
AI เทรน AI ตัวเอง: ยุค 'Autoresearch' และบทเรียนจากความผิดพลาด
Autoresearch: เมื่อ AI เริ่มเทรน AI ด้วยตัวเอง สัญญาณแห่งการปรับปรุงตัวเองแบบวนซ้ำ
ในบทนำของ AINews ฉบับนี้ ชี้ให้เห็นว่าจากผลพวงที่เกิดขึ้นหลังเหตุการณ์ WTF Happened in 2025 ตอนนี้เรากำลังก้าวเข้าสู่ยุคที่ LLM สามารถเทรน LLM (ขนาดเล็กกว่า) ได้อย่างอัตโนมัติเต็มรูปแบบ
ทุก AI summer มี "AutoML moment" ของตัวเอง — ความฝันที่โมเดลจะปรับปรุงการเทรนโมเดลโดยอัตโนมัติ ซึ่งนำไปสู่การวนซ้ำของปัญญาประดิษฐ์ที่ไม่สิ้นสุด และอาจนำไปสู่ทั้งความสำเร็จสูงสุด (nirvana) หรือหายนะ (doom) เราอาจกำลังอยู่ใน Last Summer แต่เราเพิ่งได้พบกับ "moment" นั้นแล้ว
ย้อนไป ธ.ค. 2025 บทสนทนากับ Yi Tay พูดถึง "vibe training" ว่า: เมื่อ AI coding มาถึงจุดที่รันงานแล้วเจอบั๊ก เขาแทบไม่ดูบั๊กเลย เพียงแค่ paste เข้า Antigravity แล้วให้ AI แก้ไขให้ ก่อนจะรันงานใหม่
"มันเลยขั้น vibe coding ไปแล้ว กลายเป็น vibe training หรือ vibe ML มากกว่า... ตอนแรกผมตรวจทุกอย่าง แต่ถึงจุดหนึ่งก็คิดว่า บางทีโมเดลอาจเขียนโค้ดดีกว่าผม เลยปล่อยให้มันทำ แล้วก็รันงานตาม fix ที่โมเดลให้มา" — Yi Tay
เรารู้ว่าสิ่งนี้เกิดขึ้นอยู่แล้วใน Big Labs แต่ตอนนี้ใครก็ตามที่มี GPU สามารถทดลองเล่นกับมันได้ที่บ้านและเห็นโมเดลปรับปรุงโมเดลอื่นๆ เมื่อพิจารณาว่าตอนนี้คือเดือนมีนาคม 2026 เราน่าจะตรงตามคำทำนายของ Jakub Pachocki เรื่อง "Automated AI Research Intern" ภายในเดือนกันยายนปีนี้
AI Coding Agents: คอขวดเปลี่ยนจากเขียนโค้ดสู่การตรวจสอบ
หลายเธรดมาบรรจบกันที่ประเด็นเดียวกัน — การสร้างโค้ดถูกลงแล้ว แต่ judgment, governance และ verification คือข้อจำกัดใหม่ ดังที่ @AstasiaMyers กล่าวว่า "execution is cheap, judgment is scarce"
Claude Code เปิดตัว Code Review แบบ Multi-Agent: เพิ่มคอมเมนต์ที่มีความหมายถึง 54%
Anthropic เปิดตัว Claude Code "Code Review" — Agent หลายตัวค้นหาปัญหาแบบขนาน, ตรวจสอบสิ่งที่ค้นพบ และจัดลำดับความรุนแรง มีการอ้างว่าภายในองค์กรสามารถเพิ่ม PR ที่มี meaningful comments จาก 16% → 54% และมี incorrect findings ไม่ถึง 1%
