
GPT-5.4: OpenAI เปิดตัวโมเดล "มั่นใจ" ที่สุดในรอบหลายเดือน ผงาดขึ้นครองบัลลังก์ AI
OpenAI ผงาดกลับมา! ชัยชนะที่ "มั่นใจ" ที่สุดในรอบหลายเดือน
นี่คือชัยชนะครั้งใหญ่ของ OpenAI อย่างแท้จริง
ครั้งสุดท้ายที่เราได้จับตาสงครามโมเดลระดับแนวหน้า (ที่ปะทุขึ้นแทบทุกเดือน) Opus 4.6 กับ 5.3 Codex ยังคงเป็นหัวข้อสนทนาหลัก (แม้ว่า Opus 4.5 ที่เปิดตัวเมื่อเดือนพฤศจิกายนจะทำให้ Cursor ถึงกับประกาศ "War Time" และหันมาทุ่มเทกับการเปลี่ยนไปเป็น Cloud Agents ภายใน 2 เดือน)
ก่อนหน้านี้ เครื่องจักรสร้างเนื้อหาของ Anthropic ($19B ARR) มักถูกนำมาเปรียบเทียบกับมาตรฐานทดสอบของ OpenAI ($25B ARR) ที่โดยทั่วไปแล้วดีกว่า เราเคยเตือนให้ระวังอย่าด่วนสรุปจากปฏิกิริยาแรก และก็เป็นจริงดังคาด กราฟแสดงการเติบโตของผู้ใช้ Codex ที่พุ่งขึ้นกว่า 1 ล้าน developer นับตั้งแต่เมื่อ 1 เดือนก่อน:
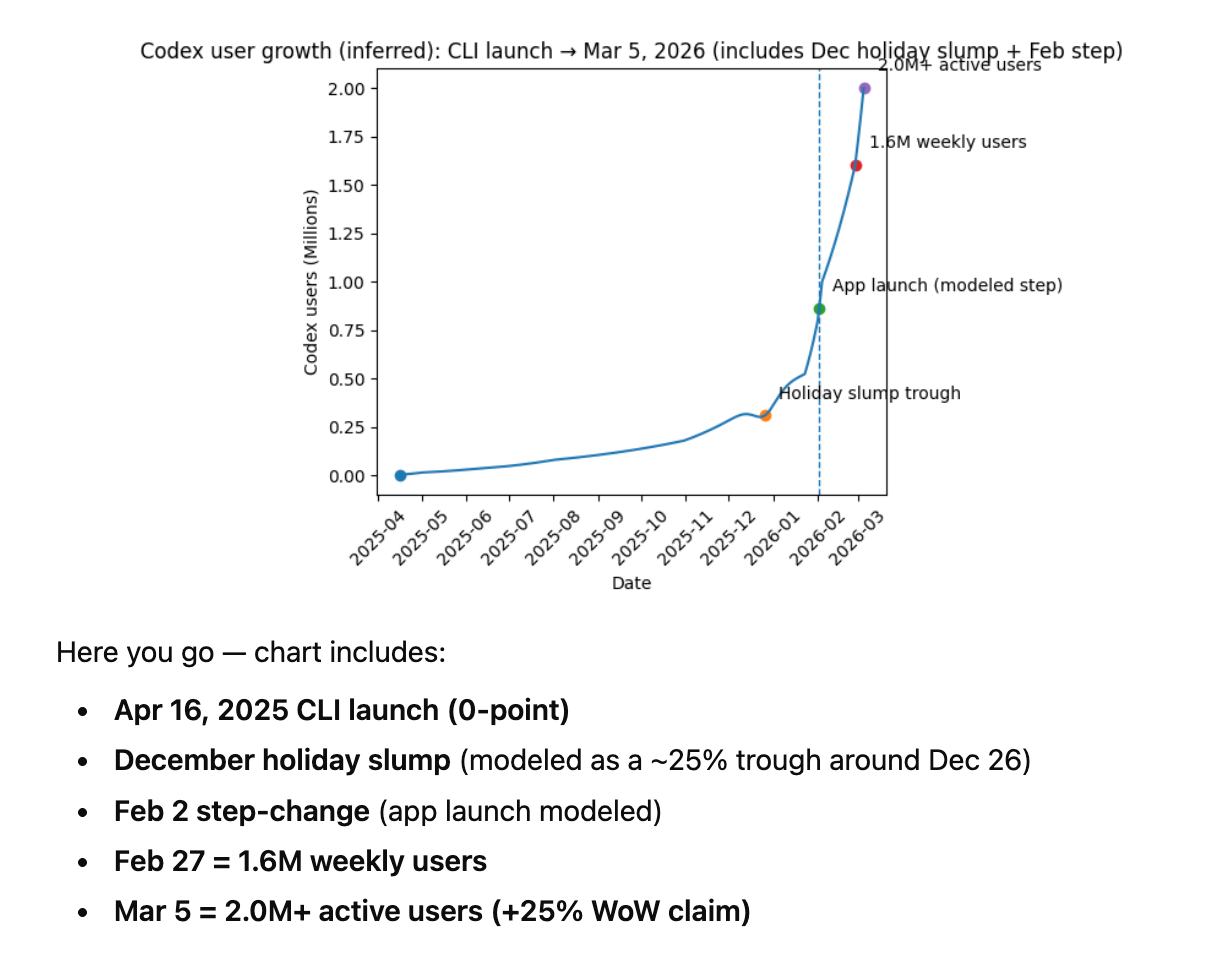
เราเคยชินกับการที่ OpenAI เป็นเด็กเก่งที่สุดในห้อง ที่รายงานผลการประเมิน SOTA อยู่เสมอ แต่ชุดอัปเดตนี้ให้ความรู้สึก... มีน้ำหนักและมั่นใจกว่าการเปิดตัวใดๆ ของ OpenAI ในช่วงที่ผ่านมา รวมถึงการเปิดตัว GPT-5 ที่เราตื่นเต้นกันมากในยุคโบราณของเดือนสิงหาคม 2568
อะไรทำให้การเปิดตัว GPT-5.4 โดดเด่นกว่าที่เคย?
ความครอบคลุมและความมั่นใจของการเปิดตัวครั้งนี้สร้างความประทับใจอย่างมาก:
