร่วม
- xAI ปรับกระบวนการรับสมัคร — Elon Musk กล่าวว่า xAI กำลังทบทวนกระบวนการสัมภาษณ์ในอดีตและติดต่อผู้สมัครที่เคยถูกปฏิเสธแต่มีศักยภาพสูง
- UI แผนภูมิของ Claude — @crystalsssup โพสต์ปฏิกิริยาที่มีผู้มีส่วนร่วมสูงต่อ UX แผนภูมิแบบโต้ตอบใหม่ของ Claude
- Perplexity Computer บนมือถือ — หนึ่งในการนำ agent ทำงานจากระยะไกลไปเป็นผลิตภัณฑ์ที่ชัดเจนที่สุดในสัปดาห์นี้
- Microsoft ตรวจสอบ Rubin NVL72 — Azure เป็นคลาวด์รายแรกที่ตรวจสอบ NVIDIA Vera Rubin NVL72
- Hermes Agent — แนวคิด agent ที่เน้นหน่วยความจำและโฮสต์ได้เอง สร้างการพูดคุยกว้างขวาง
OmniCoder-9B — โมเดลเขียนโค้ด 9 พันล้านพารามิเตอร์ที่ฝึกบนเส้นทาง agent 425,000 เส้นทาง
OmniCoder-9B เป็น agent เขียนโค้ดขนาด 9 พันล้านพารามิเตอร์ที่พัฒนาโดย Tesslate ฝึกบนสถาปัตยกรรม Qwen3.5-9B ที่ใช้ Gated Delta Networks สลับกับ standard attention โมเดลนี้ถูกฝึกบน เส้นทางการเขียนโค้ดแบบ agentic มากกว่า 425,000 เส้นทาง ที่คัดสรรมาอย่างดี รวมถึงข้อมูลจากโมเดลอย่าง Claude Opus 4.6 และ GPT-5.4
- หน้าต่างบริบท — 262,144 โทเค็น ขยายได้ถึง 1 ล้านขึ้นไป
- จุดเด่น — การกู้คืนจากข้อผิดพลาดและการให้เหตุผลที่แข็งแกร่ง ตอบสนองต่อ LSP diagnostics และใช้ minimal edit diffs
- สัญญาอนุญาต — Apache 2.0 พร้อมน้ำหนักเปิดเต็มรูปแบบ
ผู้แสดงความคิดเห็นเน้นว่าสถาปัตยกรรม Qwen3.5-9B น่าประทับใจ สามารถทำงานที่ปกติต้องใช้โมเดลขนาดใหญ่กว่ามาก บางคนเปรียบเทียบว่าทำได้เทียบเท่าโมเดล 100 พันล้านพารามิเตอร์ขึ้นไปในบางงาน
ความท้าทายทางเทคนิคหลักของโมเดลขนาดเล็กอย่าง Qwen 3.5-9B คือแนวโน้มที่จะเขียนทับโค้ดที่มีอยู่โดยไม่ตรวจสอบก่อน — ปัญหานี้เกิดในลูป agentic แต่เมื่อใช้เป็น agent พื้นหลังสำหรับการสำรวจไฟล์และแก้ไขโค้ด ช่องว่างด้านประสิทธิภาพกับโมเดล 70B จะแคบกว่าที่คาด ปัญหาหลักยังอยู่ที่การกู้คืนข้อผิดพลาดหลายขั้นตอน
Qwen3.5-9B ทำงานเขียนโค้ดแบบ agentic ได้ดีอย่างน่าประหลาดใจ — แม้บนฮาร์ดแวร์ระดับผู้บริโภค
มีการอภิปรายเกี่ยวกับประสิทธิภาพของ Qwen 3.5-9B สำหรับงานเขียนโค้ดแบบ agentic บน NVIDIA GeForce RTX 3060 ที่มี VRAM 12 GB ผู้ใช้ทดลองหลายโมเดลรวมถึง Qwen 2.5 Coder แต่พบว่า Qwen 3.5-9B ทำงานได้ดีอย่างน่าแปลกใจ — รักษาการทำงานได้นานกว่าหนึ่งชั่วโมงโดยไม่มีปัญหา