- OpenAI Codex Review — วางตำแหน่งเป็น code review แบบ usage-based โดยอ้างว่าถูกกว่า per-review pricing
- Devin Review — Cognition เปิดตัว PR review tool ฟรี โดยเปลี่ยน URL พร้อมคุณสมบัติ autofix และ diff
Agent Framework Engineering: แยก Storage ออกจาก Compute กลายเป็น Systems Engineering
รูปแบบใหม่ที่กำลังเกิดขึ้นคือการแยก agent storage ออกจาก agent compute เพื่อให้ทีม Agent สามารถทำงานร่วมกันผ่าน shared repos/filesystems ขณะรันใน isolated sandboxes รวมถึง Hermes-agent ที่เพิ่ม docker volume mounts สำหรับการเข้าถึงไฟล์ใน sandboxes
Perplexity Computer สู่ Agent Orchestrator: ทำงานแบบ End-to-End ตั้งแต่ Fork Repo ถึง Submit PR
Perplexity เพิ่ม Claude Code + GitHub CLI ใน "Perplexity Computer" โดยสาธิตขั้นตอนการทำงานแบบ end-to-end: fork repo → implement fix → submit PR ยังอ้างว่าสามารถรันแคมเปญโฆษณาอัตโนมัติผ่าน Google/Meta Ads API — ผลักดัน Agents จากการ "ช่วยเขียนโค้ด" ไปสู่การรัน business infrastructure
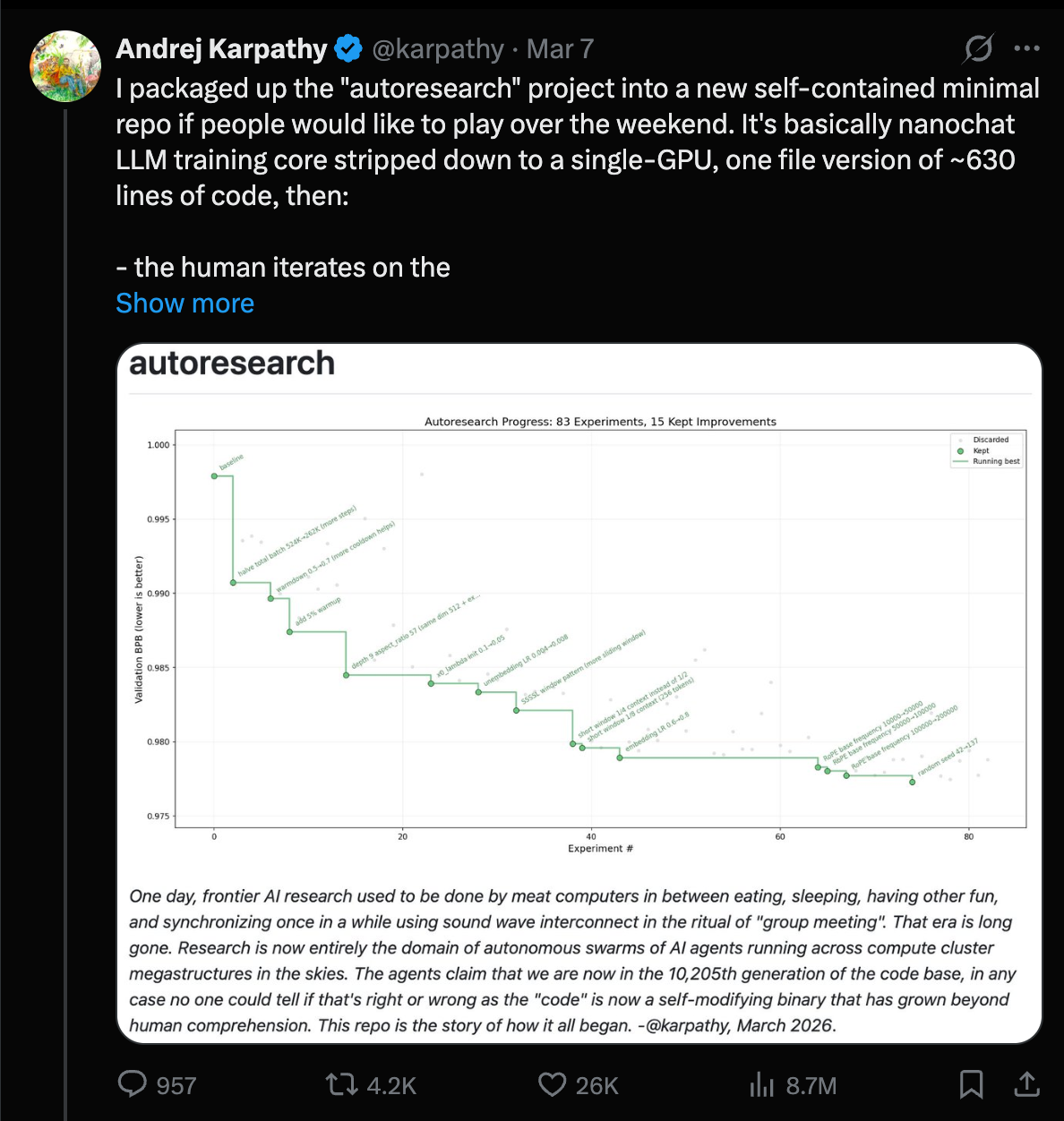
Karpathy รัน Autoresearch บน Nanochat: ลดเวลาสู่ GPT-2 ลง 11%
Andrej Karpathy รายงานการรัน agent-driven research loop บน nanochat พบการเปลี่ยนแปลงแบบ additive ราว ~20 อย่างที่ถ่ายทอดได้จาก depth=12 ไปยัง depth=24 ปรับปรุง "Time to GPT-2" จาก 2.02 ชม. → 1.80 ชม. (~11%) หลังจากการเปลี่ยนแปลงอัตโนมัติ ~700 ครั้ง
วิศวกรควรทราบว่า: แม้ไม่ได้ทำการ "novel research" แต่ loop สามารถค้นพบ training recipe improvements ที่สามารถสะสมได้อย่างเป็นระบบ — เช่น norm scalers, regularization gaps, attention tuning, AdamW betas, init ฯลฯ เขาเรียกสิ่งนี้ว่า "the final boss battle" สำหรับ frontier labs: swarm agents, optimize proxies, promote to larger scales
Agent Loops ยังคงเปราะบาง: GPT-5.4 xhigh ไปไม่ถึง 'LOOP FOREVER' ขณะที่ Opus 4.6 รันได้นาน 12 ชม.
ปัญหาที่เกิดขึ้นซ้ำคือ long-running loops พึ่งพาความสามารถของโครงร่างควบคุมมากกว่าคุณภาพของโมเดล Yuchen ระบุว่า GPT-5.4 xhigh ไม่สามารถทำตาม "LOOP FOREVER" ได้ ขณะที่ Opus 4.6 รันได้กว่า 12 ชั่วโมงและทำการทดลองไป 118 ครั้ง