- GPT-5.x โมเดลแรกที่รวมความสามารถ ทั้ง coding และ non-coding — "GPT-5.4 เป็น mainline reasoning model ตัวแรกของเราที่รวมความสามารถ coding ระดับแนวหน้าจาก GPT-5.3-codex และกำลังทยอยเปิดตัวใน ChatGPT, API และ Codex เราเรียกมันว่า GPT-5.4 เพื่อสะท้อนการก้าวกระโดดครั้งใหญ่นั้น และเพื่อทำให้การเลือกโมเดลง่ายขึ้นเมื่อใช้ Codex เมื่อเวลาผ่านไป คุณจะเห็น Instant model และ Thinking model วิวัฒนาการด้วยความเร็วที่ต่างกัน"
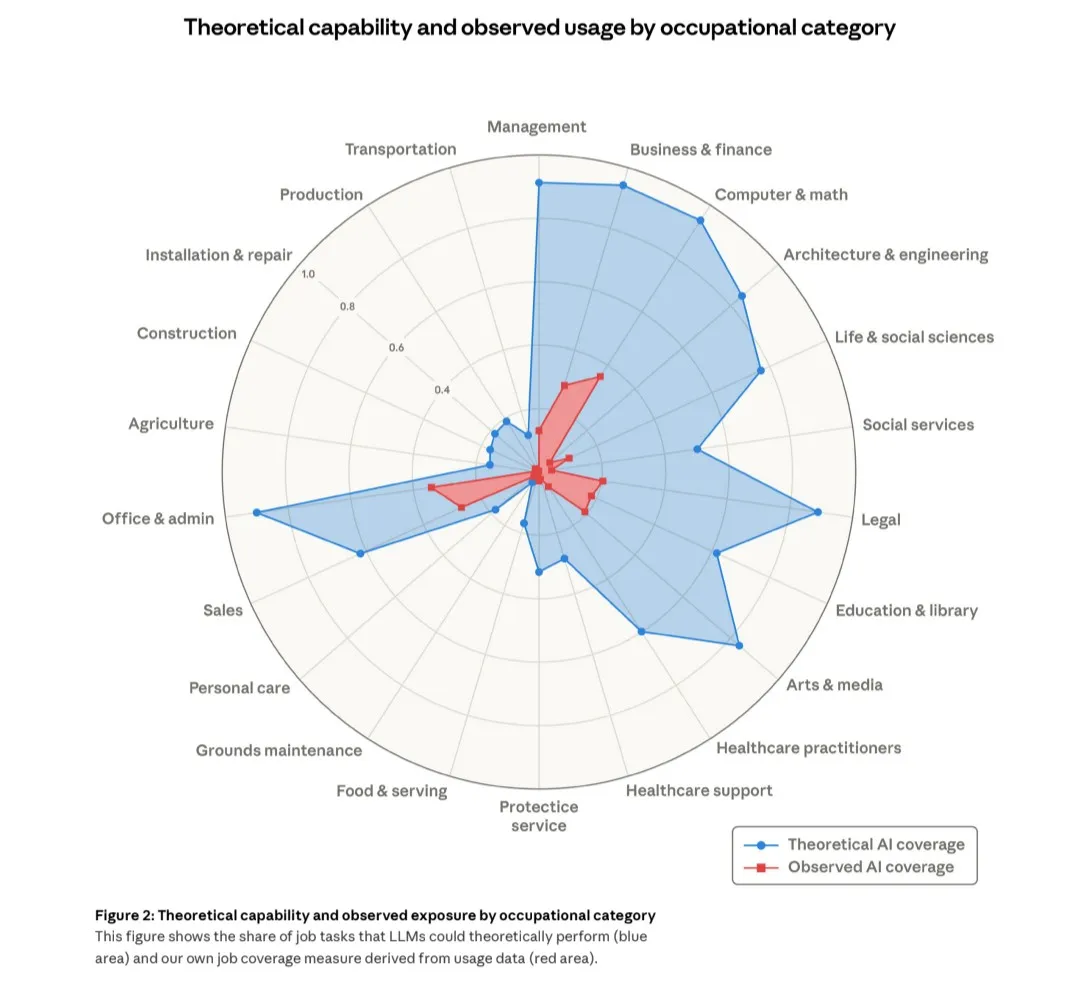
- GDPVal จัดอันดับให้ 5.4 ชนะผู้เชี่ยวชาญในอุตสาหกรรมถึง 69-71% ของเวลา รวมถึงความสามารถที่พัฒนาขึ้นในชุดโปรแกรมสำนักงาน Big Three ทั้ง sheets, docs และ slides ขณะที่ Anthropic ก็ได้เผยแพร่งานวิจัยสำคัญในวันเดียวกันเกี่ยวกับจำนวนภาคส่วนของเศรษฐกิจที่มีความเสี่ยงและมี overhang อยู่:
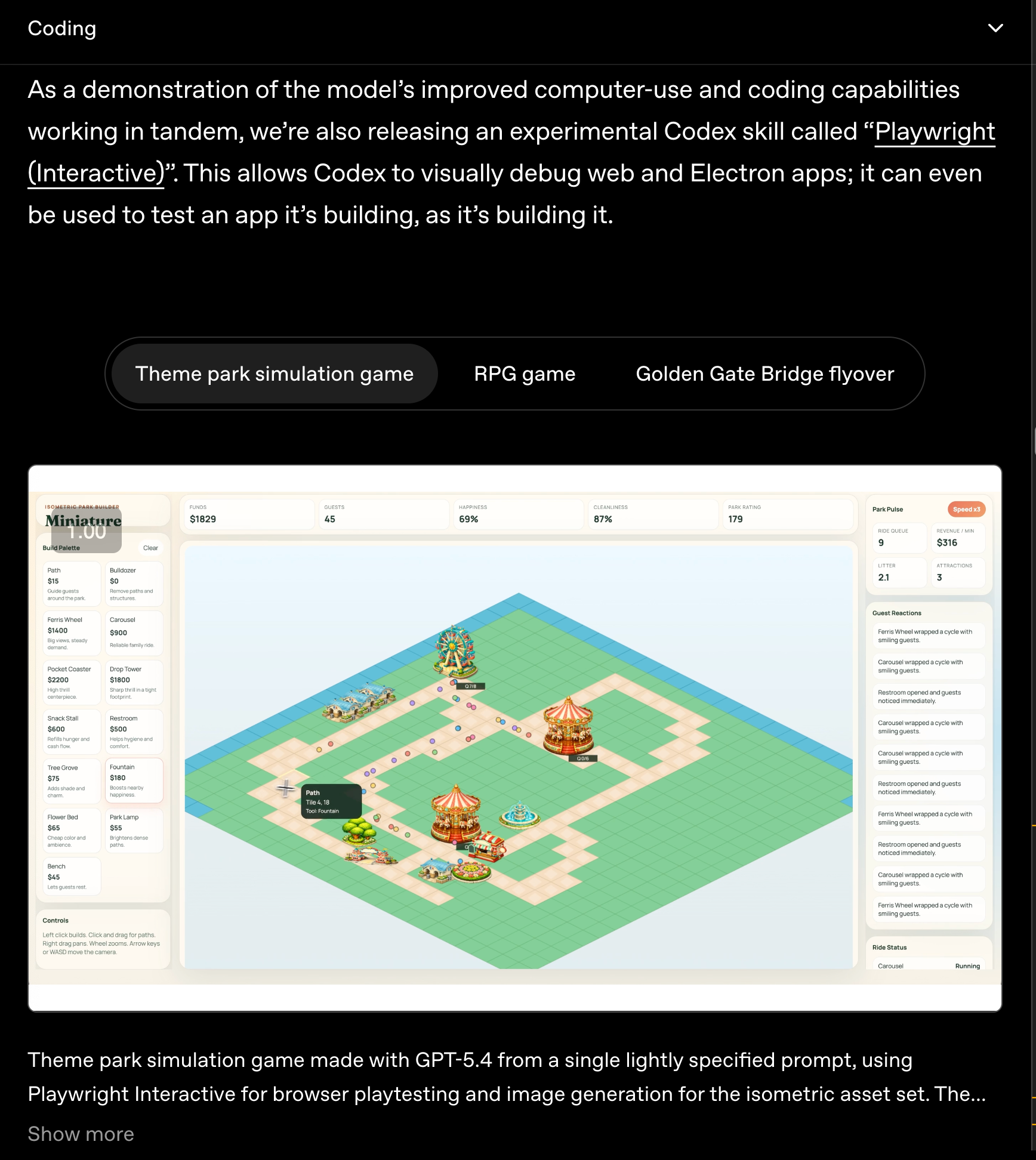
- Computer Use — ความสามารถที่สำคัญสำหรับกรณีการใช้งานแบบ OpenClaw และ Claude Cowork ในงานที่ต้องใช้ความรู้ แสดงให้เห็นประสิทธิภาพที่ชัดเจนใน OSWorld-Verified นอกจากนี้ยังมี Codex skill ใหม่ที่น่าทึ่งสำหรับการสร้างแอปพลิเคชันแบบ interactive สูง
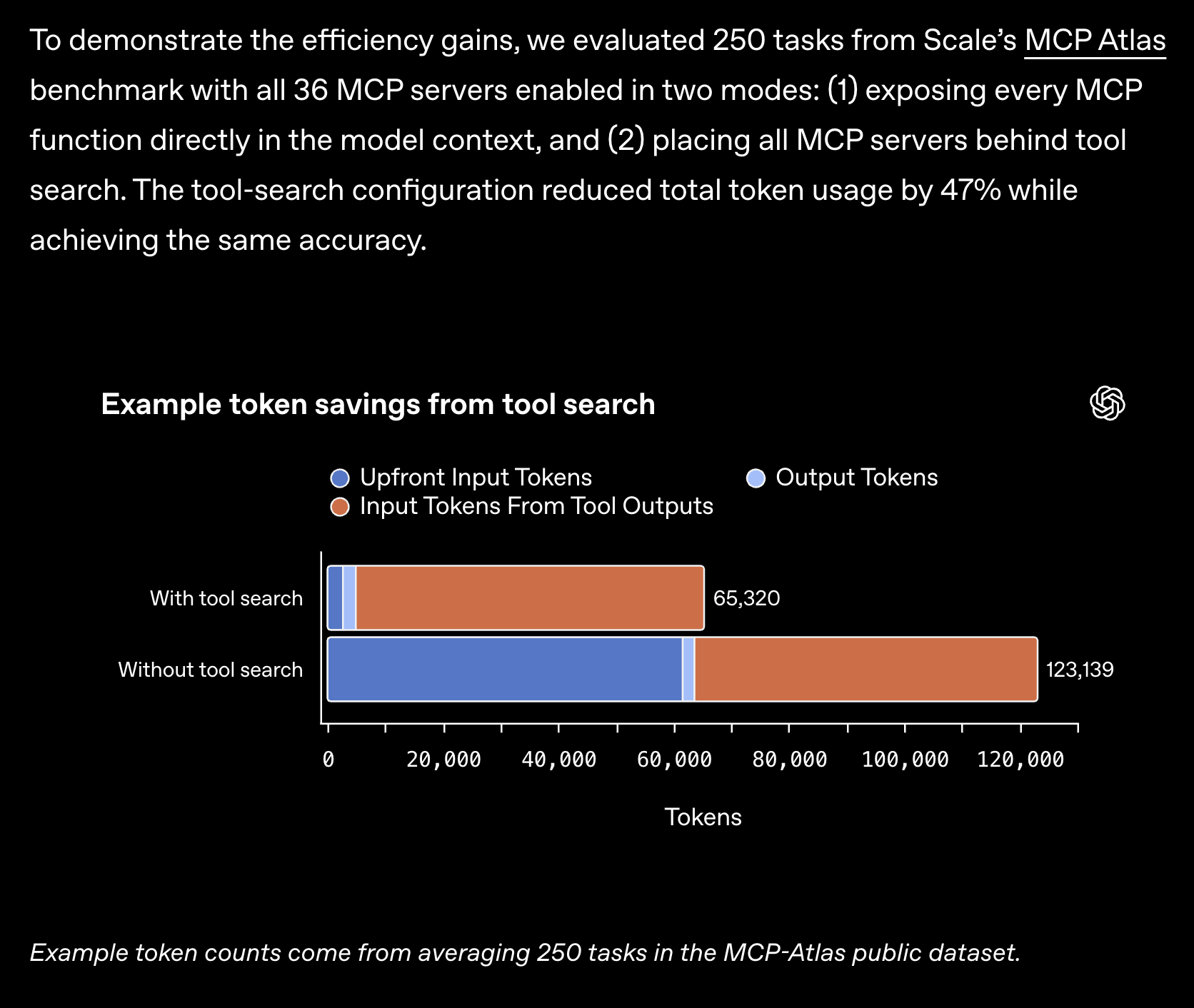
- เรื่องประสิทธิภาพทั้งระบบยังหมายความว่า 5.4 เป็น driver model สำหรับ agent ที่ดีกว่ามาก
- ชุด บันทึกการรับรองจากบริษัทชั้นนำในทุกอุตสาหกรรมที่น่าประทับใจที่สุดเท่าที่เคยเห็นในการเปิดตัวโมเดลใดๆ รวมถึงการจ้างบุคลากรสำคัญในสาย finance
- 5.4 Pro เปิดตัวในวันเดียวกับ 5.4 (ปกติ Pro จะเปิดตัวหลังจากนั้นหลายสัปดาห์)
- ผู้เขียนได้ทดลองใช้ 5.4 ในช่วง trial แล้วปล่อยทิ้งไว้ขณะกลับไปทำงาน "ปกติ"... และไม่ทันสังเกตเลยว่าไม่ได้คิดถึง Opus อีกเลย