อย่างไรก็ตามมีรายงานผลลัพธ์ที่ไม่สม่ำเสมอ — บางครั้งโมเดลล้มเหลวอย่างรุนแรง เช่น ทำลายระบบ build ซึ่งบ่งบอกถึงความแปรปรวนในประสิทธิภาพ
Bernie Sanders เสนอกฎหมาย ห้าม สร้างศูนย์ข้อมูล AI แห่งใหม่ทั้งหมด
Bernie Sanders เสนอกฎหมายที่มุ่งห้ามการก่อสร้างศูนย์ข้อมูล AI แห่งใหม่ โดยอ้างว่าเป็นภัยคุกคามต่อการดำรงอยู่ของมนุษยชาติ ข้อเสนอนี้ได้รับความสนใจอย่างมากบน Reddit (4,564 activity) ผู้แสดงความคิดเห็นเสนอว่าการห้ามศูนย์ข้อมูลในสหรัฐฯ อาจไม่ได้ป้องกันการสร้างในระดับโลก เนื่องจากประเทศอย่างจีนอาจพัฒนาต่อไป คนอื่น ๆ เสนอการกำกับดูแลแทนการห้าม — ศูนย์ข้อมูลควรมีระบบไฟฟ้าอิสระและไม่สร้างปัญหาสิ่งแวดล้อมในท้องถิ่น
Sam Altman มองอนาคต "ปัญญาประดิษฐ์เป็นสาธารณูปโภค" — แต่ถูกตั้งคำถามเรื่องโมเดลธุรกิจ
Sam Altman กล่าวว่าเขามองเห็นอนาคตที่ปัญญาประดิษฐ์เป็นสาธารณูปโภคเหมือนไฟฟ้าหรือน้ำ — และผู้คนจะซื้อมันจาก OpenAI ตามมิเตอร์ (9,032 activity)
ผู้แสดงความคิดเห็นชี้ข้อบกพร่องของการเปรียบเทียบนี้ — ไฟฟ้าเป็นบริการที่กลายเป็นสินค้าโภคภัณฑ์ มักถูกกำกับดูแลด้วยราคาที่มีเพดาน หาก AI ต้องเดินตามเส้นทางเดียวกัน OpenAI อาจกลายเป็นสาธารณูปโภคที่ถูกกำกับดูแลด้วยอัตรากำไรจำกัด — ซึ่งขัดแย้งกับมูลค่าสูงและความคาดหวังของนักลงทุน มีผู้เสนอว่าเจตนาที่แท้จริงของ Altman อาจเป็นการวางตำแหน่ง OpenAI เหมือนบริษัทน้ำมันมากกว่า — กำกับดูแลน้อยกว่าและกำไรสูงกว่า
Gemini เปิดตัวระบบอัตโนมัติที่ตัดสินใจแทนผู้ใช้ได้อย่างชาญฉลาด
Gemini เปิดตัวระบบจัดการงานอัตโนมัติที่มีความสามารถในการจัดการงานที่ซับซ้อน เช่น การสั่ง Uber หรือเลือกรายการจากเมนู ระบบแสดงการตัดสินใจขั้นสูงโดยถามคำถามเพื่อขอความชัดเจนและเลือกตามบริบท — เช่น ข้ามขั้นตอนที่ไม่จำเป็นหรือระบุความต้องการที่ถูกต้องอย่างการอุ่นเพสตรี้
มีการถกเถียงเกี่ยวกับแนวต้านที่อาจเกิดจากธุรกิจอย่างสายการบิน ต่อระบบอัตโนมัติเหล่านี้เนื่องจากความกังวลเรื่องความโปร่งใสด้านราคา
คุณภาพ Nano Banana Pro ถดถอยหลัง 10 มีนาคม — ผู้ใช้กล่าวหาว่าเป็นกลยุทธ์ล่อและเปลี่ยน