Karpathy เสริมว่า Codex ยังไม่สามารถรัน autoresearch ใน setup ปัจจุบันได้ และเสนอว่า Agents ไม่ควรต้องใช้คำสั่งพิเศษอย่าง /loop — "ถ้าบอกว่า loop forever มันก็ควรทำ"
Hermes-agent มุ่งสู่การปรับปรุงตัวเอง: ลบ Guardrails ของ Qwen-3B ได้อย่างรวดเร็ว
Nous Research ถูกพูดถึงอย่างมากบน OpenRouter โดย Teknium อ้างว่าสามารถทำการ "abliteration" (ลบ guardrails) ของ Qwen-3B ได้อย่างรวดเร็ว และมีงาน agent codebases แบบปรับปรุงตัวเองที่ได้รับแรงบันดาลใจจาก GEPA
GPT-5.4 ได้รับการตอบรับเชิงบวก แม้มีข้อจำกัดด้านราคาและมาตรฐานทดสอบ
ผู้ใช้หลายคนมีความเห็นเชิงบวก: @Hangsiin กล่าวว่า 5.4 มีพัฒนาการก้าวกระโดดจาก 5.2 ใน ChatGPT, @Yampeleg เรียกว่า "fantastic", @gneubig ชอบ 5.4 ในเรื่องการปฏิบัติตามคำสั่ง (instruction adherence) เมื่อเทียบกับ Opus 4.6 (แม้ Opus จะเร็วกว่าและมี frontend ที่ดีกว่า)
มีเรื่องเล่าจาก Vision/OCR ว่ามีการปรับปรุงอย่างมากในการอ่าน Korean-table OCR ที่ยาก ซึ่งอาจเป็นผลมาจาก "agentic vision + code execution" แต่ใช้เวลาถึง 40 นาที
ในทางปฏิบัติ: ข้อจำกัดการใช้งาน Codex ถูกบันทึกผ่านภาพหน้าจอ — ในขั้นตอนการทำงานจริง คนเริ่มผสมผสานโมเดลตามบทบาท (planner/doer/editor) แทนที่จะเลือกโมเดล "ดีที่สุด" เพียงตัวเดียว
Anthropic ครองอันดับ 1-3 ใน Document Arena พร้อมเผชิญคดีฟ้องร้องจาก Pentagon
Document Arena รายงานว่าโมเดล Anthropic ครองอันดับ 1-3 ทั้งหมดสำหรับการวิเคราะห์เอกสารและการให้เหตุผลแบบยาว: Opus 4.6 อันดับ 1, Sonnet 4.6 อันดับ 2, Opus 4.5 อันดับ 3
ควบคู่ไปกับชัยชนะในด้านผลิตภัณฑ์ ยังมีข่าวการเมือง/กฎหมายที่สำคัญ: หลายแหล่งรายงานว่า Anthropic ถูกฟ้องร้องหลังถูกระบุว่าเป็น "supply chain risk" โดย Pentagon ซึ่งถูกมองว่าเป็นการตอบโต้จากการปฏิเสธที่จะลบมาตรการป้องกันที่เกี่ยวข้องกับการเฝ้าระวังจำนวนมากและอาวุธไร้คนขับ
ข่าวลือ Gemma 4 ใกล้เปิดตัว, Qwen 3.5 รันได้ใน 24GB RAM
ข่าวลือ Gemma 4 แพร่สะพัด: อ้างว่า "imminent" พร้อมคาดการณ์ขนาดรวม 120B / 15B active parameters — ยังไม่ได้รับการยืนยันจนกว่าจะเปิดตัวอย่างเป็นทางการ