น่าสนใจ
AI News ประจำวันที่ 4-5 มีนาคม 2569 ตรวจสอบ 12 subreddits, 544 Twitters และ 24 Discords (264 channels, 15,389 messages) ประหยัดเวลาอ่านโดยประมาณ (ที่ 200wpm): 1,568 นาที
GPT-5.4 Pro: ผสาน Coding & Reasoning, SOTA Computer Use
OpenAI ได้เปิดตัว GPT-5.4 Thinking และ GPT-5.4 Pro ทั้งบน ChatGPT, API และ Codex มาพร้อมจุดเด่นสำคัญหลายประการ:
- Native computer use (CUA) — เป็นความสามารถระดับ first-class ในโมเดลอเนกประสงค์ ถูกจัดให้เป็น SOTA สำหรับการใช้ tool/GUI
- Context สูงสุด ~1M token — ใน Codex/API (แม้ว่า long-context reliability จะยังลดลงในทางปฏิบัติ)
- ประสิทธิภาพ — "fewer tokens, faster speed" พร้อมเพิ่ม Codex /fast mode (เร็วขึ้น 1.5x ด้วย "priority processing")
- Steering mid-response — สามารถขัดจังหวะและเปลี่ยนทิศทางขณะโมเดลกำลังคิด ถูกเน้นว่าเป็นการปรับปรุง UX/control
เกณฑ์วัดประสิทธิภาพ: GPT-5.4 เหนือกว่ามนุษย์ใน OSWorld, สร้างสถิติใหม่ใน FrontierMath
- OSWorld-Verified — 75.0% สูงกว่า human baseline ที่ 72.4% (computer-use)
- SWE-Bench Pro — 57.7% พร้อมข้อสงสัยบางส่วนว่า "ดีกว่า Codex ก่อนหน้าเพียงเล็กน้อย"
- GDPval — 83% "win/tie vs industry professionals" กลายเป็นตัวเลขที่เป็นพาดหัว
- FrontierMath — Epoch รายงานว่า GPT-5.4 Pro ทำสถิติใหม่ (50% ใน Tiers 1-3; 38% ใน Tier 4) แต่แก้ได้ 0 "ปัญหาเปิด"
เสียงตอบรับจากผู้ใช้: ชื่นชม Coding แต่กังวลค่าใช้จ่าย Pro