ผู้ใช้รายงานว่าเครื่องมือสร้างภาพ Nano Banana Pro ส่วนหนึ่งของระบบนิเวศ Gemini มีคุณภาพถดถอยอย่างเห็นได้ชัดหลังวันที่ 10 มีนาคม เครื่องมือที่เคยสร้างภาพคมชัดระดับ 2K กลับสร้างภาพที่แตกเป็นพิกเซลและเบลอ (1,069 activity)
ผู้แสดงความคิดเห็นเสนอว่าเป็นส่วนหนึ่งของรูปแบบธุรกิจที่กว้างขึ้น — บริการ AI เสนอผลลัพธ์คุณภาพสูงในตอนแรกเพื่อดึงดูดผู้ใช้และสื่อ จากนั้นลดคุณภาพลงเพื่อลดต้นทุน มีคำแนะนำให้สำรวจตัวเลือกโมเดลในเครื่องเช่น Flux 2 Klein 9B ที่ใช้งานได้ไม่จำกัดหากฮาร์ดแวร์รองรับ
Gemini UI/UX 2.0 — การอัปเกรดใหม่พร้อมข้อถกเถียงเรื่องราคา Ultra $250 ต่อเดือน
UI/UX ใหม่ของ Gemini 2.0 เปิดตัวพร้อมเน้นการอัปเกรดเป็น Google AI Ultra ผู้ใช้ถกเถียงเกี่ยวกับความคุ้มค่าของสมาชิก Ultra ที่ราคา $250 ต่อเดือน
- @IfNightThen — อธิบายว่าการลดระดับจาก Ultra เป็น Pro ประหยัดได้ $220 ต่อเดือน สิ่งที่เสียไปมีเพียง Deep Think และ agents mode ซึ่งกำลังกลายเป็นฟีเจอร์มาตรฐานที่อื่น
- Deep Think — ถูกเปรียบเทียบว่าด้อยกว่า ChatGPT Pro และ Claude Opus 4.6 โดยมักต้องลองหลายครั้งกว่าจะทำงานได้อย่างมีประสิทธิภาพ
- ข้อกังวลด้านราคา — แม้จ่ายค่า Pro แล้ว ผู้ใช้ยังถูกกระตุ้นให้อัปเกรดเป็น Ultra $250 เพื่อเข้าถึง Gemini พร้อมอาจมีขีดจำกัดอัตราการใช้งาน
CEO Palantir อ้างว่า AI จะลดอำนาจของผู้มีการศึกษาสูงที่โหวตให้พรรค Democrat
CEO ของ Palantir Alex Karp กล่าวอ้างอย่างขัดแย้งว่าเทคโนโลยี AI จะลดอิทธิพลของผู้มีสิทธิเลือกตั้งที่ "มีการศึกษาสูง มักเป็นเพศหญิง ที่โหวตให้พรรค Democrat เป็นส่วนใหญ่" ขณะที่เพิ่มอำนาจให้กับผู้ชายชนชั้นแรงงานที่ผ่านการฝึกอาชีพ (2,076 activity)
ข้อกล่าวอ้างนี้จุดชนวนความกังวลเกี่ยวกับการมองว่า AI เป็นเครื่องมือสำหรับการบิดเบือนทางการเมือง ผู้แสดงความคิดเห็นชี้ให้เห็นความย้อนแย้งที่ Karp เองก็มีพื้นฐานด้านมนุษยศาสตร์ และเสนอว่า AI อาจแทนที่งานทางปัญญาก่อนแรงงานทางกาย — ซึ่งทำให้เห็นความจำเป็นของนโยบายอย่าง Universal Basic Income
AI Discord ถูกปิดการเข้าถึง — AINews จะไม่กลับมาในรูปแบบนี้
AINews ประกาศว่า Discord ได้ปิดการเข้าถึงของพวกเขาในวันนี้ และจะไม่นำกลับมาในรูปแบบเดิม แต่จะเปิดตัว AINews เวอร์ชันใหม่เร็ว ๆ นี้