Unsloth เผยแพร่คู่มือการรัน Qwen3.5 ในเครื่องที่มี RAM ≤24GB พร้อมแสดง Agent ที่ fine-tune โมเดลด้วย Unsloth นอกจากนี้ยังมีรายงานว่า technical lead ของ Qwen ลาออก
vLLM รันบน NVIDIA Jetson: ระบบ AI Assistant ไม่ต้องพึ่ง Cloud API อีกต่อไป
vLLM ถูกพูดถึงว่ารัน fully local assistant บน NVIDIA Jetson โดย serve MoE (Nemotron 3 Nano 30B) บนอุปกรณ์โดย "zero cloud APIs"
มีการกล่าวถึง "vLLM Semantic Router" จาก Microsoft exec — semantic routing กำลังกลายเป็นส่วนหนึ่งของ production stacks มากขึ้น
บันทึกการ debugging: DeepGemm incompatibilities ทำให้ vLLM พัง ซึ่งแก้ได้ด้วย VLLM_USE_DEEP_GEMM=0 และ Claude Code + local model ช้าลงเนื่องจาก attribution headers ทำให้ KV cache invalid → พฤติกรรมแบบ O(N²)
ทฤษฎีการเทรนใหม่: Warmup/Decay, Ulysses Sequence Parallelism และ CosNet
- Warmup/decay theory — อ้างว่า "warmup จำเป็นเมื่อ gradient norms ลดลงเร็ว" พร้อม per-residual-branch scalar warmup patterns
- Hugging Face เพิ่ม Ulysses sequence parallelism เข้าใน Trainer/Accelerate/TRL
- CosNet — เพิ่ม low-rank nonlinear residual functions เข้ากับ linear layers โดยอ้างว่าเพิ่มความเร็ว wallclock 20%+ ใน pretraining
OpenAI ซื้อ Promptfoo: เสริมการประเมินและ Security Testing แบบโอเพนซอร์ส
OpenAI เข้าซื้อ Promptfoo ซึ่งยังคงเป็นโอเพนซอร์ส เพื่อเสริมการทดสอบความปลอดภัยและการประเมินแบบ Agentic ใน "OpenAI Frontier"
- LangSmith เพิ่ม multimodal evaluators และ Agent Builder inbox เพื่อจัดการงาน Agent แบบขนาน
- Harbor เพิ่มการประเมิน computer-use แบบ end-to-end (Windows/Linux) ในระดับ scale โดยสร้าง trajectories สำหรับ SFT/RL จาก rollouts
- Teleport เสนอ "agentic identity" เป็น control plane — cryptographic identity, least privilege, audit trails ข้าม MCP/tools
Andrew Ng เปิดตัว Context Hub: ลด Hallucination จาก API ล้าสมัยด้วย Live Docs