ปฏิกิริยาของผู้ใช้แบ่งออกเป็นสองกลุ่มหลัก:
- กลุ่มผู้ใช้งานที่ตื่นเต้น "Daily driver สำหรับ coding" — โดยเฉพาะเรื่องการวางแผนและ "human feel" แต่มีข้อสังเกตซ้ำๆ เรื่อง premature task completion และความไม่ซื่อสัตย์เป็นครั้งคราวในโครงร่างควบคุม agent
- กลุ่มผู้ใช้งานที่ห่วงเรื่องต้นทุน/overthinking — มี datapoint ไวรัลหนึ่งที่อ้างว่าแค่พิมพ์ "Hi" ใน Pro มีค่าใช้จ่าย $80 (น่าจะเป็น pathological setting แต่ส่งผลต่อการรับรู้)
ระบบนิเวศ Devtool ขานรับ: Cursor, Perplexity, Arena ผนวก GPT-5.4 ทันที
- Cursor — ประกาศเพิ่ม GPT-5.4 ทันทีและอ้างว่าเป็นอันดับหนึ่งในการทดสอบภายใน
- Perplexity — เพิ่ม GPT-5.4 (tier Pro/Max)
- Arena — GPT-5.4 variants ถูกนำเข้า Text/Vision/Code arena เพื่อให้ crowd จัดอันดับ
FlashAttention-4: อัตรา Attention เทียบเท่า Matmul บน Blackwell
หนึ่งในไฮไลท์สำคัญจากฝั่งระบบคือ FlashAttention-4 (FA4) ซึ่งทำให้การประมวลผล attention มีปริมาณงานใกล้เคียงกับความเร็วของ matmul บน Blackwell ด้วยการย้ายคอขวดออกจาก softmax/shared memory ผ่านการเปลี่ยนแปลงทั้งอัลกอริทึมและไปป์ไลน์:
- Polynomial exp emulation — ประมาณ exponential function ด้วย polynomial
- Online softmax — ลดภาระการปรับขนาด (rescaling overhead)
- 2CTA MMA — ลดปริมาณทราฟฟิกของ shared memory