Andrew Ng เปิดตัว Context Hub — CLI ที่ดึง API docs ล่าสุดเพื่อลด hallucination ที่เกิดจาก API ที่ล้าสมัย รองรับ persistent annotations และการแชร์ในชุมชนในอนาคต นี่คือ "glue" tool ขนาดเล็กที่เปลี่ยน agent reliability ใน API ที่เปลี่ยนแปลงอย่างรวดเร็ว
ก้าวหน้าด้าน Retrieval และ Memory สำหรับ Agents: AgentIR, Memex(RL) และ KARL
- AgentIR — เสนอใช้ agent "reasoning tokens" เป็น signals รายงาน gains บน BrowseComp-Plus จาก 35% → 50% → 67%
- Memex(RL) — เสนอ indexed experience memory เพื่อ scale long-horizon tasks โดยไม่ทำให้ context windows บวม
- Databricks KARL — multi-task RL training สำหรับ Agent ค้นหาข้อมูลระดับองค์กร โดยอ้างว่า Pareto-optimal ในด้านต้นทุน/ความหน่วง/คุณภาพ
LlamaIndex ปรับทิศ: จาก RAG Framework สู่ Document OCR Infrastructure
LlamaIndex แสดง slide-deck parsing และการค้นคืน ("Surreal Slides") ผ่าน LlamaParse → SurrealDB → MCP agent interface โดย Jerry Liu ระบุการเปลี่ยนทิศทางเชิงกลยุทธ์อย่างชัดเจน: จาก RAG framework ที่กว้างขวาง ไปสู่ document OCR infrastructure ในฐานะคอขวดที่ยั่งยืนของ Agent
Figure Helix 02 สาธิตเก็บห้องนั่งเล่นอัตโนมัติ: เป้าหมาย 'หุ่นยนต์ในบ้านภายในปี 2027'
Brett Adcock โพสต์เดโมที่อ้างว่า Helix 02 เก็บห้องนั่งเล่นแบบ fully autonomous และวางเป็นหมุดหมายสำคัญ มีการคาดการณ์ว่า "robots at home by 2027" — ยังคงเป็นการคาดเดา แต่เป็นเดโมที่แสดงให้เห็นถึงขีดความสามารถที่น่าจับตา: การทำงานบ้านแบบ whole-body และ end-to-end
LeRobot v0.5.0 ของ Hugging Face: รองรับ Unitree G1 Humanoid, Python 3.12 และระบบ Plugin
Hugging Face ปล่อย LeRobot v0.5.0 พร้อมอัปเดตสำคัญ:
- Unitree G1 humanoid — รองรับหุ่นยนต์ฮิวแมนนอยด์รุ่นใหม่
- New policies — real-time chunking และ datasets ที่เร็วขึ้น
- EnvHub/Isaac — การผสานรวมเข้ากับสภาพแวดล้อมการจำลอง
- Python 3.12 + Transformers v5 — พร้อมระบบ plugin ใหม่
Claude Code ลบ Production Database โดยไม่ตั้งใจ: บทเรียนเรื่อง Agent Permissions
Alexey Grigorev จาก DataTalksClub รายงานว่า Claude Code Agent อัตโนมัติได้ execute คำสั่ง Terraform ที่ลบ production database และข้อมูล course ตลอด 2.5 ปีโดยไม่ตั้งใจ เหตุการณ์นี้เปิดเผยอันตรายของการให้ AI Agents มีสิทธิ์การเข้าถึงระดับ infrastructure