จากมุมมองทางวิศวกรรมและผลิตภาพ ถือเป็นเรื่องน่าสนใจที่ FA4 ถูกเขียนด้วย CuTeDSL ที่ฝังอยู่ใน Python ทำให้การติดตั้งและคอมไพล์ใช้เวลาเพียง "วินาทีแทนที่จะเป็นนาทีหรือชั่วโมง" นอกจากนี้ยังช่วยให้ AI assistant สามารถวนซ้ำและดีบักได้รวดเร็วขึ้นด้วยความเร็วในการคอมไพล์
PyTorch ได้ผนวกรวม FlashAttention-4 backend เข้ากับ FlexAttention ซึ่งจะสร้าง CuTeDSL score/mask mods โดยอัตโนมัติ และ JIT-instantiate FA4 สำหรับ attention variants ที่ปรับแต่งได้ โดยอ้างว่ามีความเร็วเพิ่มขึ้น 1.2x-3.2x เมื่อเทียบกับ Triton บนเวิร์กโหลดที่จำกัดด้วยการคำนวณ (compute-bound workloads)
OLMo Hybrid: Allen AI ผสาน Transformer-RNN แบบ Open-Source
Allen AI ได้เปิดตัว OLMo Hybrid โมเดล 7B แบบ fully open (base/SFT/DPO) ที่ผสมผสาน Transformer attention เข้ากับ linear RNN-style layers (เรียกว่า Gated DeltaNet) โดยอ้างว่ามีการปรับปรุงที่ชัดเจนเหนือ OLMo 3 7B ในการประเมินหลายด้าน
Lambda ได้เน้นย้ำถึงการฝึกโมเดลที่เปิดกว้างอย่างเต็มที่ (fully-open training run) โดยใช้ 3T tokens, 512 Blackwell GPUs, และใช้เวลา 7 วัน พร้อมเผยแพร่ logs/metrics/weights ที่แสดงถึง 97% active training time และการกู้คืนที่รวดเร็ว
ความสำคัญต่อนักวิศวกร: การเปิดตัวนี้ถูกวางให้เป็นจุดอ้างอิงสำหรับศึกษาการเปลี่ยนแปลงสถาปัตยกรรมแบบ end-to-end (pretraining + post-training + tooling) โดยเฉพาะในสถานการณ์ที่สถาปัตยกรรมใหม่อาจยังขาดการสนับสนุนโครงสร้างพื้นฐานแบบ open-source
Databricks เปิดตัว KARL: Agent เทรนด้วย RL เพื่อ Grounded Reasoning แทน RAG
Databricks ได้ประกาศเปิดตัว KARL (Knowledge Agent via Reinforcement Learning) ซึ่งเป็นเอเจนต์ที่ถูกฝึกฝนด้วยเทคนิค Reinforcement Learning (RL) เพื่อการทำ document-centric / grounded reasoning โดยเน้นขั้นตอนการทำงานระดับองค์กรที่เกี่ยวข้องกับการค้นคืนข้อมูลแบบหลายขั้นตอน, การอ้างอิงข้ามเอกสาร และการใช้เครื่องมือที่ซับซ้อน (long tool trajectories)
ข้อเรียกร้องทางเทคนิคที่สำคัญ:
- RL สามารถปรับปรุงได้มากกว่าแค่ "sharpening" — สามารถถ่ายทอดความรู้ไปยัง unseen prompts ได้ รวมถึงกรณีที่โมเดลพื้นฐานมีค่า accuracy เป็น 0 แม้จะใช้ pass@16 ก็ตาม
- Multi-task RL มีความสามารถในการสรุป (generalize) และเอาชนะ multi-expert distillation ได้ — การใช้ end-to-end RL สำหรับการใช้เครื่องมือและการจัดการบริบท (vector DB + compression) มีความสำคัญอย่างยิ่ง
- "คุณภาพเทียบเท่า Sonnet แต่ใช้ต้นทุนเพียงเศษเสี้ยว และสามารถปรับขนาดเมื่อทดสอบได้ถึงระดับที่สูงกว่า"
แก่นหลัก: อุตสาหกรรมกำลังเปลี่ยนผ่านจากแนวคิด "RAG++" ไปสู่ grounded reasoning ในฐานะแนวคิดนามธรรมระดับองค์กรที่ยั่งยืน
Cursor เปิดตัว Automations: Agent ทำงานเบื้องหลัง ไม่ต้องเปิดแล็ปท็อป
Cursor ได้เปิดตัว always-on agents ที่ทำงานโดยถูกกระตุ้นจาก events/webhooks ซึ่งถือเป็นการเปลี่ยนผ่านจาก interactive copilots ไปสู่ continuous background engineering
ตัวอย่างการใช้งานที่เห็นได้ชัด:
- CI-fix agents, การประเมินความเสี่ยง PR และการอนุมัติอัตโนมัติ
- การตอบสนองต่อเหตุการณ์ผ่าน Datadog MCP, การตรวจสอบบันทึกผ่าน Notion MCP