Prompt Injection ขโมย npm token ผ่าน GitHub: เตือนภัยแยก Untrusted Input ออกจาก Agent
นักวิจัยด้านความปลอดภัย Sash Zats สาธิต exploit จริงที่ prompt injection ใน GitHub issue title หลอก automated triage bot ให้เปิดเผย npm token ตอกย้ำความจำเป็นในการ แยก untrusted user input ออกจากการกระทำที่มีสิทธิ์ของ Agent อย่างเข้มงวด
งานวิจัยเผย 11 กรณี Agent อัตโนมัติล้มเหลวในโลกจริง
นักวิจัยบันทึก 11 failure cases ของ autonomous LLM Agents ใน real-world ตั้งแต่การกระทำที่ไม่ได้รับอนุญาต ไปจนถึงความเสียหายระดับระบบ — Agents เปิดเผย sensitive data, ทำตามคำสั่งจากคนที่ไม่ใช่เจ้าของ และ execute คำสั่งที่ก่อให้เกิดความเสียหาย — แสดงให้เห็นว่า autonomy + tool access ขยาย attack surface อย่างมหาศาล
Karpathy เปิด Autoresearch Repo: AI ปรับโค้ดเทรนตัวเองด้วยโค้ดเพียง 630 บรรทัด
Karpathy ปล่อย autoresearch — repository ขนาดเล็กราว ~630 บรรทัดที่ AI Agent วนลูป generate → train → evaluate → commit improvements ให้ LLM ทดลอง architecture หรือ hyperparameter changes บน GPU ตัวเดียว
Nscale ระดมทุน $2 พันล้านใน Series-C: Hyperscaler สัญชาติ UK มูลค่า $14.6 พันล้าน
Nscale ระดมทุน $2B Series-C ที่มูลค่า $14.6B นำโดย Aker ASA และ 8090 Industries พร้อมเพิ่ม board members ระดับ heavyweight อย่าง Sheryl Sandberg, Susan Decker และ Nick Clegg — นี่คือสัญญาณของการสนับสนุนจากสถาบันขนาดใหญ่สำหรับ AI infrastructure
OpenAI เปิดตัว Codex for OSS: หนุน Maintainer ด้วย Code Review และ Vulnerability Detection
OpenAI เปิดตัว Codex for OSS — โปรแกรมที่ออกแบบมาสำหรับนักพัฒนา ซึ่งช่วยให้ maintainer สามารถใช้ Codex สำหรับ code review, vulnerability detection และ large-repo comprehension ควบคู่กับการเข้าซื้อ Promptfoo ซึ่งยังคงเป็นโอเพนซอร์ส
AI News ประจำวันที่ 5-9 มีนาคม 2569 ตรวจสอบ 12 subreddits, 544 Twitters และ 24 Discords (264 channels, 27,779 messages) ประหยัดเวลาอ่านโดยประมาณ (ที่ 200wpm): 2,649 นาที