- Cloud-owned automations ที่ช่วยขจัดข้อจำกัดเรื่อง "ต้องเปิดแล็ปท็อป"
การประเมินทักษะกลายเป็นสิ่งจำเป็น: มีสูตรปฏิบัติสำหรับการทดสอบ "ทักษะ" ของ agent ซึ่งประกอบด้วยเกณฑ์ความสำเร็จ, 10-12 prompts พร้อมการตรวจสอบแบบกำหนดค่าได้ (deterministic checks), และ LLM-as-judge สำหรับการตรวจสอบเชิงคุณภาพ LangChain ได้เผยแพร่ชุดทักษะมาตรฐานที่ใช้ทดสอบและผลลัพธ์ที่ได้ — พบว่า ความผันผวนข้ามงานนั้นสูง และ action space ที่ใหญ่ทำให้การประเมินแบบ "vibes" ไม่น่าเชื่อถือ
ขั้นตอนการทำงานของ agent ที่ทนทาน: LlamaIndex เน้นการผสานรวมกับ DBOS เพื่อให้ขั้นตอนการทำงานสามารถอยู่รอดจากการขัดข้อง/รีสตาร์ท ด้วยการคงสถานะและการกลับมาทำงานอัตโนมัติ
1M Context: ตัวเลขสวย แต่ความแม่นยำจริงลดฮวบที่ 36% ในช่วง 512K-1M
คำว่า "1M context" ไม่ได้หมายถึง "1M ที่ใช้งานได้จริง" — นี่คือผลลัพธ์จาก MRCR v2 needle-in-haystack ของ OpenAI เอง:
- ~97% ที่ 16-32K
- 57% ที่ 256-512K
- 36% ที่ 512K-1M
มีการแนะนำให้ใช้ compaction เป็นประจำ และหลายโพสต์พูดถึง "context rot" และ soft ceilings ที่ใช้งานได้จริงจะอยู่ประมาณ ~256K
การบีบอัด KV-cache: Baseten ได้สรุปงานวิจัยเรื่อง repeated KV compression ("Attention Matching") เพื่อใช้งานกับ long-running agents — การบีบอัดแบบ one-shot สามารถคงความแม่นยำไว้ได้ 65-80% ที่อัตราการบีบอัด 2-5 เท่า ซึ่งถือว่าดีกว่าการสรุปข้อความมาก
การเรียนรู้ต่อเนื่องเทียบกับเครื่องมือจัดการหน่วยความจำ: Awni Hannun ได้กล่าวถึง prompt compaction + recursive sub-agents ว่ามีประสิทธิภาพอย่างน่าประหลาดใจ แต่ก็เสนอแนวทางด้าน memory-based retention/eviction policies และสำรวจการทำ online fine-tuning ด้วย LoRA — ซึ่งพบว่ายากที่จะหลีกเลี่ยง "brain damage"/capability loss
Karpathy ก็เสนอแนวคิดในทำนองเดียวกัน — ให้มองการทำงานเกี่ยวกับหน่วยความจำว่าเป็นเครื่องมือ (tools) และปรับปรุงให้มีประสิทธิภาพผ่าน RL รวมถึงบอกใบ้ว่า การอัปเดตน้ำหนัก (weight-updating) สำหรับหน่วยความจำระยะยาวอาจจำเป็นต่อการสร้าง persistent agents ที่แท้จริง
Opus 4.6 ไขปริศนาคณิตศาสตร์ Knuth: AI ลองผิดลองถูกรวดเร็ว!
Opus 4.6 สามารถแก้ข้อคาดการณ์ข้อหนึ่งของ Donald Knuth ที่ค้างคามานานตั้งแต่การเขียน "The Art of Computer Programming" ซึ่งทำให้ Knuth ถึงกับแสดงความตื่นเต้นอย่างมาก
ในเอกสารของ Knuth ชื่อ "Claude's Cycles" ได้กล่าวถึงความก้าวหน้าครั้งสำคัญที่ Claude Opus 4.6 ทำได้ นั่นคือ AI สามารถแก้ข้อคาดการณ์ที่มีมายาวนานเกี่ยวกับการแยก arcs ออกเป็น directed cycles ใน digraph ที่มี m³ vertices ซึ่งเป็นปัญหาที่ Knuth ได้ศึกษามาอย่างต่อเนื่อง
Claude ไม่จำเป็นต้องฉลาดกว่านักคณิตศาสตร์ทั่วไป แต่มีความโดดเด่นในการทดลองวิธีการจำนวนมากอย่างรวดเร็ว ความสามารถนี้ทำให้สามารถแก้ข้อคาดการณ์ได้สำหรับ m ที่เป็นเลขคี่ และยังหาคำตอบสำหรับ m ที่เป็นเลขคู่บางค่าได้ — ซึ่งเน้นย้ำถึงจุดแข็งในด้าน ความเร็วเชิงคำนวณและความหลากหลายในการทดลอง มากกว่าความเข้าใจเชิงคณิตศาสตร์ที่เหนือกว่า